【pytorch】加载数据、TensorBoard、Transforms
文章目录
-
- 一、用pytorch加载数据
-
- (1)两个类
- (2)训练数据集的组织形式:
- (3)Dataset代码实战——数据集的读取
- 二、TensorBoard的使用
-
- (1)add_scalar()的使用(常用来绘制train/val loss)
- (2)add_image()的使用(常用来观察训练结果)
- 三、Transforms的使用
-
- (1)从ToTensor类初识Transform"工具箱"
- (2)常见的transforms使用示例
-
- 1.ToTensor
- 2.Normalize
- 3.Resize
- 4.Compose
- 5.RandomCrop
一、用pytorch加载数据
(1)两个类
读取数据: D a t a s e t Dataset Dataset和 D a t a l o a d e r Dataloader Dataloader
| Dataset | Dataloader |
|---|---|
| 提供一种方式去获取数据及其label | 为网络提供不同的数据形式 |
| 如何获取每一个数据及其label;告诉我们总共有多少的数据 |
(2)训练数据集的组织形式:
-
文件夹的名称就是样本所对应的label
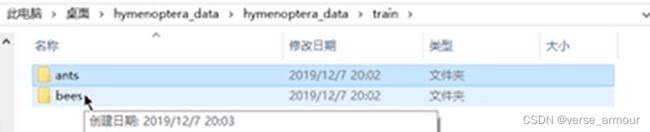
-
一个文件夹放训练数据集的名称;另一个文件夹放训练数据集的label。
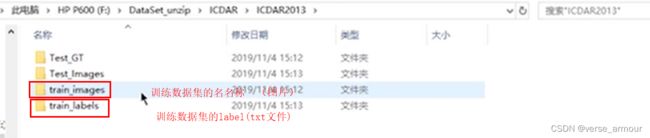
-
直接用图片的名称作为label
(3)Dataset代码实战——数据集的读取
from torch.utils.data import Dataset
from PIL import Image
import os
##os库:python中一个关于操作系统(operating system)的库,这里用这个库获取图片路径
class Mydata(Dataset):
##为整个class提供全局变量
def __init__(self,root_dir,label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir,self.label_dir)
self.img_path = os.listdir(self.path)
##listdir()返回指定目录下的文件名称列表,所以要得到列表下特定的图片要对self.img_path索引,因此方法__getitem__需要传入索引:idx
##获取图片的方法,此处用的是Image包获取图片
def __getitem__(self,idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name)
##一个文件路径的构成:root_dir,label_dir,img_name.
img = Image.open(img_item_path)
label = self.label_dir
return img,label##返回值是一个元组,如果调用img或label要索引
def __len__(self):
return len(self.img_path)
root_dir = "hymenoptera_data/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ant_dataset = Mydata(root_dir,ants_label_dir)
bees_dataset = Mydata(root_dir,bees_label_dir)
img = ant_dataset.__getitem__(5)[0]
#5是图片的索引,0是元组(img,label)的索引,如果是0则返回一个img,用img.show()显示;
#如果是1则返回一个label,用print显示标签。
有的时候训练数据集的样本数量不够,可以用真实数据集+人工仿造的数据集充当训练集,以此填补训练集样本不够的情况。两个数据集的组合可以直接用+号连接。
二、TensorBoard的使用
文档:https://cloud.tencent.com/developer/article/1955304
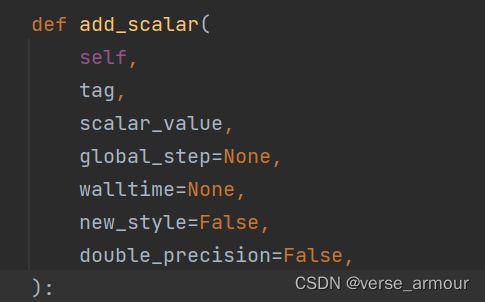
(1)add_scalar()的使用(常用来绘制train/val loss)
from torch.utils.tensorboard import SummaryWriter
# from torch.utils.tensorboard.writer import SummaryWriter
writer = SummaryWriter("logs")
# writer.add_image()
# y = x
for i in range(100):
writer.add_scalar("y=2x",3*i,i)
writer.close()
运行以上代码,在logs目录下生成事件
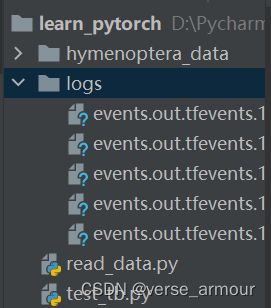
在Terminal窗口中输入如下指令:
tensorboard --logdir=logs

点击网址,进入用浏览器查看网页:
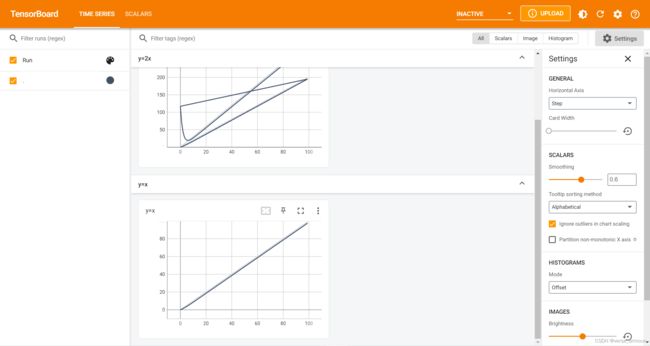
如果title是 y = 2 x y=2x y=2x,但tag值是 3 ∗ i 3*i 3∗i,scalar_value值是 i i i,即:
writer.add_scalar("y=2x",3*i,i)
会出现如下情况:
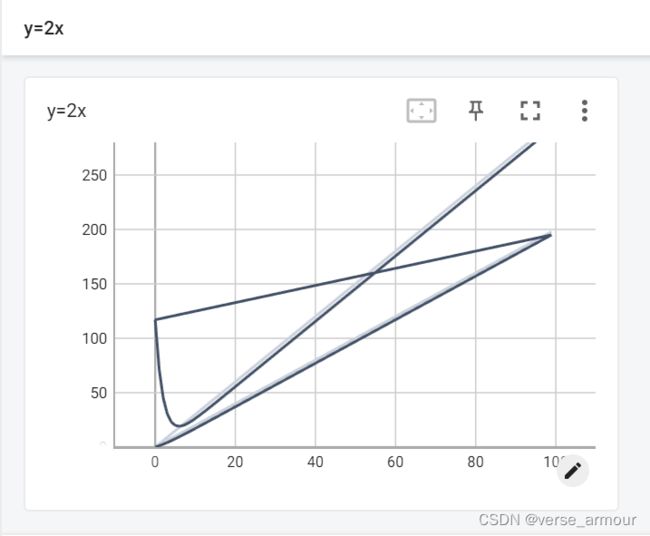
这张图上既有 y = 2 x y=2x y=2x也有 y = 3 x y=3x y=3x,并且在 y = 2 x y=2x y=2x和 y = 3 x y=3x y=3x之间存在一个过渡部分。这是因为我们用add_scalar向writer中写入新的事件时,新事件和上一个事件的tag相同,所以两个事件被记录在了一张图上。
解决:出现这种情况,我们只需要将之前生成的事件全部删除,仅运行一次新事件的代码文件,生成一个新事件,再在Terminal中执行tensorboard --logdir=logs命令即可。
(2)add_image()的使用(常用来观察训练结果)
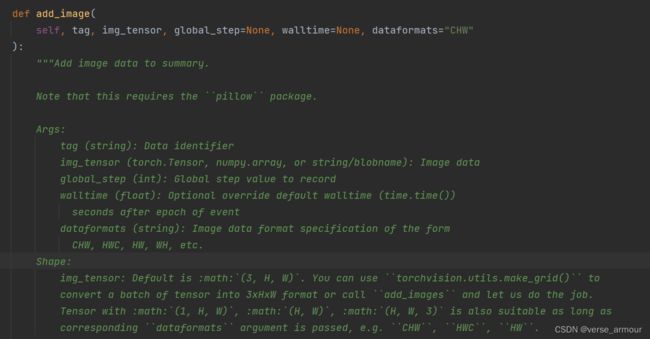
解析:
- img_tensor(图像张量)的格式:torch.Tensor,numpy.array
什么是torch.Tensor,numpy.array?
二者都可以定义多维数组,进行切片、改变维度、数学运算等。
参考文档:
PyTorch中torch.tensor与torch.Tensor的区别
| numpy | Tensor |
|---|---|
| Python中数据分析的专业第三方库 | PyTorch中类似于numpy的库;神经网络界的numpy |
| 1、产生的数组类型为numpy.ndarray; 2、会将ndarray放入CPU中进行运算; 3、导入方式为import numpy as np,后续通过np.array([1,2])建立数组; 4、numpy中没有x.type()的用法,只能使用type(x)。 |
1、产生的数组类型为torch.Tensor; 2、会将tensor放入GPU中进行加速运算(如果有GPU); 3、导入方式为import torch,后续通过torch.tensor([1,2])或torch.Tensor([1,2])建立数组; 4、Tensor中查看数组类型既可以使用type(x),也可以使用x.type()。但是更加推荐采用x.type()。 |
Tensor中推荐使用x.type()是因为x.type()的输出结果为’torch.LongTensor’或’torch.FloatTensor’,可以看出两个数组的种类区别。而采用type(x),则清一色的输出结果都是torch.Tensor,无法体现类型区别。
- 用PIL库中的Image.open()函数读取图片
from PIL import Image
img = Image.open(image_path)
print(type(img))
<class 'PIL.JpegImagePlugin.JpegImageFile'>
用这种方法显然读取图片的格式不符合要求
需要用numpy库转化
writer = SummaryWriter("logs")
img_path = "train/ants_image/0013035.jpg"
img_PIL = Image.open(img_path)
img_array = np.array(img_PIL)
print(img_array.shape)
(512, 768, 3)
writer.add_image("test",img_array,1)
# y = x
for i in range(100):
writer.add_scalar("y=3x",3*i,i)
writer.close()
TypeError: Cannot handle this data type: (1, 1, 512), |u1
注:此时img_array的shape是(512, 768, 3),即(H, W, 3) ,但是官方文档指出默认的shape是(3,H,W),此处需要转换——传递对应的"dataformats"参数。从PIL到numpy,需要在add_image()中指定shape中每一个数字/维表示的含义。
官方文档: Shape:
img_tensor: Default is :math:(3, H, W). You can usetorchvision.utils.make_grid()to convert a batch of tensor into 3xHxW format or calladd_imagesand let us do the job. Tensor with :math:(1, H, W), :math:(H, W), :math:(H, W, 3)is also suitable as long as correspondingdataformatsargument is passed, e.g.CHW,HWC,HW.
默认为(3,H,W),张量:math: ’ (1, H, W) ',:math: ’ (H, W) ',:math: ’ (H, W, 3) '也适用,只要传递对应的"dataformats "参数
from torch.utils.tensorboard import SummaryWriter
# from torch.utils.tensorboard.writer import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs")
img_path = "train/ants_image/0013035.jpg"
img_PIL = Image.open(img_path)
img_array = np.array(img_PIL)
print(img_array.shape)
writer.add_image("test",img_array,1,dataformats="HWC")
# y = x
for i in range(100):
writer.add_scalar("y=3x",3*i,i)
writer.close()
- 用OpenCV读取(按BGR读取数据)
import cv2
img = cv2.imread(image_path)
print(type(img))
<class 'numpy.ndarray'>
由于openCV使用BGR读取的是数据,要记得将数据转换成RGB:
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
或者:
OpenCV读取的图片从BGR转换为RGB

示例代码:
from torch.utils.tensorboard import SummaryWriter
import numpy as np
img = np.zeros((3, 100, 100))
img[0] = np.arange(0, 10000).reshape(100, 100) / 10000
img[1] = 1 - np.arange(0, 10000).reshape(100, 100) / 10000
img_HWC = np.zeros((100, 100, 3))
img_HWC[:, :, 0] = np.arange(0, 10000).reshape(100, 100) / 10000
img_HWC[:, :, 1] = 1 - np.arange(0, 10000).reshape(100, 100) / 10000
writer = SummaryWriter()
writer.add_image('my_image', img, 0)
# If you have non-default dimension setting, set the dataformats argument.
writer.add_image('my_image_HWC', img_HWC, 0, dataformats='HWC')
writer.close()
三、Transforms的使用
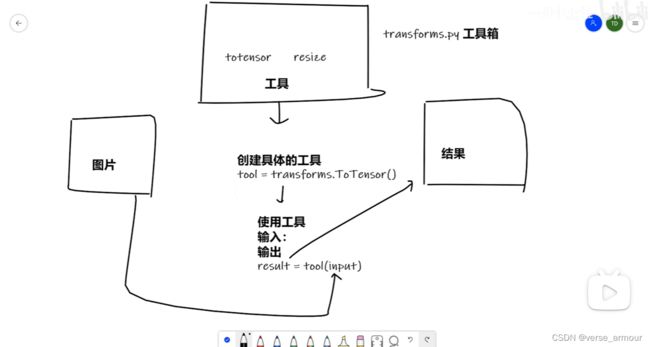
(1)从ToTensor类初识Transform"工具箱"
from torchvision import transforms
from PIL import Image
img_path = "train/ants_image/0013035.jpg"
img = Image.open(img_path)
#引用了transforms中的ToTensor,返回的是一个ToTensor的对象
tensor_trans = transforms.ToTensor()
#调用transforms中的ToTensor工具。
# 此处tensor_trans即一个ToTensor的对象(实例化,可以对tensor_trans直接引用ToTensor中的方法)
img_tensor = tensor_trans(img)#call方法的特殊用法
print(img_tensor)
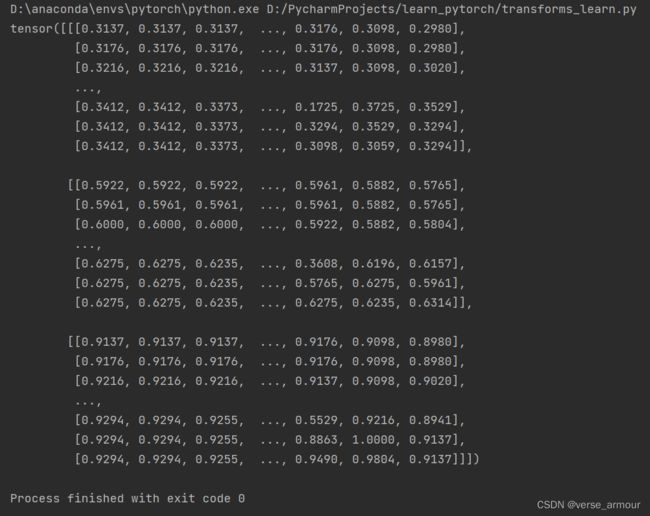
内置__call__方法:
class ToTensor:
"""Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor. This transform does not support torchscript.
Converts a PIL Image or numpy.ndarray (H x W x C) in the range
[0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0]
if the PIL Image belongs to one of the modes (L, LA, P, I, F, RGB, YCbCr, RGBA, CMYK, 1)
or if the numpy.ndarray has dtype = np.uint8
In the other cases, tensors are returned without scaling.
.. note::
Because the input image is scaled to [0.0, 1.0], this transformation should not be used when
transforming target image masks. See the `references`_ for implementing the transforms for image masks.
.. _references: https://github.com/pytorch/vision/tree/main/references/segmentation
"""
def __init__(self) -> None:
_log_api_usage_once(self)
def __call__(self, pic):
"""
Args:
pic (PIL Image or numpy.ndarray): Image to be converted to tensor.
Returns:
Tensor: Converted image.
"""
return F.to_tensor(pic)
def __repr__(self) -> str:
return f"{self.__class__.__name__}()"
img_tensor = tensor_trans(img)
img_tensor = tensor_trans.__call__(img)
这两种写法效果是一样的。 这是因为call方法的特殊性,它可以使实例对象变得像函数一样加()进行调用,魔法方法,满足条件自动调用。
class B:
print("666")
print(callable(B)) #True
def A():
print("555")
print(callable(A)) #True
b=B()
print(callable(b)) #False
class B:
def __init__(self):
pass
def __call__(self):
print("666")
print(callable(B)) #True
def A():
print("555")
print(callable(A)) #True
b=B()
print(callable(b)) #True
(2)常见的transforms使用示例
多看官方文档:Ctrl+鼠标左键,可以查看官方文档
在官方文档中,关注输入和输出类型、方法所需要的参数
关注方法的返回值类型
当官方文档中没有直接说明返回值类型时:
- print()
- print(type())
- debug(断点调试)
from torchvision import transforms
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
img_path = "train/ants_image/0013035.jpg"
img = Image.open(img_path)
writer = SummaryWriter("logs")
1.ToTensor
#ToTensor
#引用了transforms中的ToTensor,返回的是一个ToTensor的对象
tensor_trans = transforms.ToTensor()
#调用transforms中的ToTensor工具。
# 此处tensor_trans即一个ToTensor的对象(实例化,可以对tensor_trans直接引用ToTensor中的方法)
img_tensor = tensor_trans(img)
# img_tensor = tensor_trans.__call__(img)
writer.add_image("img_tensor",img_tensor)
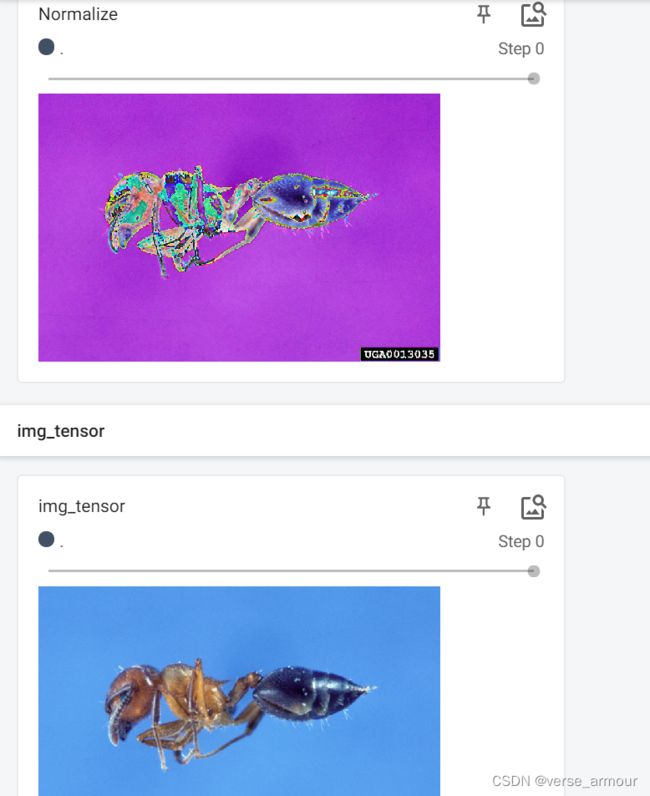
2.Normalize
#Normalize(归一化/标准化)
#args:
#mean (sequence): Sequence of means for each channel.每个信道平均值的序列
#std (sequence): Sequence of standard deviations for each channel.每个信道标准差的序列
print(img_tensor[0][0][0])#输出第一个信道,第一行第一列的值
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])#RGB信道
img_norm = trans_norm(img_tensor)
print(img_tensor[0][0][0])#归一化之后第一个信道,第一行第一列的值
writer.add_image("Normalize",img_norm)#此处为什么没有__call__方法依然可以用()调用实例对象??可能是因为调用了父类torch.nn.Module中的__call__方法
3.Resize
#Resize(等比缩放)
print(img.size)
trans_resize = transforms.Resize((512,512))#图像大小等比缩放为512px*512px,返回的是一个resize的对象(实例)
img_resize = trans_resize(img)#像调用函数那样向一个实例传参,transforms库更新了,resize的参数既能是PIL类型也可以是tensor类型
img_resize = tensor_trans(img_resize)#调用tensor_trans实例:PIL->tensor
writer.add_image("Resize",img_resize,0)
print(img_resize)
4.Compose
#Compose(不改变长和宽的比例)由几个transform组合而成
#Compose()中的参数需要一个列表,数据需要transforms对象类型
trans_resize_2 = transforms.Resize(512)#等比缩放
trans_compose = transforms.Compose([tensor_trans,trans_resize_2])
img_resize_2 = trans_compose(img)
writer.add_image("Compose",img_resize_2,1)
5.RandomCrop
#RandomCrop(随机裁剪)
trans_random = transforms.RandomCrop(500,1000)
trans_compose_2 = transforms.Compose([trans_random,tensor_trans])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop",img_crop,i)
writer.close()