机器学习中的特征提取
特征提取是将任意数据(如文本或图像)转换为可用于机器学习的数字特征,特征提取是为了计算机更好的去理解数据。
特征提取大体上可以分为三大类:
- 字典特征提取(特征离散化)
- 文本特征提取
- 图像特征提取(深度学习)
本篇文章中我们只讨论前两种特征提取方法。
一、字典特征提取
作用:对字典数据进行特征值化。
API
sklearn.feature_extraction.DictVectorizer(sparse=True,…)
- DictVectorizer.fit_transform(X)
- X:字典或者包含字典的迭代器返回值
- 返回sparse矩阵
- DictVectorizer.get_feature_names() 返回类别名称
实例
现在有一组词典如下,现在要对其进行特征提取。
data = [{"算法工程师": 10000}, {"前端": 8000}, {"数据库工程师": 8500}, {"数据分析": 9000}, {"架构师": 15000}]
from sklearn.feature_extraction import DictVectorizer
def dict_f():
"""
对字典类型的数据进行特征抽取
"""
# 获取数据
data = [{"job": "算法工程师","salary": 10000}, {"job": "前端", "salary": 8000},
{"job": "数据库工程师", "salary": 8500}, {"job": "数据分析", "salary": 9500},
{"job": "架构师", "salary": 15000}]
# 实例化字典特征提取对象
transfer = DictVectorizer(sparse=False)
# 特征提取
new_data = transfer.fit_transform(data)
new_data = new_data.astype(int)
print(type(new_data))
print(transfer.feature_names_)
print("提取后的特征:\n", new_data)
dict_f()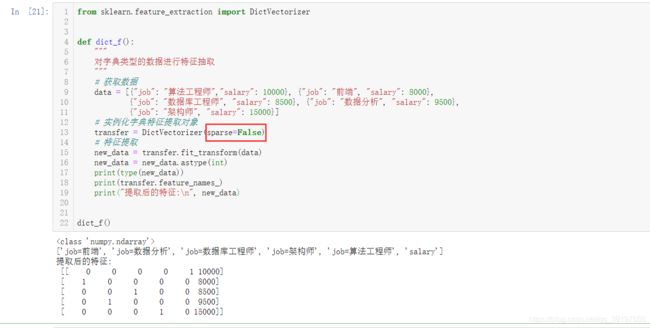
from sklearn.feature_extraction import DictVectorizer
def dict_f():
"""
对字典类型的数据进行特征抽取
"""
# 获取数据
data = [{"job": "算法工程师","salary": 10000}, {"job": "前端", "salary": 8000},
{"job": "数据库工程师", "salary": 8500}, {"job": "数据分析", "salary": 9500},
{"job": "架构师", "salary": 15000}]
# 实例化字典特征提取对象
transfer = DictVectorizer(sparse=True)
# 特征提取
new_data = transfer.fit_transform(data)
new_data = new_data.astype(int)
print(type(new_data))
print(transfer.feature_names_)
print("提取后的特征:\n", new_data)
dict_f()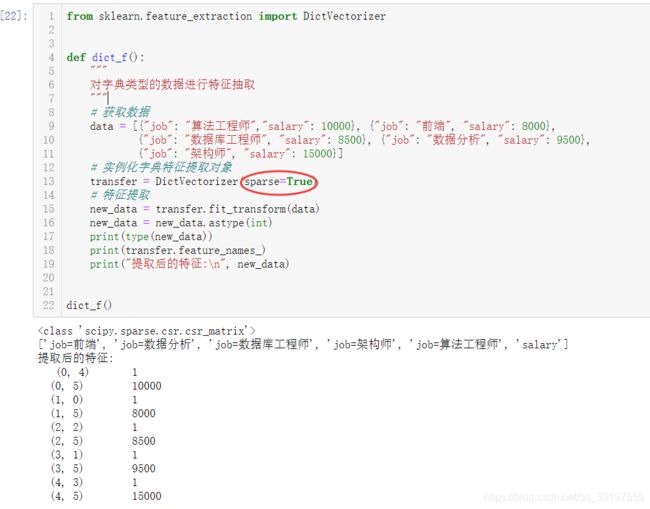
对比一下特征提取对象中的sparse参数取False和True情况,我们可以看出这两者的区别。当sparse=True时,返回的是稀疏矩阵,稀疏矩阵的存储相对节省内存。sparse=False的返回类型类似于one-hot编码的数据结构,只不过是float类型,经过类型转换之后看的比较舒服
二、文本特征提取
作用:对文本数据进行特征值化
API
-
sklearn.feature_extraction.text.CountVectorizer(stop_words=[])
- 返回词频矩阵
- CountVectorizer.fit_transform(X)
- X:文本或者包含文本字符串的可迭代对象
- 返回值:返回sparse矩阵
- CountVectorizer.get_feature_names() 返回值:单词列表
-
sklearn.feature_extraction.text.TfidfVectorizer
英文案例
from sklearn.feature_extraction.text import CountVectorizer
def english_CountVectorizer_f():
"""
对字典类型的数据进行特征抽取
"""
# 获取数据
data = ["There are moments in life when you miss someone so much that you just want to pick them from your dreams and hug them for real! Dream what you want to dream;go where you want to go;be what you want to be,because you have only one life and one chance to do all the things you want to do."]
# 实例化
transfer = CountVectorizer()
# 特征提取
new_data = transfer.fit_transform(data)
print("特征名称:",transfer.get_feature_names())
print("提取后的特征:\n", new_data)
english_CountVectorizer_f()
中文案例
from sklearn.feature_extraction.text import CountVectorizer
# jieba 是一个中文的分词工具
import jieba
def cut_word(text):
"""
对中文进行分词
"""
text = " ".join(list(jieba.cut(text)))
return text
def chinese_CountVectorizer_f():
"""
对字典类型的数据进行特征抽取
"""
# 获取数据
data = ['人生永没有终点。”只有等到你瞑目的那一刻,才能说你走完了人生路,在此之前,新的第一次始终有,新的挑战依然在,新的感悟不断涌现',
'母爱是一种无私的感情,母爱像温暖的阳光,洒落在我们心田,虽然悄声无息,但它让一棵棵生命的幼苗感受到了雨后的温暖。']
text_list = []
for sent in data:
text_list.append(cut_word(sent))
print(text_list)
# 实例化文本特征提取对象
transfer = CountVectorizer()
# 特征提取
new_data = transfer.fit_transform(text_list)
print("特征名称:",transfer.get_feature_names())
print("提取后的特征:\n", new_data)
chinese_CountVectorizer_f()
三、Tf-idf文本特征提取
- F-IDF的主要思想是:如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
- TF-IDF作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
公式
- 词频(term frequency,tf)指的是某一个给定的词语在该文件中出现的频率
- 逆向文档频率(inverse document frequency,idf)是一个词语普遍重要性的度量。某一特定词语的idf,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到
![]()
举例:
假如一篇文章的总词语数是100个,而词语"非常"出现了5次,那么"非常"一词在该文件中的词频就是5/100=0.05。
而计算文件频率(IDF)的方法是以文件集的文件总数,除以出现"非常"一词的文件数。
所以,如果"非常"一词在1,0000份文件出现过,而文件总数是10,000,000份的话,
其逆向文件频率就是lg(10,000,000 / 1,0000)=3。
最后"非常"对于这篇文档的tf-idf的分数为0.05 * 3=0.15案例
from sklearn.feature_extraction.text import TfidfVectorizer
import jieba
def cut_word(text):
"""
对中文进行分词
"我爱北京天安门"————>"我 爱 北京 天安门"
:param text:
:return: text
"""
# 用结巴对中文字符串进行分词
text = " ".join(list(jieba.cut(text)))
return text
def text_chinese_tfidf_demo():
"""
对中文进行特征抽取
:return: None
"""
data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。",
"我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]
# 将原始数据转换成分好词的形式
text_list = []
for sent in data:
text_list.append(cut_word(sent))
print(text_list)
# 1、实例化一个转换器类
# transfer = CountVectorizer(sparse=False)
transfer = TfidfVectorizer(stop_words=['一种', '不会', '不要'])
# 2、调用fit_transform
data = transfer.fit_transform(text_list)
print("文本特征抽取的结果:\n", data.toarray())
print("返回特征名字:\n", transfer.get_feature_names())
return None返回结果:
['一种 还是 一种 今天 很 残酷 , 明天 更 残酷 , 后天 很 美好 , 但 绝对 大部分 是 死 在 明天 晚上 , 所以 每个 人 不要 放弃 今天 。', '我们 看到 的 从 很 远 星系 来 的 光是在 几百万年 之前 发出 的 , 这样 当 我们 看到 宇宙 时 , 我们 是 在 看 它 的 过去 。', '如果 只用 一种 方式 了解 某样 事物 , 你 就 不会 真正 了解 它 。 了解 事物 真正 含义 的 秘密 取决于 如何 将 其 与 我们 所 了解 的 事物 相 联系 。']
文本特征抽取的结果:
[[ 0. 0. 0. 0.43643578 0. 0. 0.
0. 0. 0.21821789 0. 0.21821789 0. 0.
0. 0. 0.21821789 0.21821789 0. 0.43643578
0. 0.21821789 0. 0.43643578 0.21821789 0. 0.
0. 0.21821789 0.21821789 0. 0. 0.21821789
0. ]
[ 0.2410822 0. 0. 0. 0.2410822 0.2410822
0.2410822 0. 0. 0. 0. 0. 0.
0. 0.2410822 0.55004769 0. 0. 0. 0.
0.2410822 0. 0. 0. 0. 0.48216441
0. 0. 0. 0. 0. 0.2410822
0. 0.2410822 ]
[ 0. 0.644003 0.48300225 0. 0. 0. 0.
0.16100075 0.16100075 0. 0.16100075 0. 0.16100075
0.16100075 0. 0.12244522 0. 0. 0.16100075
0. 0. 0. 0.16100075 0. 0. 0.
0.3220015 0.16100075 0. 0. 0.16100075 0. 0.
0. ]]
返回特征名字:
['之前', '了解', '事物', '今天', '光是在', '几百万年', '发出', '取决于', '只用', '后天', '含义', '大部分', '如何', '如果', '宇宙', '我们', '所以', '放弃', '方式', '明天', '星系', '晚上', '某样', '残酷', '每个', '看到', '真正', '秘密', '绝对', '美好', '联系', '过去', '还是', '这样']