机器学习基础:神经网络——感知机
目录
1. 表示学习
2. 生物神经元 V.S. 人造神经元
3. 感知机
3.1 训练感知机
3.2 激活函数
3.3 一层感知机
3.4 多层感知机
3.4.1 隐藏层神经元数量选择
3.4.2 隐藏层如何学习参数
3.4.3 多层感知机的性质
3.4.4 多层感知机总结
1. 表示学习
表示学习(representation Learning)是神经网络的一个常见应用:
表示学习的基本思路,是找到对于原始数据更好的表达,以方便后续任务(比如分类)。机器学习中,同样的数据的不同表达,会直接决定后续任务的难易程度(换言之,表示方法的选择通常依赖于后续任务的需求),因此找到好的数据表示往往是机器学习的核心任务。
例如图像相关的任务,数据的特征维度太高(通常在几十万上百万的维度,因为图像的每个像素点都是一个特征)。
深度学习中常用![]() 来对高维度数据进行处理,将其重新编码成维度较低的特征。
来对高维度数据进行处理,将其重新编码成维度较低的特征。
深度网络可以通过学习![]() 后的特征来完成各种任务。
后的特征来完成各种任务。
2. 生物神经元 V.S. 人造神经元
首先梦回高中生物——神经元:
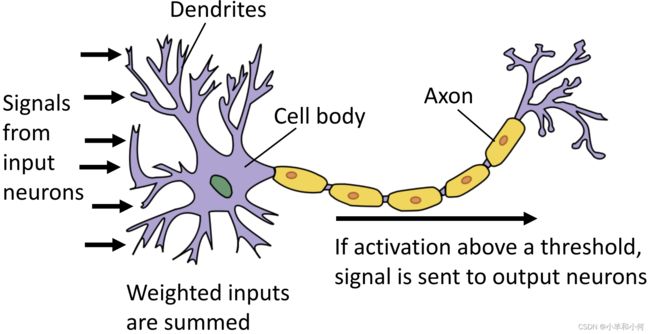
输入信号,输出信号,各方输入信号加权取平均,如果超过某一个阈值就将信号传向下一个神经元

![]() 代表各方的输入组成的输入向量,
代表各方的输入组成的输入向量, 是常数偏置项
是常数偏置项 ,对这些量进行加权求和(参数的权重同样是一个向量
,对这些量进行加权求和(参数的权重同样是一个向量![]() )然后通过一个激活函数
)然后通过一个激活函数![]() 这也是个可选的超参数,可以为神经元选用不同的激活函数,激活后的值是一个标量
这也是个可选的超参数,可以为神经元选用不同的激活函数,激活后的值是一个标量![]() 继续传入下一个神经元;
继续传入下一个神经元;
这个过程中的超参数是 激活函数,需要学习的参数是
激活函数,需要学习的参数是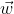 和
和![]()
形式化的数学表示为:
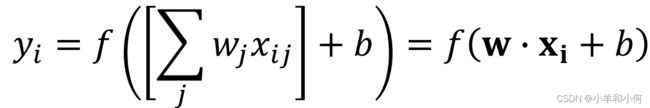
3. 感知机
感知机(Perceptron):
- 感知机本质上就是只有单个神经元的神经网络
- 一个感知机就是一个二元的线性分类器,形式化表示如下:
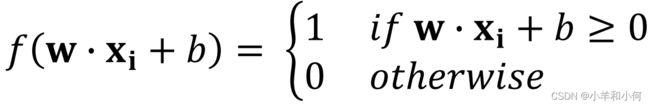
这里的阈值是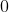 ,也就是说只要
,也就是说只要![]() 的加权和
的加权和![]() 那么感知机就输出
那么感知机就输出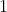 。
。
3.1 训练感知机
训练感知机(Training Perceptron)是试图求算最佳的参数向量最小化训练误差
常用的方法是通过迭代(Iterative)的方式对训练集上进行反复训练。具体的算法可以如下表示:

基本思想是:
- 对于每一个训练样本
,得到它的预测值和实际值之间的误差。并通过这个误差和优化算法来更新所有的需要求算的参数
。
- 因为每个样本
的特征维度是
因此,整个模型一共会有
- 参数迭代的方式是梯度下降,图中使用的损失函数是:
,因此它的梯度是图中下标红线的部分。
是学习率,是所有参数共有的控制梯度下降速度的参数,对于每个
- 在红线下标的式子的最后一项
是这个特征自身的值,如果
是个负数,那么
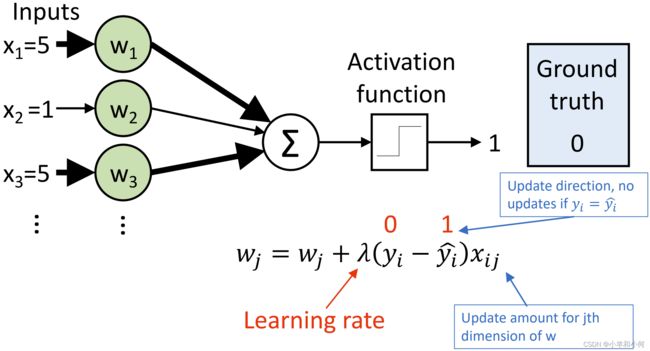
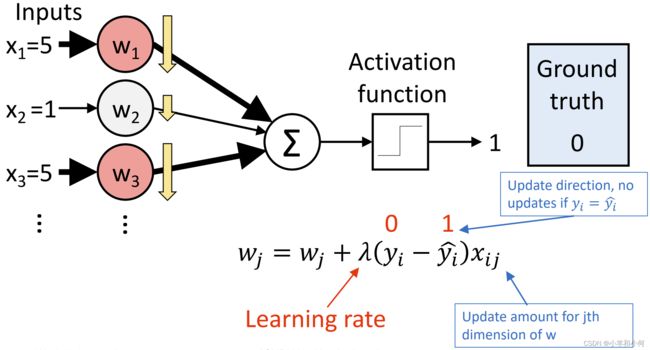
这里的每个![]() 应该写成
应该写成![]() ,也就是表示的特征的值,而不是样本的值。
,也就是表示的特征的值,而不是样本的值。
根据计算,![]() 下降的幅度比
下降的幅度比 大很多,因为他们的特征值比较大
大很多,因为他们的特征值比较大
下面给出一个梯度更新的动态例子:
一共有四个训练样本![]() ,每个训练样本的特征数量是
,每个训练样本的特征数量是![]() 两个。
两个。
计算![]() 的公式在左下角,通过参数,样本向量的加权求和和激活函数得到。
的公式在左下角,通过参数,样本向量的加权求和和激活函数得到。
根据![]() 我们可以计算出误差,并通过梯度下降公式来计算每个特征的参数应该如何更新。
我们可以计算出误差,并通过梯度下降公式来计算每个特征的参数应该如何更新。
对于偏置,我们始终把它看成是参数向量中的第一个参数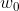 ,统一进行梯度更新求算;我们规定
,统一进行梯度更新求算;我们规定![]() 始终为。
始终为。
在进行迭代之前需要给出一个初始化的参数向量,即![]()
第一个![]() 中:
中:

前两个样本的预测值和实际值相同,因此不需要梯度更新。第三个样本产生了误差,因此根据梯度更新公式,参数的值被更新成![]() 。根据更新后的参数我们计算最后一个样本,发现没有误差,第一个
。根据更新后的参数我们计算最后一个样本,发现没有误差,第一个![]() 中所有的样本都执行了一遍,因此第一个
中所有的样本都执行了一遍,因此第一个![]() 结束:
结束:

第二个![]() 中:
中:

第一个样本需要梯度更新,![]() ,被更新成
,被更新成![]() 。第二个样本是正确的,不需要更新,第三个样本又产生了误差,需要梯度更新
。第二个样本是正确的,不需要更新,第三个样本又产生了误差,需要梯度更新![]() ,被更新成
,被更新成![]() 。第四个样本不需要梯度更新,
。第四个样本不需要梯度更新,![]() 结束。
结束。
第三个![]() 中:
中:
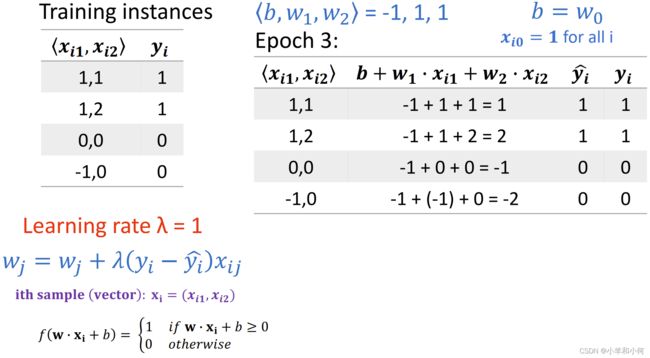
所有样本都没有发生梯度更新,这个模型已经收敛,因此不需要进行新的![]() ,迭代结束。
,迭代结束。
3.2 激活函数
Activation Function:一般有以下三种选择。
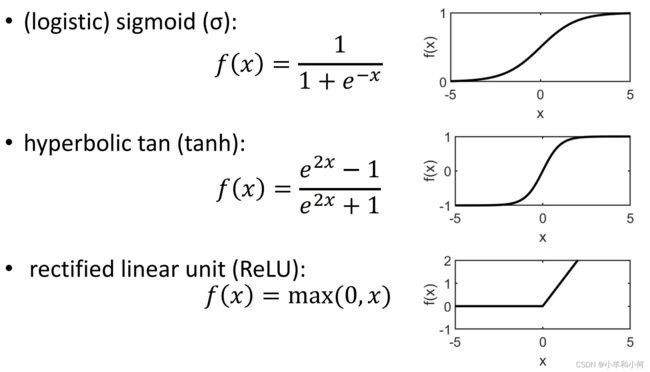
激活函数的作用一方面将加权求和后的信号进行归一化到![[0,1]](http://img.e-com-net.com/image/info8/8777b12420fe47dea8295caddad6bdb6.gif) 之间,另外一方面可以帮助多层的感知机模型获得非线性分类的能力。
之间,另外一方面可以帮助多层的感知机模型获得非线性分类的能力。
对于感知机自身的激活函数:

这只能对线性可分的数据有一个较好的拟合结果,因为他本身基于的是线性假设,求解的总是一个 ![]() 的线性方程。
的线性方程。
感知机也不能保证分类数据有最大的决策边界(那是![]() 模型的任务)。感知机更不能够保证对非线性可分(non-linearly separable)数据拟合的很好。感知机本质上是基于线性假设,如果把激活函数改成
模型的任务)。感知机更不能够保证对非线性可分(non-linearly separable)数据拟合的很好。感知机本质上是基于线性假设,如果把激活函数改成![]() 函数,那么感知机就可以成为一个逻辑回归模型。
函数,那么感知机就可以成为一个逻辑回归模型。
3.3 一层感知机
我们上面说的概念对应的是一个感知机,对应的是一个神经元结点,那么如果有多个神经元结点,就能用他们来组成一层感知机。
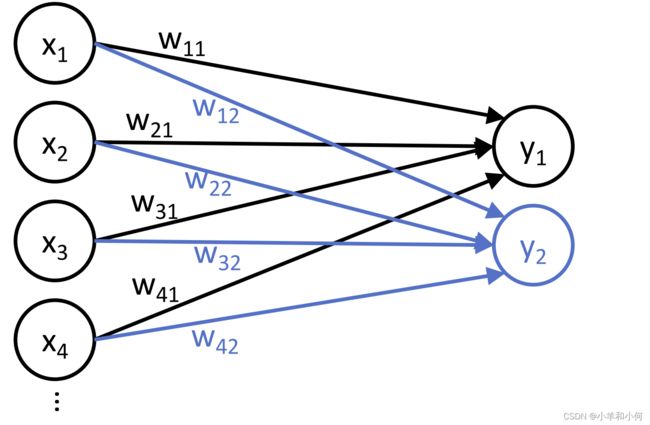
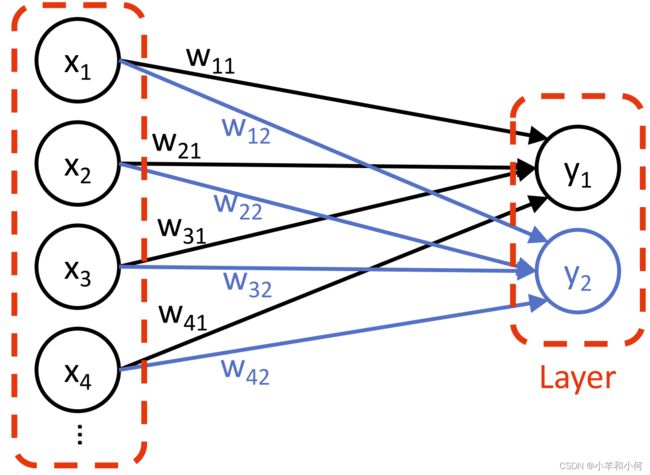
那么为什么要把![]() 的概念引入感知机呢?因为同一层内的所有感知机接受的是同样的输入,通过训练可以形成不同的参数,例如第一个节点
的概念引入感知机呢?因为同一层内的所有感知机接受的是同样的输入,通过训练可以形成不同的参数,例如第一个节点 相关的参数是
相关的参数是![]() 但第二个感知机
但第二个感知机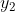 的相关参数是
的相关参数是![]() 。这样的一层感知机对于同一个输入最后就可以给出多个输出的结果,如果再结合
。这样的一层感知机对于同一个输入最后就可以给出多个输出的结果,如果再结合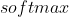 激活函数,就可以进行多分类任务。当然这个是后面神经网络的内容,我们在这里只是通过这种方式来认识什么是一层感知机。有了一层感知机的概念,就可以扩展到多层感知机。
激活函数,就可以进行多分类任务。当然这个是后面神经网络的内容,我们在这里只是通过这种方式来认识什么是一层感知机。有了一层感知机的概念,就可以扩展到多层感知机。
3.4 多层感知机

多层感知机有三个部分组成:
- 输入层
- 隐藏层
- 输出层
输入层的神经元的数量取决于输入样本的特征数。输出层的神经元数量取决于分类任务或者是回归任务。隐藏层可以有很多层,图中只画了一层。每个隐藏层存在的意义都是对输入进行重新编码,编码成抽象的向量,然后输出给后面的层。在多分类任务中输出层的神经元数量与分类的类别数量一致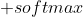 激活函数。
激活函数。
常见选项:
- 二分类任务中,输出层一个神经元
 阶跃函数作为激活函数。
阶跃函数作为激活函数。  路分类——个输出神经元和激活函数。
路分类——个输出神经元和激活函数。- 回归任务中输出层只有一个神经元
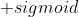 激活函数。
激活函数。
3.4.1 隐藏层神经元数量选择
鉴于我们不知道这一层应该学习什么特征,如何挑选合适的神经元数量?
在理论上,取决于决策边界的复杂性等因素;
在实践中,通常只是在输入和输出大小之间选择一个任意的值。
3.4.2 隐藏层如何学习参数
通过后向传播算法![]() 。
。
输出层的预测值和真实标签产生的误差的梯度可以通过链式法则传播到任意一个隐藏层,从而根据感知机更新参数的方式来更新每一个神经元的参数。这个过程是借助随机梯度下降的方式来完成的。因此和单个感知机一样,也需要设置一个学习率。
3.4.3 多层感知机的性质
通用逼近定理(Universal approximation theorem)具有隐藏层的神经网络可以逼近任意的连续函数。这意味着多层感知机(神经网络)可以拟合任何线性或者非线性的函数(不同于逻辑回归或者 SVM 只能基于线性可分数据集)。上述的复杂的拟合任务必须要借助非线性!
多层感知机如何具备非线性能力:
例如我们具有一个三层的感知机:一个输入层,一个输出层和一个隐藏层,三个层的参数矩阵我们分别用![]() 表示。那么一个输入经过整个网络的过程可以表示成:
表示。那么一个输入经过整个网络的过程可以表示成:
![]()
其中都是非线性的激活函数。非常清楚,这个式子可以拟合一个复杂的非线性函数。
作为对比,如果不采用任何非线性函数,只是使用上述的三层感知机,那么这个过程可以表示成:
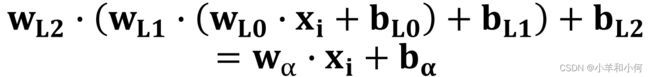
通过最后的化简,这还是一个线性的函数,换句话说,还是只能处理线性可分的数据集。
因此我们说多层感知机必须搭配非线性的激活函数才能具有强大的非线性拟合能力。
3.4.4 多层感知机总结
因为多层感知机有拟合复杂数据的能力,那么他就一定比线性模型的表现更好么?
否定的,因为对于很多简单的数据集,仅用线性假设就可以很好解决, 如果采用太复杂的模型,很容易过拟合。
因为神经网络可以在隐藏层学习到他们自己的表示(representation)因此,他们不需要任何特征工程。
错的,如果不进行任何特征工程,那么很多噪声数据或者特征就容易给模型的拟合带来不利影响,
。所以特征工程在很多时候都是需要的。
由于![]() 是通用的逼近器,它们保证比任何其他机器学习方法具有更好的概括性。
是通用的逼近器,它们保证比任何其他机器学习方法具有更好的概括性。
由于![]() 在隐藏层中学习自己的表征,它们不需要任何特征工程。
在隐藏层中学习自己的表征,它们不需要任何特征工程。
多层感知机的优缺点
- 可以适用多种任务:分类和回归任务
- 通用性很好,可以拟合多种分布
- 隐藏层可以学习到自己的特征表示
- 参数量太大,需要消耗很多的内存资源;
- 训练速度太慢,而且以为模型复杂容易过拟合
- 随机梯度下降不能保证每次都能收敛到同一结果