Pytorch利用图像分割识别手势验证码(Deeplabv3)
首先看一下手势验证码的数据集,每一个png图像对应一个json文件,json就是标签,数据集比较少,只有100多张,本章节将使用pytorch的deeplabv3进行迁移学习来识别手势验证码,由于数据集较少,所以整体来讲,最后的识别效果略差,仅仅只是略差,但是整体的思路明确,加上图文结合整篇文章可以说简单易懂,通透,但是针对我的代码还有很大的提升空间,具体的方案后续再研究
如果需要数据集请私我,我这里有4,6位,点选,成语,计算题,手势等各类型验证码,免费分享,交流学习



图像的标签使用labelme进行标注,具体labelme是什么,怎么安装使用,请参考官方文档或者其他社区文章,json文件标签长这样,标签里的points对应的是每一个坐标点,每一个坐标点相连,实现整个手势的一个闭环,

由于是手势验证码,需要模拟手势的轨迹,故思路就是将手势与背景做一个像素级的分类,将手势分割出来,所以是一个语义分割任务,这里我将使用deeplabv3神经网络进行训练,图像分割任务其实与一般的图像分类任务类似,整体的步骤也是类似,都是获取数据,然后打上标签,丢进神经网络训练即可,下面来讲具体的步骤如下:
1、构建Dataset
所有的dataset构建都需要返回一个数据和一个标签,首先讲一下这里的数据,数据很明显就是png图像了,需要注意的是由于这是图像分割任务,传统的图像增强方法可能会使得图像出错,所以这里使用albumentations这个库进行图像增强,这个库有很多的图像增强方法,具体也可以参考一个github官方文档,下面看一下我的dataset构建代码
导入库
%matplotlib inline
import os
import cv2
import numpy as np
import matplotlib.pylab as plt
from PIL import Image
import torch
from torch import nn
from torch.utils.data import DataLoader, Dataset
from torchvision.models.segmentation import deeplabv3_resnet101
import albumentations as A
构建dataset
注意我构建的dateaset里面有很多形状转换,很多小伙伴容易搞混,我这里讲一下大概的步骤,首先cv2读取的图像是(H,W,3),这里的C通常都是3通道,然后mask也需要放入图像增强当中去,因为有背景和手势总共两类,mask本身为二值图像,所以最终的mask的形状是(H,W,2),这里的C通道是2通道,因为是两类,但是deeplabv3需要加载的图像格式是(C,H,W),所以到最后image和mask都做了一次形状转换。
class ImgData(Dataset):
def __init__(self, img_path, mask_path, is_train):
super().__init__()
imgs = os.listdir(img_path)
imgs = [img for img in imgs if "png" in img]
self.is_train = is_train
if self.is_train:
imgs = imgs[:int(len(imgs) * 0.9)]
else:
imgs = imgs[int(len(imgs) * 0.9):]
self.__dict__.update(locals())
self.zeross = np.zeros((1, 270, 480))
self.oness = np.ones((1, 270, 480))
self.trans = A.Compose([
A.Resize(270, 480),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5),
A.OneOf([
A.MotionBlur(p=0.2), # 使用随机大小的内核将运动模糊应用于输入图像。
A.MedianBlur(blur_limit=3, p=0.1), # 中值滤波
A.Blur(blur_limit=3, p=0.1), # 使用随机大小的内核模糊输入图像。
], p=0.5),
A.ShiftScaleRotate(shift_limit=0.0625, scale_limit=0.2, rotate_limit=45, p=0.2),
# 随机应用仿射变换:平移,缩放和旋转输入
A.RandomBrightnessContrast(p=0.2), # 随机明亮对比度
A.Resize(270, 480),
A.Normalize(mean=[0.485, 0.456, 0.406] , std=[0.229, 0.224, 0.225])
])
def __getitem__(self, index):
if self.is_train:
image = cv2.imread(os.path.join(self.img_path, self.imgs[index]))
mask = cv2.imread(os.path.join(self.mask_path, self.imgs[index]))
mask = mask[:,:, 2] # 由于数据集标注的通道在第三个通道,所以取出第三个通道
mask = np.expand_dims(mask, axis=0)
mask2 = mask.copy()
mask = np.where(mask>0,self.oness, mask)
mask2 = np.where(mask2==0,self.oness, mask2)
mask2 = np.where(mask2==128,self.zeross, mask2)
masks = np.concatenate((mask, mask2), axis=0) # mask是构建背景0,手势1的二值图,mask2则相反
masks = masks.transpose(1,2, 0) # 转换图像增强需要的维度
datas = self.trans(image=image, mask=masks)
image, masks = datas["image"], datas["mask"]
image = image.transpose(2,0,1) # 图像增强后转换出来
masks = masks.transpose(2,0,1)
image, masks = torch.Tensor(image), torch.Tensor(masks)
else:
image = cv2.imread(os.path.join(self.img_path, self.imgs[index]))
mask = cv2.imread(os.path.join(self.mask_path, self.imgs[index]))
mask = mask[:,:, 2] # 由于数据集标注的通道在第三个通道,所以取出第三个通道
mask = np.expand_dims(mask, axis=0)
masks = mask.copy()
masks = mask.transpose(2,0,1)
image = image.transpose(2,0,1)
image, masks = torch.Tensor(image), torch.Tensor(masks)
return image, masks
def __len__(self):
return len(self.imgs)
torch.cuda.empty_cache()
#数据地址
img_path = "./vaptcha_recoginse-master/images/"
mask_path = "./vaptcha_recoginse-master/mask/"
trainset = ImgData(img_path,mask_path, is_train=True)
valset = ImgData(img_path,mask_path, is_train=False)
trainloader = DataLoader(trainset, batch_size=16,num_workers=8)
valloader = DataLoader(valset, batch_size=16)
查看数据集
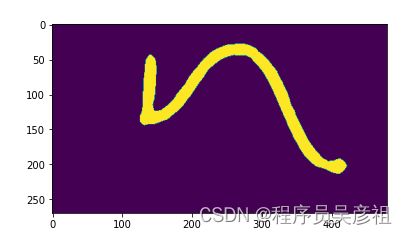
这里查看dataset读取的第一张图片的第一个通道,与它的一个标签
img, labels = trainset[0]
plt.imshow(labels[0].cpu().numpy())
plt.show()
plt.imshow(img[0].cpu().numpy())
plt.show()
构建dataloader
trainloader = DataLoader(trainset, batch_size=16,num_workers=8)
valloader = DataLoader(valset, batch_size=16)
2、搭建模型
这里就不搭建模型了,直接使用迁移学习,我这里使用的pytorch自带的模型deeplabv3_resnet101,目前经过我的测试来看,这个模型效果最好,因为只有背景和手势两个类别,所以传入的num_classes=2,因为是精细到像素点的多分类任务,所以损失函数使用交叉熵,加上数据集比较小,直接使用Adam优化器即可,这里根据自己需要可以增加断点续训等操作
# 加载GPU
DEVICE = torch.device("cuda:1")
# 加载模型和超参数
model = deeplabv3_resnet101(num_classes=2)
model = model.to(DEVICE)
losses = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
# scheduler = StepLR(
# optimizer=optimizer,
# step_size=20, # 设定调整的间隔数
# gamma=0.95, # 系数
# last_epoch=-1
# )
#
# path_checkpoint = './models/ckpt_best.pth'
# checkpoint = torch.load(path_checkpoint) # 加载断点
# model.load_state_dict(checkpoint['net']) # 加载模型可学习参数
# print(checkpoint['optimizer'])
# start_epoch = checkpoint['epoch'] # 设置开始x的epoch
# optimizer.load_state_dict(checkpoint['optimizer']) # 加载优化器参数
# for param_group in optimizer.param_groups:
# param_group["lr"] = 1e-6
# # print(optimizer.param_groups)
# scheduler = ReduceLROnPlateau(optimizer, mode='min', patience=3, factor=0.8, min_lr=0.0001)
3、训练模型
训练模型
这里训练循环300次,然后每次迭代完成之后看一下最终的loss,输出[“out”]包含语义掩码,而输出[“aux”]包含每像素的辅助损失值。在推理模式中,输出[‘aux]没有用处。因此,输出“out”形状为(N、2、H、W)。
model.train()
for epoch in range(300):
running_loss = 0.
for i, data in enumerate(trainloader):
img, label = data
img, label = img.to(DEVICE), label.to(DEVICE)
optimizer.zero_grad()
pred = model(img)["out"]
loss = losses(pred, label)
loss.backward()
running_loss += loss.item()
optimizer.step()
# scheduler.step(running_loss)
# scheduler.step()
print("epoch: %s loss: %s" % (epoch, running_loss))
# 保存模型
checkpoint = {
"net": model.state_dict(),
'optimizer': optimizer.state_dict(),
"epoch": epoch
}
torch.save(checkpoint, './models/ckpt_best.pth')
查看loss
每一次losss也是有所降低的

4、测试模型
测试模型
最终测试模型,我也没有计算最后的miou是多少,实际应用场景,手势验证码只需要模拟一条大概的轨迹就行,只要偏差不是很严重,一般都能过,不过可能需要注意的是,最后的模拟轨迹可能需要加一些平滑处理,包括你还要得到一组平滑的坐标点,如果直接硬生生滑过去,网页估计大概是过不了
值得注意的是,最后我的输出图像是im,im已经是“mask”了, 不过im还需要进行处理,里面的每一个值是这个像素点所属类型的一个期望或者相关性,因为手势验证码本质上是二分类任务,所以我将期望为负的转换为0,期望为正的转化为255,最终得到一个完整的mask,这样的mask也只是仅供展示,当然如果你的类型很多的话,我这种土方法可能就不适用了
correct = 0
total = 0
DEVICE = torch.device("cuda:1")
zeros = torch.zeros(270, 480).to(DEVICE)
ones = torch.zeros(270, 480) + 255
ones = ones.to(DEVICE)
# path_checkpoint = './models/ckpt_best.pth'
# checkpoint = torch.load(path_checkpoint) # 加载断点
# model = deeplabv3_resnet101(num_classes=2)
# #print(model)
# model = model.to(DEVICE)
# model.load_state_dict(checkpoint['net']) # 加载模型可学习参数
with torch.no_grad():
for data in valloader:
images, labels = data
images, labels = images.to(DEVICE), labels.to(DEVICE)
outputs = model(images)
outputs = outputs["out"]
for out in outputs:
for bb in out:
im = bb.clone()
im = torch.where(im > 0, ones, im)
im = torch.where(im < 0, zeros, im)
im = im.cpu().numpy()
plt.imshow(im)
plt.show()
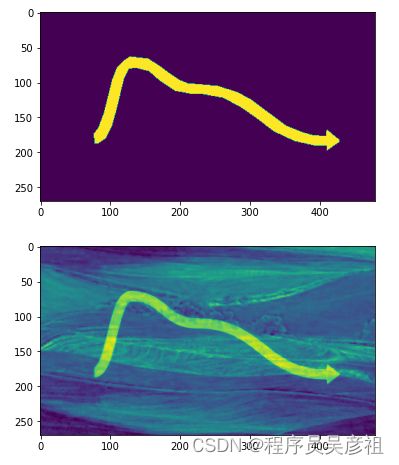
查看结果
这里可以看到,效果还真不错