pytorch 图像分割DeepLabv3+ 训练自己的数据
参考资料:1.https://blog.csdn.net/qq_43492938/article/details/111183906
2.https://blog.csdn.net/qq_30263737/article/details/114935101
3.https://zhuanlan.zhihu.com/p/415787913
4.https://blog.csdn.net/qq_42192910/article/details/91889842
5.https://github.com/wkentaro/labelme/tree/main/examples/instance_segmentation
6.https://blog.csdn.net/u014061630/article/details/88756644
7.https://blog.csdn.net/lemonbit/article/details/117408336
8.https://blog.csdn.net/qq_41314786/article/details/111960208
9.https://zhuanlan.zhihu.com/p/102303256
目录
一、训练数据准备
1.1使用labelme图像标注软件获取标注数据
1. labelme的功能
2. labelme的安装使用方法
3. labelme保存格式以及格式转换
4. 语义分割标签的特性
二. 训练自己的数据
三、deeplabv3+原理
3.1 空洞卷积
3.2 空间金字塔池化(SPP)
3.3 深度可分离卷积
3.4 Xception
3.5 deeplabv3+
一、训练数据准备
1.1使用labelme图像标注软件获取标注数据
1. labelme的功能
(1)labelme可以对图像进行多边形,矩形,圆形,多段线,点形式的标注(可用于目标检测,图像分割等任务),可以对图像进行flag形式的标注(可用于图像分类和清理任务),可以对视频标注。
(2)可以生成VOC格式的数据集(for semantic/instance segmentation(即语义或者实例分割))
(3)可以生成COCO格式的数据集(for instance segmentation(即实例分割))
2. labelme的安装使用方法
参考链接6,即https://blog.csdn.net/u014061630/article/details/88756644
windows下anaconda安装labelme参考:https://blog.csdn.net/weixin_45718019/article/details/108171093
3. labelme保存格式以及格式转换
使用labelme标注,会以JSON文件存储标注信息。其也提供将json文件转换为voc格式以及coco格式的接口。如参考链接5中的readme.md的方法:
转换为voc的命令:
./labelme2voc.py data_annotated data_dataset_voc --labels labels.txtdata_annotated:保存json以及原图的路径
data_dataset_voc:保存转换结果的路径
执行上述命令后会在data_dataset_voc的路径下生成下面文件夹
# It generates: # - data_dataset_voc/JPEGImages 表示原图像 # - data_dataset_voc/SegmentationClass .npy文件 # - data_dataset_voc/SegmentationClassPNG 语义分割的标签 训练需要 # - data_dataset_voc/SegmentationClassVisualization 将对应的标签可视化在原图上 # - data_dataset_voc/SegmentationObject .npy文件 # - data_dataset_voc/SegmentationObjectPNG 实例分割的标签 # - data_dataset_voc/SegmentationObjectVisualization 将对应的实例分割标签可视化在原图上
转换为COCO格式:
./labelme2coco.py data_annotated data_dataset_coco --labels labels.txt执行完上述命令后会在data_dataset_coco的路径下生成:
# It generates:
# - data_dataset_coco/JPEGImages 原图
# - data_dataset_coco/SegmentationClass 实例分割图
# - data_dataset_coco/annotations.json 还不清楚在我的实验中,下载了一个训练数据集,其中已经有原图以及标注好的json文件,我只需要将其转换为我需要的voc格式,我没有下载labelme软件,但是我可以使用上述提到的转换voc的命令获得到我需要的训练数据。

其中SegmentationClassPNG中的图像就是标签图像,在链接2中其保存在SegmentationClass中,训练时需注意路径问题。
4. 语义分割标签的特性
在观察标签图像时,发现一个问题,该文件夹中标签图像是8位位深,但是看上去却是彩色图像
如下:

在参考链接7即 https://blog.csdn.net/lemonbit/article/details/117408336博客中,有读取读取"label.png"看看里面底层数的代码,读取出来的值是连续的很小的数值(其实就是标签数值),而直接使用cv2读取,结果不同。这就非常困惑,花了非常多的时间来查找原因。其实由于其保存位为8位,但不是灰度图的原因是其本质上是一个调色版图。而如果cv直接读取,不加参数,会默认为三通道图,所以不同。
主要参考链接4. https://blog.csdn.net/qq_42192910/article/details/91889842
链接8.https://blog.csdn.net/qq_41314786/article/details/111960208
分别介绍了索引图像以及索引图像的读取方法,链接8更加的清晰易懂。也重点说了调色板模式需要使用PIL.Image格式来读取,但是不可以使用opencv读取。下面截取链接8中该内容的演示代码:
# 正确的读取方式
label = np.asarray(Image.open(label_path), dtype=np.int32)
# 错误的读取方式:因为调色板模式下,使用cv2.imread(label_path, 0)会默认以BGR转灰度图的模式读取,从而导致得到的label值不一致
label = cv2.imread(label_path, 0)当然,于此同时还发现,在使用调色板时(主要在训练时会要填颜色的值),需要查看map对应的颜色的值,链接4中有提到使用matlab看颜色值的方法,但是我太懒了没有下载,我从链接9中查阅到下图:
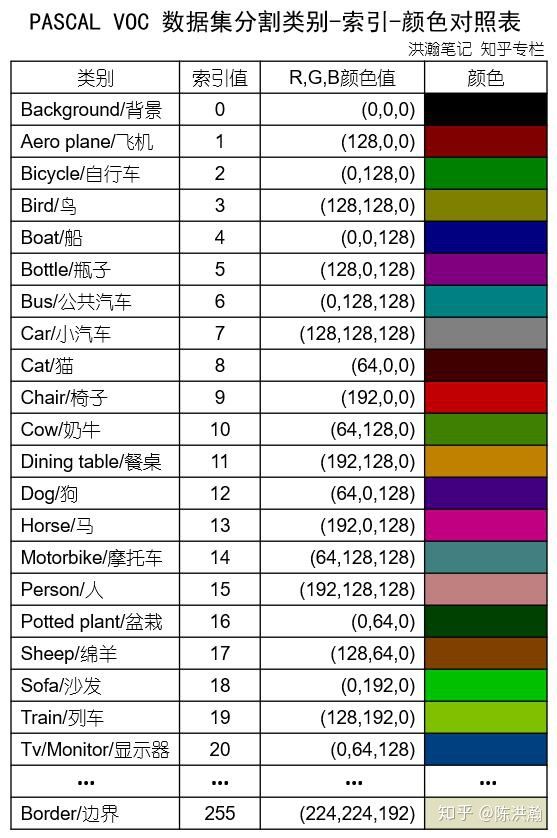
从该图中找到了生成的标签的颜色。
二. 训练自己的数据
主要参考链接2,即https://blog.csdn.net/qq_30263737/article/details/114935101
https://blog.csdn.net/yy2050645/article/details/121308825
生成train.txt,val.txt时采用的链接https://blog.csdn.net/xue_csdn/article/details/96448447中的代码。
训练一次后出错,参考链接https://blog.csdn.net/gsgs1234/article/details/115267777
训练时采用了“poly”学习率策略以及初始学习率设置为0.007,图像尺寸是513*513,模型训练是端到端的。
有个疑问:训练语义分割模型时,没有用的全链接层,也就是都是全卷积神经网络,那为啥输入图片的尺寸还要统一大小呢?
最后查阅资料:https://www.zhihu.com/question/288867733/answer/471172135
总结一下就是:最后输入图统一尺寸不是因为模型架构本身的限制,而是因为工程上的一些因素(为了提高训练效率,节省显存空间,训练是通常采用固定输入(变长数据结构浪费空间),统一mini-batch中的图像大小必须一样,固定尺寸好做数据shuffle)。但这只是在训练阶段,在测试阶段我们就可以发挥它支持任意尺寸图像的优势。或者把batch大小改为1,那么就支持使用不同大小的图像进行训练。
在这个问题下,还看到个问题,就是因为训练阶段,图片的尺寸已经固定,测试阶段,如果图片的尺寸和输入阶段不一致,会报“张量大小不一致”的错误。看到回答说如果是TensorFlow,输入纬度指定为None就可以了,另外一个回答也提到“可以看看框架的具体文档,一般来说框架会根据输入尺寸自动reshape网络(可能需要在某些尺寸参数上传None),不行的话你可以尝试手动reshape。”。
之后参照https://blog.csdn.net/yx868yx/article/details/113778713
该链接的第二部分DeepLabV3+实现,下载工程https://github.com/jfzhang95/pytorch-deeplab-xception
之后按照参考链接中的修改的部分将自己的内容替换进去,包括:
(1)修改工程中的mypath.py,在其中加上自己的数据集名字和所在的路径

(2)在dataloaders/datasets路径下创建自己的数据集文件,这里创建CDLA.py,因为我使用的是voc格式,所以直接将pascal.py内容复制过来修改为自己的数据集以及类别数,此处我处理的数据为11类。

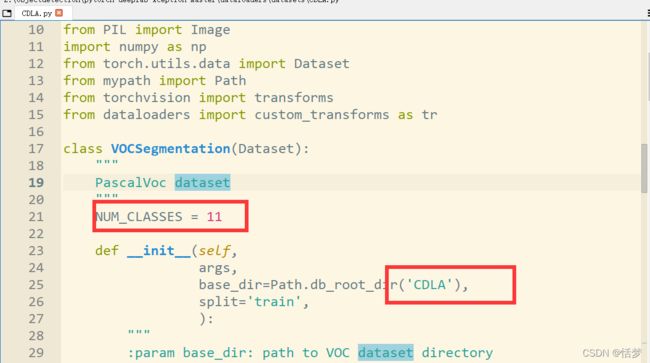
(3)修改dataloaders/utils.py,定义我们自己的类别的mask的颜色。

需要注意的是: 该部分的内容只会在测试的时候用到,训练的时候不会用到,在测试的代码中用到了该文件中的decode_seg_map_sequence,得到彩色mask结果,发现其与输入label格式不同,其为三通道的,之后需要使用该文件夹中的encode_segmap对其进行转换,变为与输入label格式相同的像素标签。
(4)修改dataloader/datasets/__init__.py,在其中添加自己的数据集
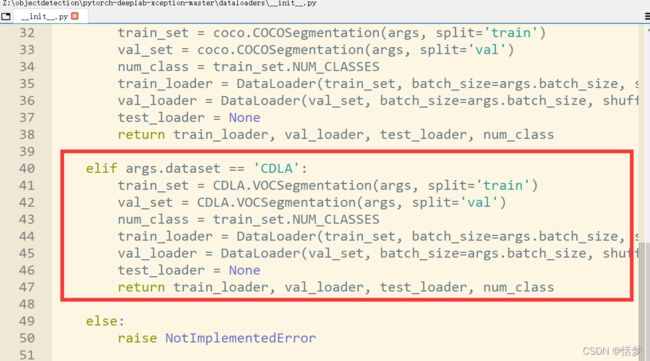
(5)修改train.py,在其中添加自己的数据集

(5)训练,在终端输入命令
python train.py --backbone resnet --lr 0.007 --workers 1 --epochs 50 --batch-size 8 --gpu-ids 0 --checkname deeplab-resnet --dataset CDLA
(6)测试,在参考链接中,详细的写了测试代码。下面是复制于原链接的
#
# demo.py
#
import argparse
import os
import numpy as np
import time
from modeling.deeplab import *
from dataloaders import custom_transforms as tr
from PIL import Image
from torchvision import transforms
from dataloaders.utils import *
from torchvision.utils import make_grid, save_image
def main():
parser = argparse.ArgumentParser(description="PyTorch DeeplabV3Plus Training")
parser.add_argument('--in-path', type=str, required=True, help='image to test')
# parser.add_argument('--out-path', type=str, required=True, help='mask image to save')
parser.add_argument('--backbone', type=str, default='resnet',
choices=['resnet', 'xception', 'drn', 'mobilenet'],
help='backbone name (default: resnet)')
parser.add_argument('--ckpt', type=str, default='deeplab-resnet.pth',
help='saved model')
parser.add_argument('--out-stride', type=int, default=16,
help='network output stride (default: 8)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--gpu-ids', type=str, default='0',
help='use which gpu to train, must be a \
comma-separated list of integers only (default=0)')
parser.add_argument('--dataset', type=str, default='pascal',
choices=['pascal', 'coco', 'cityscapes','invoice'],
help='dataset name (default: pascal)')
parser.add_argument('--crop-size', type=int, default=513,
help='crop image size')
parser.add_argument('--num_classes', type=int, default=2,
help='crop image size')
parser.add_argument('--sync-bn', type=bool, default=None,
help='whether to use sync bn (default: auto)')
parser.add_argument('--freeze-bn', type=bool, default=False,
help='whether to freeze bn parameters (default: False)')
args = parser.parse_args()
args.cuda = not args.no_cuda and torch.cuda.is_available()
if args.cuda:
try:
args.gpu_ids = [int(s) for s in args.gpu_ids.split(',')]
except ValueError:
raise ValueError('Argument --gpu_ids must be a comma-separated list of integers only')
if args.sync_bn is None:
if args.cuda and len(args.gpu_ids) > 1:
args.sync_bn = True
else:
args.sync_bn = False
model_s_time = time.time()
model = DeepLab(num_classes=args.num_classes,
backbone=args.backbone,
output_stride=args.out_stride,
sync_bn=args.sync_bn,
freeze_bn=args.freeze_bn)
ckpt = torch.load(args.ckpt, map_location='cpu')
model.load_state_dict(ckpt['state_dict'])
model = model.cuda()
model_u_time = time.time()
model_load_time = model_u_time-model_s_time
print("model load time is {}".format(model_load_time))
composed_transforms = transforms.Compose([
tr.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
tr.ToTensor()])
for name in os.listdir(args.in_path):
s_time = time.time()
image = Image.open(args.in_path+"/"+name).convert('RGB')
# image = Image.open(args.in_path).convert('RGB')
target = Image.open(args.in_path+"/"+name).convert('L')
sample = {'image': image, 'label': target}
tensor_in = composed_transforms(sample)['image'].unsqueeze(0)
model.eval()
if args.cuda:
tensor_in = tensor_in.cuda()
with torch.no_grad():
output = model(tensor_in)
grid_image = make_grid(decode_seg_map_sequence(torch.max(output[:3], 1)[1].detach().cpu().numpy()),
3, normalize=False, range=(0, 255))
save_image(grid_image,args.in_path+"/"+"{}_mask.png".format(name[0:-4]))
u_time = time.time()
img_time = u_time-s_time
print("image:{} time: {} ".format(name,img_time))
# save_image(grid_image, args.out_path)
# print("type(grid) is: ", type(grid_image))
# print("grid_image.shape is: ", grid_image.shape)
print("image save in in_path.")
if __name__ == "__main__":
main()
# python demo.py --in-path your_file --out-path your_dst_file
在终端运行:
python demo.py --in-path /home/pytorch-deeplab-xception-master/test_pic --ckpt model_best.pth.tar --backbone resnet
训练测试踩坑:
出错:RuntimeError: Error(s) in loading state_dict for DeepLab:
Missing key(s) in state_dict
模型保存时含有 nn.DataParallel时,就会发现所有的dict都会有 module的前缀。
修改方法:在加载模型的时候使用如下代码替换model.load_state_dict(ckpt['state_dict'])
from collections import OrderedDict
new_state_dict=OrderedDict()
for k,v in ckpt['state_dict'].items():
name=k[7:]#remove module
new_state_dict[name]=v
model.load_state_dict(new_state_dict) 三、deeplabv3+原理
参考资料:https://zhuanlan.zhihu.com/p/50369448
https://blog.csdn.net/yy2050645/article/details/121308825
3.1 空洞卷积
空洞卷积可以在扩大感受野的同时,不丢失分辨率。在深度网络中,通常为了增加感受野且降低计算量而进行降采样,降采样虽然可以增加感受野,但是空间分辨率也降低了。使用空洞卷积增加感受野不丢失分辨率,在检测、分割任务中十分有用。一方面感受野大了可以检测分割大目标,另一方面分辨率高了可以精确定位目标。空洞卷积可以捕获多尺度上下文信息。空洞卷积有一个参数可以设置dilation rate,具体含义就是在卷积核中填充dilation rate-1个0,因此,当设置不同dilation rate时,感受野就会不一样,也即获取了多尺度信息。
空洞卷积可以任意扩大感受野,且不需要引入额外参数,但如果把分辨率增加了,算法整体计算量肯定会增加。空洞卷积虽然有这么多优点,但在实际中不好优化,速度会大大折扣。
下面这段以及图像摘自链接http:// https://blog.csdn.net/yy2050645/article/details/121308825
在一个二维卷积中,对于卷积输出的特征 上的每个位置
上的每个位置 以及对应得卷积核
以及对应得卷积核 ,对于输入
,对于输入
空洞卷积的计算如下所示:
![y[i]=\sum_{k=0}^{kernel\_size}x[i+r\cdot k]w[k]](http://img.e-com-net.com/image/info8/bf6cf93d60174074ac69dab28353c39c.gif)
上式中 为空洞率,表示卷积核在卷积操作的输入上的取样步长;
为空洞率,表示卷积核在卷积操作的输入上的取样步长; 表示卷积核参数的位置,例如卷积核尺寸为3,则
表示卷积核参数的位置,例如卷积核尺寸为3,则![]() ;
;![]() 表示卷积核尺寸(论文中公式上没有,在这里为了表示清晰加入)。更直观的空洞卷积如下图所示 :
表示卷积核尺寸(论文中公式上没有,在这里为了表示清晰加入)。更直观的空洞卷积如下图所示 :

不难看出,标准卷积就是空洞率为1的空洞卷积。卷积核的感受野随着空洞率的改变随之也会发生改变。
3.2 空间金字塔池化(SPP)
参考链接:https://blog.csdn.net/qqliuzihan/article/details/81217766
在一般的深度网络结构中,在卷积层后面通常会连接着全连接。而全连接层的特征数是固定的,所以在网络输入的时候,会固定输入的大小。但是现实中,我们的输入的图像尺寸总是不能满足输入时要求的大小,通常的做法是裁剪(crop)和拉伸(wrap),但采用这样的方法会改变图像的纵横比和输入图像的尺寸,这样就会扭曲原始的图像。SPP层能很好的解决这样的问题,SPP通常连接在最后一个卷积层。
SPP的特点:(1)不管输入尺寸是怎样,SPP 可以产生固定大小的输出;(2)使用多个窗口(pooling window)(3) SPP 可以使用同一图像不同尺寸(scale)作为输入,得到同样长度的池化特征。(4) 由于对输入图像的不同纵横比和不同尺寸,SPP同样可以处理,所以提高了图像的尺寸不变和降低了过拟合。(5)实验表明训练图像尺寸的多样性比单一尺寸的训练图像更容易使得网络收敛。(6)SPP对于特定的CNN网络设计和结构是独立的,也就是说,只要把SPP放在卷积层后面,对网络的结构是没有影响的, 它只是替换了原来的pooling层)。(7)不仅可以用于图像分类而且可以用来目标检测。


上两图来自上述参考链接,但我认为池化之后大小为4*4时使用的池化核应该是5*5。conv5输出的大小是13*13*256.池化是向上取整,如果输出是4*4,那么(13-5)/3+1的向上取整结果为4*4。
ROI与SPP异同:
参考链接:https://blog.csdn.net/qq_45330708/article/details/116069384
两者起到的作用是相同的,都可以把把不同尺寸的特征输入转化为相同尺寸的特征输出。
SPP针对同一个输入使用了多个不同尺寸的池化操作,把不同尺度的结果拼接作为输出;
而ROI Pooling可看作单尺度的SPP,对于一个输入只进行一次池化操作。
3.3 深度可分离卷积
深度可分离卷积将一个标准卷积拆分为深度卷积+1*1卷积,可以极大得减少计算复杂度。深度卷积独立得为输入feature得每个channel做卷积操作,然后使用1*1的卷积对深度卷积的输出进行channel间融合,这样就替代了一个标准卷积操作,既融合了空间信息,也融合了不同通道间的信息。
3.4 Xception
参考链接https://blog.csdn.net/u014380165/article/details/75142710 写的很详细。
简述:使用depthwise separable convolution修改Inception v3结构就形成Xception。

Figure5是Xception的结构图。这里的sparsableConv就是depthwise separable convolution。
3.5 deeplabv3+
参考链接:https://blog.csdn.net/yy2050645/article/details/121308825
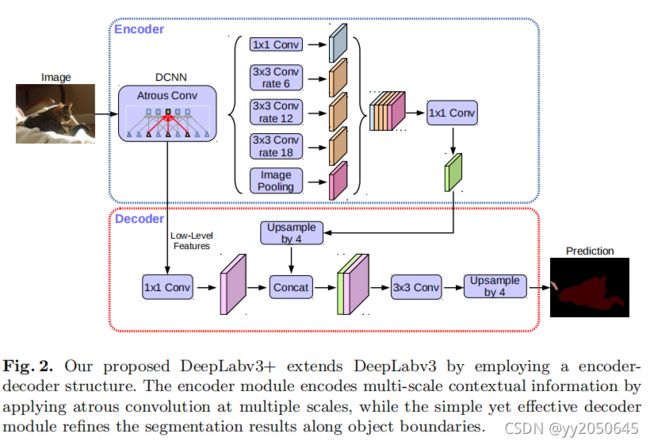
该模型将空间金字塔池化(SPP)模块以及encoder-decoder结构引入到深度神经网络中。。特别地,本文提出的deeplabv3+在deeplabv3的基础上加入了简单却有效的decoder模块去细化分割结果,特别是物体的边界。本文进一步探索了Xception模型并且将深度可分离卷积应用在空洞空间金字塔池化(ASPP)以及decoder模块中,从而构造出了更快和更强的encoder-decoder网络。
在deeplabv3+中,将空洞卷积用于深度卷积中,形成空洞可分离卷积(atrous seperable convolution)。如下图以及注释中所说(图源见水印):

DeepLabv3作为encoder:
Deeplabv3使用了空洞卷积去对深度神经网络输出的任意分辨率的feature进行特征提取。这里使用输出步长(output stride)表示模型输入图像和输出的feature map(在全局池化或全连接层之前)的空间分辨率的比值。对于分类任务,最终feature map的空间分辨率往往是模型输入图像的1/32,因此输出步长为32。对于语义分割任务来说,通过移除网络最后1到2个模块的步长以及相应地使用空洞卷积(例如对最后两个网络模块采用空洞率为2和4的空洞卷积从而实现输出步长为8)从而减小整个模型的输出步长从而达到输出步长为8或16,这样就能够提取到更稠密的特征。此外,deeplabv3增加了带有图像级别特征的空洞空间金字塔模块(ASPP),空间金字塔模块(ASPP)能够通过不同的空洞率获取多尺度卷积特征。本文使用原始deeplabv3的logits模块之前最后输出的feature map作为本文encoder-decoder中encoder部分的输出。需要注意的是,encoder输出的feature map包含256个通道以及丰富的语义信息。除此之外,根据计算能力可以采用空洞卷积在任意分辨率的输入上提取特征。
提出的decoder:
deeplabv3作为encoder输出的features通常输出步长为16,在之前的研究工作中,feature map通过双线性插值上采样16倍来将输出feature map恢复为模型输入尺寸,可以将其看作是一个简单的decoder模块。然而,这种简单的decoder模块可能并不能够很好的恢复物体分割细节。因此本文提出了一个简单但是有效的decoder模块,2.1中deeplabv3+整体结构图中所示,encoder输出的特征首先进行4倍的双线性插值上采样,然后和encoder中backbone中拥有相同尺寸的低级别(浅层)特征(例如Resnet-101的Conv2模块的输出)进行通道维度的拼接,在拼接之前首先对低级别特征进行1*1卷积,目的是为了减小低级别特征的通道数目,因为低级别特征通常含有大量的通道数目(例如256或512),这样底级别特征的重要性可能会超过encoder输出的富有语义信息的特征(在本文模型中只有256个通道)并且使得训练更加困难。在将encoder输出特征和低级别特征拼接之后,对拼接结果进行了几个3*3卷积操作去细化特征,并随后又接了一个4倍的双线性插值上采样。在之后的实验中证明了,当encoder的输出步长为16时可以达到速度和精度的最好的权衡。当encoder的输出步长为8时模型效果略有提升,但也相应增加了额外的计算复杂度代价。
改进Aligned Xception:
Xception模型在ImageNet上已经展示了不错的图像分类结果并有着较快的计算速度。最近,MSRA团队对Xception模型做了一些改动(称为Aligned Xception)以及进一步的推动了在目标检测任务上的表现。受这些发现的启发,本文沿着相同的方向去采用Xception模型来进行语义分割任务。特别地,我们在MSRA的修改上做了一些变动,分别为(1)更深的Xception,这个变动借鉴了以前的一些研究工作,但是不同的是,为了更快的计算以及高效的内存运用本文没有修改Xception的输入流网络结构(entry flow network structure);(2)最大池化操作通过使用带有一定步长的深度可分离卷积进行替代,也可以将深度可分离卷积替换为前文所说的空洞可分离卷积去在任意分辨率的输入上提取特征(或者另一种选择就是使用带有空洞率的最大池化操作替换原始的池化操作)。(3)在每一个3*3的深度卷积之后添加额外的batch normalization以及ReLU操作,这与MobileNet的设计类似。修改后的Xception整体结构如下图所示:
四、打印网络模型结构、查看网络每层shape
两种方法:参考链接https://blog.csdn.net/weixin_45084253/article/details/124041853
https://blog.csdn.net/weixin_42233605/article/details/125214041
方法一:安装 pip install torchsummary
代码中需加入如下:
from torchsummary import summary
summary(your_model, input_size=(channels, H, W))
在本文代码中:
from torchsummary import summary
model = DeepLab(num_classes=args.num_classes,
backbone=args.backbone,
output_stride=args.out_stride,
sync_bn=args.sync_bn,
freeze_bn=args.freeze_bn).to('cuda')
summary(model,(3,513,513))#torchsummary库中的summary结果如下:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 257, 257] 9,408
BatchNorm2d-2 [-1, 64, 257, 257] 128
ReLU-3 [-1, 64, 257, 257] 0
MaxPool2d-4 [-1, 64, 129, 129] 0
Conv2d-5 [-1, 64, 129, 129] 4,096
BatchNorm2d-6 [-1, 64, 129, 129] 128
ReLU-7 [-1, 64, 129, 129] 0
Conv2d-8 [-1, 64, 129, 129] 36,864
BatchNorm2d-9 [-1, 64, 129, 129] 128
ReLU-10 [-1, 64, 129, 129] 0
Conv2d-11 [-1, 256, 129, 129] 16,384
BatchNorm2d-12 [-1, 256, 129, 129] 512
Conv2d-13 [-1, 256, 129, 129] 16,384
BatchNorm2d-14 [-1, 256, 129, 129] 512
ReLU-15 [-1, 256, 129, 129] 0
Bottleneck-16 [-1, 256, 129, 129] 0
Conv2d-17 [-1, 64, 129, 129] 16,384
BatchNorm2d-18 [-1, 64, 129, 129] 128
ReLU-19 [-1, 64, 129, 129] 0
Conv2d-20 [-1, 64, 129, 129] 36,864
BatchNorm2d-21 [-1, 64, 129, 129] 128
ReLU-22 [-1, 64, 129, 129] 0
Conv2d-23 [-1, 256, 129, 129] 16,384
BatchNorm2d-24 [-1, 256, 129, 129] 512
ReLU-25 [-1, 256, 129, 129] 0
Bottleneck-26 [-1, 256, 129, 129] 0
Conv2d-27 [-1, 64, 129, 129] 16,384
BatchNorm2d-28 [-1, 64, 129, 129] 128
ReLU-29 [-1, 64, 129, 129] 0
Conv2d-30 [-1, 64, 129, 129] 36,864
BatchNorm2d-31 [-1, 64, 129, 129] 128
ReLU-32 [-1, 64, 129, 129] 0
Conv2d-33 [-1, 256, 129, 129] 16,384
BatchNorm2d-34 [-1, 256, 129, 129] 512
ReLU-35 [-1, 256, 129, 129] 0
Bottleneck-36 [-1, 256, 129, 129] 0
Conv2d-37 [-1, 128, 129, 129] 32,768
BatchNorm2d-38 [-1, 128, 129, 129] 256
ReLU-39 [-1, 128, 129, 129] 0
Conv2d-40 [-1, 128, 65, 65] 147,456
BatchNorm2d-41 [-1, 128, 65, 65] 256
ReLU-42 [-1, 128, 65, 65] 0
Conv2d-43 [-1, 512, 65, 65] 65,536
BatchNorm2d-44 [-1, 512, 65, 65] 1,024
Conv2d-45 [-1, 512, 65, 65] 131,072
BatchNorm2d-46 [-1, 512, 65, 65] 1,024
ReLU-47 [-1, 512, 65, 65] 0
Bottleneck-48 [-1, 512, 65, 65] 0
Conv2d-49 [-1, 128, 65, 65] 65,536
BatchNorm2d-50 [-1, 128, 65, 65] 256
ReLU-51 [-1, 128, 65, 65] 0
Conv2d-52 [-1, 128, 65, 65] 147,456
BatchNorm2d-53 [-1, 128, 65, 65] 256
ReLU-54 [-1, 128, 65, 65] 0
Conv2d-55 [-1, 512, 65, 65] 65,536
BatchNorm2d-56 [-1, 512, 65, 65] 1,024
ReLU-57 [-1, 512, 65, 65] 0
Bottleneck-58 [-1, 512, 65, 65] 0
Conv2d-59 [-1, 128, 65, 65] 65,536
BatchNorm2d-60 [-1, 128, 65, 65] 256
ReLU-61 [-1, 128, 65, 65] 0
Conv2d-62 [-1, 128, 65, 65] 147,456
BatchNorm2d-63 [-1, 128, 65, 65] 256
ReLU-64 [-1, 128, 65, 65] 0
Conv2d-65 [-1, 512, 65, 65] 65,536
BatchNorm2d-66 [-1, 512, 65, 65] 1,024
ReLU-67 [-1, 512, 65, 65] 0
Bottleneck-68 [-1, 512, 65, 65] 0
Conv2d-69 [-1, 128, 65, 65] 65,536
BatchNorm2d-70 [-1, 128, 65, 65] 256
ReLU-71 [-1, 128, 65, 65] 0
Conv2d-72 [-1, 128, 65, 65] 147,456
BatchNorm2d-73 [-1, 128, 65, 65] 256
ReLU-74 [-1, 128, 65, 65] 0
Conv2d-75 [-1, 512, 65, 65] 65,536
BatchNorm2d-76 [-1, 512, 65, 65] 1,024
ReLU-77 [-1, 512, 65, 65] 0
Bottleneck-78 [-1, 512, 65, 65] 0
Conv2d-79 [-1, 256, 65, 65] 131,072
BatchNorm2d-80 [-1, 256, 65, 65] 512
ReLU-81 [-1, 256, 65, 65] 0
Conv2d-82 [-1, 256, 33, 33] 589,824
BatchNorm2d-83 [-1, 256, 33, 33] 512
ReLU-84 [-1, 256, 33, 33] 0
Conv2d-85 [-1, 1024, 33, 33] 262,144
BatchNorm2d-86 [-1, 1024, 33, 33] 2,048
Conv2d-87 [-1, 1024, 33, 33] 524,288
BatchNorm2d-88 [-1, 1024, 33, 33] 2,048
ReLU-89 [-1, 1024, 33, 33] 0
Bottleneck-90 [-1, 1024, 33, 33] 0
Conv2d-91 [-1, 256, 33, 33] 262,144
BatchNorm2d-92 [-1, 256, 33, 33] 512
ReLU-93 [-1, 256, 33, 33] 0
Conv2d-94 [-1, 256, 33, 33] 589,824
BatchNorm2d-95 [-1, 256, 33, 33] 512
ReLU-96 [-1, 256, 33, 33] 0
Conv2d-97 [-1, 1024, 33, 33] 262,144
BatchNorm2d-98 [-1, 1024, 33, 33] 2,048
ReLU-99 [-1, 1024, 33, 33] 0
Bottleneck-100 [-1, 1024, 33, 33] 0
Conv2d-101 [-1, 256, 33, 33] 262,144
BatchNorm2d-102 [-1, 256, 33, 33] 512
ReLU-103 [-1, 256, 33, 33] 0
Conv2d-104 [-1, 256, 33, 33] 589,824
BatchNorm2d-105 [-1, 256, 33, 33] 512
ReLU-106 [-1, 256, 33, 33] 0
Conv2d-107 [-1, 1024, 33, 33] 262,144
BatchNorm2d-108 [-1, 1024, 33, 33] 2,048
ReLU-109 [-1, 1024, 33, 33] 0
Bottleneck-110 [-1, 1024, 33, 33] 0
Conv2d-111 [-1, 256, 33, 33] 262,144
BatchNorm2d-112 [-1, 256, 33, 33] 512
ReLU-113 [-1, 256, 33, 33] 0
Conv2d-114 [-1, 256, 33, 33] 589,824
BatchNorm2d-115 [-1, 256, 33, 33] 512
ReLU-116 [-1, 256, 33, 33] 0
Conv2d-117 [-1, 1024, 33, 33] 262,144
BatchNorm2d-118 [-1, 1024, 33, 33] 2,048
ReLU-119 [-1, 1024, 33, 33] 0
Bottleneck-120 [-1, 1024, 33, 33] 0
Conv2d-121 [-1, 256, 33, 33] 262,144
BatchNorm2d-122 [-1, 256, 33, 33] 512
ReLU-123 [-1, 256, 33, 33] 0
Conv2d-124 [-1, 256, 33, 33] 589,824
BatchNorm2d-125 [-1, 256, 33, 33] 512
ReLU-126 [-1, 256, 33, 33] 0
Conv2d-127 [-1, 1024, 33, 33] 262,144
BatchNorm2d-128 [-1, 1024, 33, 33] 2,048
ReLU-129 [-1, 1024, 33, 33] 0
Bottleneck-130 [-1, 1024, 33, 33] 0
Conv2d-131 [-1, 256, 33, 33] 262,144
BatchNorm2d-132 [-1, 256, 33, 33] 512
ReLU-133 [-1, 256, 33, 33] 0
Conv2d-134 [-1, 256, 33, 33] 589,824
BatchNorm2d-135 [-1, 256, 33, 33] 512
ReLU-136 [-1, 256, 33, 33] 0
Conv2d-137 [-1, 1024, 33, 33] 262,144
BatchNorm2d-138 [-1, 1024, 33, 33] 2,048
ReLU-139 [-1, 1024, 33, 33] 0
Bottleneck-140 [-1, 1024, 33, 33] 0
Conv2d-141 [-1, 256, 33, 33] 262,144
BatchNorm2d-142 [-1, 256, 33, 33] 512
ReLU-143 [-1, 256, 33, 33] 0
Conv2d-144 [-1, 256, 33, 33] 589,824
BatchNorm2d-145 [-1, 256, 33, 33] 512
ReLU-146 [-1, 256, 33, 33] 0
Conv2d-147 [-1, 1024, 33, 33] 262,144
BatchNorm2d-148 [-1, 1024, 33, 33] 2,048
ReLU-149 [-1, 1024, 33, 33] 0
Bottleneck-150 [-1, 1024, 33, 33] 0
Conv2d-151 [-1, 256, 33, 33] 262,144
BatchNorm2d-152 [-1, 256, 33, 33] 512
ReLU-153 [-1, 256, 33, 33] 0
Conv2d-154 [-1, 256, 33, 33] 589,824
BatchNorm2d-155 [-1, 256, 33, 33] 512
ReLU-156 [-1, 256, 33, 33] 0
Conv2d-157 [-1, 1024, 33, 33] 262,144
BatchNorm2d-158 [-1, 1024, 33, 33] 2,048
ReLU-159 [-1, 1024, 33, 33] 0
Bottleneck-160 [-1, 1024, 33, 33] 0
Conv2d-161 [-1, 256, 33, 33] 262,144
BatchNorm2d-162 [-1, 256, 33, 33] 512
ReLU-163 [-1, 256, 33, 33] 0
Conv2d-164 [-1, 256, 33, 33] 589,824
BatchNorm2d-165 [-1, 256, 33, 33] 512
ReLU-166 [-1, 256, 33, 33] 0
Conv2d-167 [-1, 1024, 33, 33] 262,144
BatchNorm2d-168 [-1, 1024, 33, 33] 2,048
ReLU-169 [-1, 1024, 33, 33] 0
Bottleneck-170 [-1, 1024, 33, 33] 0
Conv2d-171 [-1, 256, 33, 33] 262,144
BatchNorm2d-172 [-1, 256, 33, 33] 512
ReLU-173 [-1, 256, 33, 33] 0
Conv2d-174 [-1, 256, 33, 33] 589,824
BatchNorm2d-175 [-1, 256, 33, 33] 512
ReLU-176 [-1, 256, 33, 33] 0
Conv2d-177 [-1, 1024, 33, 33] 262,144
BatchNorm2d-178 [-1, 1024, 33, 33] 2,048
ReLU-179 [-1, 1024, 33, 33] 0
Bottleneck-180 [-1, 1024, 33, 33] 0
Conv2d-181 [-1, 256, 33, 33] 262,144
BatchNorm2d-182 [-1, 256, 33, 33] 512
ReLU-183 [-1, 256, 33, 33] 0
Conv2d-184 [-1, 256, 33, 33] 589,824
BatchNorm2d-185 [-1, 256, 33, 33] 512
ReLU-186 [-1, 256, 33, 33] 0
Conv2d-187 [-1, 1024, 33, 33] 262,144
BatchNorm2d-188 [-1, 1024, 33, 33] 2,048
ReLU-189 [-1, 1024, 33, 33] 0
Bottleneck-190 [-1, 1024, 33, 33] 0
Conv2d-191 [-1, 256, 33, 33] 262,144
BatchNorm2d-192 [-1, 256, 33, 33] 512
ReLU-193 [-1, 256, 33, 33] 0
Conv2d-194 [-1, 256, 33, 33] 589,824
BatchNorm2d-195 [-1, 256, 33, 33] 512
ReLU-196 [-1, 256, 33, 33] 0
Conv2d-197 [-1, 1024, 33, 33] 262,144
BatchNorm2d-198 [-1, 1024, 33, 33] 2,048
ReLU-199 [-1, 1024, 33, 33] 0
Bottleneck-200 [-1, 1024, 33, 33] 0
Conv2d-201 [-1, 256, 33, 33] 262,144
BatchNorm2d-202 [-1, 256, 33, 33] 512
ReLU-203 [-1, 256, 33, 33] 0
Conv2d-204 [-1, 256, 33, 33] 589,824
BatchNorm2d-205 [-1, 256, 33, 33] 512
ReLU-206 [-1, 256, 33, 33] 0
Conv2d-207 [-1, 1024, 33, 33] 262,144
BatchNorm2d-208 [-1, 1024, 33, 33] 2,048
ReLU-209 [-1, 1024, 33, 33] 0
Bottleneck-210 [-1, 1024, 33, 33] 0
Conv2d-211 [-1, 256, 33, 33] 262,144
BatchNorm2d-212 [-1, 256, 33, 33] 512
ReLU-213 [-1, 256, 33, 33] 0
Conv2d-214 [-1, 256, 33, 33] 589,824
BatchNorm2d-215 [-1, 256, 33, 33] 512
ReLU-216 [-1, 256, 33, 33] 0
Conv2d-217 [-1, 1024, 33, 33] 262,144
BatchNorm2d-218 [-1, 1024, 33, 33] 2,048
ReLU-219 [-1, 1024, 33, 33] 0
Bottleneck-220 [-1, 1024, 33, 33] 0
Conv2d-221 [-1, 256, 33, 33] 262,144
BatchNorm2d-222 [-1, 256, 33, 33] 512
ReLU-223 [-1, 256, 33, 33] 0
Conv2d-224 [-1, 256, 33, 33] 589,824
BatchNorm2d-225 [-1, 256, 33, 33] 512
ReLU-226 [-1, 256, 33, 33] 0
Conv2d-227 [-1, 1024, 33, 33] 262,144
BatchNorm2d-228 [-1, 1024, 33, 33] 2,048
ReLU-229 [-1, 1024, 33, 33] 0
Bottleneck-230 [-1, 1024, 33, 33] 0
Conv2d-231 [-1, 256, 33, 33] 262,144
BatchNorm2d-232 [-1, 256, 33, 33] 512
ReLU-233 [-1, 256, 33, 33] 0
Conv2d-234 [-1, 256, 33, 33] 589,824
BatchNorm2d-235 [-1, 256, 33, 33] 512
ReLU-236 [-1, 256, 33, 33] 0
Conv2d-237 [-1, 1024, 33, 33] 262,144
BatchNorm2d-238 [-1, 1024, 33, 33] 2,048
ReLU-239 [-1, 1024, 33, 33] 0
Bottleneck-240 [-1, 1024, 33, 33] 0
Conv2d-241 [-1, 256, 33, 33] 262,144
BatchNorm2d-242 [-1, 256, 33, 33] 512
ReLU-243 [-1, 256, 33, 33] 0
Conv2d-244 [-1, 256, 33, 33] 589,824
BatchNorm2d-245 [-1, 256, 33, 33] 512
ReLU-246 [-1, 256, 33, 33] 0
Conv2d-247 [-1, 1024, 33, 33] 262,144
BatchNorm2d-248 [-1, 1024, 33, 33] 2,048
ReLU-249 [-1, 1024, 33, 33] 0
Bottleneck-250 [-1, 1024, 33, 33] 0
Conv2d-251 [-1, 256, 33, 33] 262,144
BatchNorm2d-252 [-1, 256, 33, 33] 512
ReLU-253 [-1, 256, 33, 33] 0
Conv2d-254 [-1, 256, 33, 33] 589,824
BatchNorm2d-255 [-1, 256, 33, 33] 512
ReLU-256 [-1, 256, 33, 33] 0
Conv2d-257 [-1, 1024, 33, 33] 262,144
BatchNorm2d-258 [-1, 1024, 33, 33] 2,048
ReLU-259 [-1, 1024, 33, 33] 0
Bottleneck-260 [-1, 1024, 33, 33] 0
Conv2d-261 [-1, 256, 33, 33] 262,144
BatchNorm2d-262 [-1, 256, 33, 33] 512
ReLU-263 [-1, 256, 33, 33] 0
Conv2d-264 [-1, 256, 33, 33] 589,824
BatchNorm2d-265 [-1, 256, 33, 33] 512
ReLU-266 [-1, 256, 33, 33] 0
Conv2d-267 [-1, 1024, 33, 33] 262,144
BatchNorm2d-268 [-1, 1024, 33, 33] 2,048
ReLU-269 [-1, 1024, 33, 33] 0
Bottleneck-270 [-1, 1024, 33, 33] 0
Conv2d-271 [-1, 256, 33, 33] 262,144
BatchNorm2d-272 [-1, 256, 33, 33] 512
ReLU-273 [-1, 256, 33, 33] 0
Conv2d-274 [-1, 256, 33, 33] 589,824
BatchNorm2d-275 [-1, 256, 33, 33] 512
ReLU-276 [-1, 256, 33, 33] 0
Conv2d-277 [-1, 1024, 33, 33] 262,144
BatchNorm2d-278 [-1, 1024, 33, 33] 2,048
ReLU-279 [-1, 1024, 33, 33] 0
Bottleneck-280 [-1, 1024, 33, 33] 0
Conv2d-281 [-1, 256, 33, 33] 262,144
BatchNorm2d-282 [-1, 256, 33, 33] 512
ReLU-283 [-1, 256, 33, 33] 0
Conv2d-284 [-1, 256, 33, 33] 589,824
BatchNorm2d-285 [-1, 256, 33, 33] 512
ReLU-286 [-1, 256, 33, 33] 0
Conv2d-287 [-1, 1024, 33, 33] 262,144
BatchNorm2d-288 [-1, 1024, 33, 33] 2,048
ReLU-289 [-1, 1024, 33, 33] 0
Bottleneck-290 [-1, 1024, 33, 33] 0
Conv2d-291 [-1, 256, 33, 33] 262,144
BatchNorm2d-292 [-1, 256, 33, 33] 512
ReLU-293 [-1, 256, 33, 33] 0
Conv2d-294 [-1, 256, 33, 33] 589,824
BatchNorm2d-295 [-1, 256, 33, 33] 512
ReLU-296 [-1, 256, 33, 33] 0
Conv2d-297 [-1, 1024, 33, 33] 262,144
BatchNorm2d-298 [-1, 1024, 33, 33] 2,048
ReLU-299 [-1, 1024, 33, 33] 0
Bottleneck-300 [-1, 1024, 33, 33] 0
Conv2d-301 [-1, 256, 33, 33] 262,144
BatchNorm2d-302 [-1, 256, 33, 33] 512
ReLU-303 [-1, 256, 33, 33] 0
Conv2d-304 [-1, 256, 33, 33] 589,824
BatchNorm2d-305 [-1, 256, 33, 33] 512
ReLU-306 [-1, 256, 33, 33] 0
Conv2d-307 [-1, 1024, 33, 33] 262,144
BatchNorm2d-308 [-1, 1024, 33, 33] 2,048
ReLU-309 [-1, 1024, 33, 33] 0
Bottleneck-310 [-1, 1024, 33, 33] 0
Conv2d-311 [-1, 512, 33, 33] 524,288
BatchNorm2d-312 [-1, 512, 33, 33] 1,024
ReLU-313 [-1, 512, 33, 33] 0
Conv2d-314 [-1, 512, 33, 33] 2,359,296
BatchNorm2d-315 [-1, 512, 33, 33] 1,024
ReLU-316 [-1, 512, 33, 33] 0
Conv2d-317 [-1, 2048, 33, 33] 1,048,576
BatchNorm2d-318 [-1, 2048, 33, 33] 4,096
Conv2d-319 [-1, 2048, 33, 33] 2,097,152
BatchNorm2d-320 [-1, 2048, 33, 33] 4,096
ReLU-321 [-1, 2048, 33, 33] 0
Bottleneck-322 [-1, 2048, 33, 33] 0
Conv2d-323 [-1, 512, 33, 33] 1,048,576
BatchNorm2d-324 [-1, 512, 33, 33] 1,024
ReLU-325 [-1, 512, 33, 33] 0
Conv2d-326 [-1, 512, 33, 33] 2,359,296
BatchNorm2d-327 [-1, 512, 33, 33] 1,024
ReLU-328 [-1, 512, 33, 33] 0
Conv2d-329 [-1, 2048, 33, 33] 1,048,576
BatchNorm2d-330 [-1, 2048, 33, 33] 4,096
ReLU-331 [-1, 2048, 33, 33] 0
Bottleneck-332 [-1, 2048, 33, 33] 0
Conv2d-333 [-1, 512, 33, 33] 1,048,576
BatchNorm2d-334 [-1, 512, 33, 33] 1,024
ReLU-335 [-1, 512, 33, 33] 0
Conv2d-336 [-1, 512, 33, 33] 2,359,296
BatchNorm2d-337 [-1, 512, 33, 33] 1,024
ReLU-338 [-1, 512, 33, 33] 0
Conv2d-339 [-1, 2048, 33, 33] 1,048,576
BatchNorm2d-340 [-1, 2048, 33, 33] 4,096
ReLU-341 [-1, 2048, 33, 33] 0
Bottleneck-342 [-1, 2048, 33, 33] 0
ResNet-343 [[-1, 2048, 33, 33], [-1, 256, 129, 129]] 0
Conv2d-344 [-1, 256, 33, 33] 524,288
BatchNorm2d-345 [-1, 256, 33, 33] 512
ReLU-346 [-1, 256, 33, 33] 0
_ASPPModule-347 [-1, 256, 33, 33] 0
Conv2d-348 [-1, 256, 33, 33] 4,718,592
BatchNorm2d-349 [-1, 256, 33, 33] 512
ReLU-350 [-1, 256, 33, 33] 0
_ASPPModule-351 [-1, 256, 33, 33] 0
Conv2d-352 [-1, 256, 33, 33] 4,718,592
BatchNorm2d-353 [-1, 256, 33, 33] 512
ReLU-354 [-1, 256, 33, 33] 0
_ASPPModule-355 [-1, 256, 33, 33] 0
Conv2d-356 [-1, 256, 33, 33] 4,718,592
BatchNorm2d-357 [-1, 256, 33, 33] 512
ReLU-358 [-1, 256, 33, 33] 0
_ASPPModule-359 [-1, 256, 33, 33] 0
AdaptiveAvgPool2d-360 [-1, 2048, 1, 1] 0
Conv2d-361 [-1, 256, 1, 1] 524,288
BatchNorm2d-362 [-1, 256, 1, 1] 512
ReLU-363 [-1, 256, 1, 1] 0
Conv2d-364 [-1, 256, 33, 33] 327,680
BatchNorm2d-365 [-1, 256, 33, 33] 512
ReLU-366 [-1, 256, 33, 33] 0
Dropout-367 [-1, 256, 33, 33] 0
ASPP-368 [-1, 256, 33, 33] 0
Conv2d-369 [-1, 48, 129, 129] 12,288
BatchNorm2d-370 [-1, 48, 129, 129] 96
ReLU-371 [-1, 48, 129, 129] 0
Conv2d-372 [-1, 256, 129, 129] 700,416
BatchNorm2d-373 [-1, 256, 129, 129] 512
ReLU-374 [-1, 256, 129, 129] 0
Dropout-375 [-1, 256, 129, 129] 0
Conv2d-376 [-1, 256, 129, 129] 589,824
BatchNorm2d-377 [-1, 256, 129, 129] 512
ReLU-378 [-1, 256, 129, 129] 0
Dropout-379 [-1, 256, 129, 129] 0
Conv2d-380 [-1, 11, 129, 129] 2,827
Decoder-381 [-1, 11, 129, 129] 0
================================================================
Total params: 59,341,739
Trainable params: 59,341,739
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 3.01
Forward/backward pass size (MB): 72485305.17
Params size (MB): 226.37
Estimated Total Size (MB): 72485534.55
----------------------------------------------------------------
方法二:安装pip install torchinfo
在本文中:
from torchinfo import summary
model = DeepLab(num_classes=args.num_classes,
backbone=args.backbone,
output_stride=args.out_stride,
sync_bn=args.sync_bn,
freeze_bn=args.freeze_bn).to('cuda')
summary(model, input_size=(8, 3, 513, 513))## 8为batchsize结果:
===============================================================================================
Layer (type:depth-idx) Output Shape Param #
===============================================================================================
DeepLab [8, 11, 513, 513] --
├─ResNet: 1-1 [8, 2048, 33, 33] --
│ └─Conv2d: 2-1 [8, 64, 257, 257] 9,408
│ └─BatchNorm2d: 2-2 [8, 64, 257, 257] 128
│ └─ReLU: 2-3 [8, 64, 257, 257] --
│ └─MaxPool2d: 2-4 [8, 64, 129, 129] --
│ └─Sequential: 2-5 [8, 256, 129, 129] --
│ │ └─Bottleneck: 3-1 [8, 256, 129, 129] 75,008
│ │ └─Bottleneck: 3-2 [8, 256, 129, 129] 70,400
│ │ └─Bottleneck: 3-3 [8, 256, 129, 129] 70,400
│ └─Sequential: 2-6 [8, 512, 65, 65] --
│ │ └─Bottleneck: 3-4 [8, 512, 65, 65] 379,392
│ │ └─Bottleneck: 3-5 [8, 512, 65, 65] 280,064
│ │ └─Bottleneck: 3-6 [8, 512, 65, 65] 280,064
│ │ └─Bottleneck: 3-7 [8, 512, 65, 65] 280,064
│ └─Sequential: 2-7 [8, 1024, 33, 33] --
│ │ └─Bottleneck: 3-8 [8, 1024, 33, 33] 1,512,448
│ │ └─Bottleneck: 3-9 [8, 1024, 33, 33] 1,117,184
│ │ └─Bottleneck: 3-10 [8, 1024, 33, 33] 1,117,184
│ │ └─Bottleneck: 3-11 [8, 1024, 33, 33] 1,117,184
│ │ └─Bottleneck: 3-12 [8, 1024, 33, 33] 1,117,184
│ │ └─Bottleneck: 3-13 [8, 1024, 33, 33] 1,117,184
│ │ └─Bottleneck: 3-14 [8, 1024, 33, 33] 1,117,184
│ │ └─Bottleneck: 3-15 [8, 1024, 33, 33] 1,117,184
│ │ └─Bottleneck: 3-16 [8, 1024, 33, 33] 1,117,184
│ │ └─Bottleneck: 3-17 [8, 1024, 33, 33] 1,117,184
│ │ └─Bottleneck: 3-18 [8, 1024, 33, 33] 1,117,184
│ │ └─Bottleneck: 3-19 [8, 1024, 33, 33] 1,117,184
│ │ └─Bottleneck: 3-20 [8, 1024, 33, 33] 1,117,184
│ │ └─Bottleneck: 3-21 [8, 1024, 33, 33] 1,117,184
│ │ └─Bottleneck: 3-22 [8, 1024, 33, 33] 1,117,184
│ │ └─Bottleneck: 3-23 [8, 1024, 33, 33] 1,117,184
│ │ └─Bottleneck: 3-24 [8, 1024, 33, 33] 1,117,184
│ │ └─Bottleneck: 3-25 [8, 1024, 33, 33] 1,117,184
│ │ └─Bottleneck: 3-26 [8, 1024, 33, 33] 1,117,184
│ │ └─Bottleneck: 3-27 [8, 1024, 33, 33] 1,117,184
│ │ └─Bottleneck: 3-28 [8, 1024, 33, 33] 1,117,184
│ │ └─Bottleneck: 3-29 [8, 1024, 33, 33] 1,117,184
│ │ └─Bottleneck: 3-30 [8, 1024, 33, 33] 1,117,184
│ └─Sequential: 2-8 [8, 2048, 33, 33] --
│ │ └─Bottleneck: 3-31 [8, 2048, 33, 33] 6,039,552
│ │ └─Bottleneck: 3-32 [8, 2048, 33, 33] 4,462,592
│ │ └─Bottleneck: 3-33 [8, 2048, 33, 33] 4,462,592
├─ASPP: 1-2 [8, 256, 33, 33] --
│ └─_ASPPModule: 2-9 [8, 256, 33, 33] --
│ │ └─Conv2d: 3-34 [8, 256, 33, 33] 524,288
│ │ └─BatchNorm2d: 3-35 [8, 256, 33, 33] 512
│ │ └─ReLU: 3-36 [8, 256, 33, 33] --
│ └─_ASPPModule: 2-10 [8, 256, 33, 33] --
│ │ └─Conv2d: 3-37 [8, 256, 33, 33] 4,718,592
│ │ └─BatchNorm2d: 3-38 [8, 256, 33, 33] 512
│ │ └─ReLU: 3-39 [8, 256, 33, 33] --
│ └─_ASPPModule: 2-11 [8, 256, 33, 33] --
│ │ └─Conv2d: 3-40 [8, 256, 33, 33] 4,718,592
│ │ └─BatchNorm2d: 3-41 [8, 256, 33, 33] 512
│ │ └─ReLU: 3-42 [8, 256, 33, 33] --
│ └─_ASPPModule: 2-12 [8, 256, 33, 33] --
│ │ └─Conv2d: 3-43 [8, 256, 33, 33] 4,718,592
│ │ └─BatchNorm2d: 3-44 [8, 256, 33, 33] 512
│ │ └─ReLU: 3-45 [8, 256, 33, 33] --
│ └─Sequential: 2-13 [8, 256, 1, 1] --
│ │ └─AdaptiveAvgPool2d: 3-46 [8, 2048, 1, 1] --
│ │ └─Conv2d: 3-47 [8, 256, 1, 1] 524,288
│ │ └─BatchNorm2d: 3-48 [8, 256, 1, 1] 512
│ │ └─ReLU: 3-49 [8, 256, 1, 1] --
│ └─Conv2d: 2-14 [8, 256, 33, 33] 327,680
│ └─BatchNorm2d: 2-15 [8, 256, 33, 33] 512
│ └─ReLU: 2-16 [8, 256, 33, 33] --
│ └─Dropout: 2-17 [8, 256, 33, 33] --
├─Decoder: 1-3 [8, 11, 129, 129] --
│ └─Conv2d: 2-18 [8, 48, 129, 129] 12,288
│ └─BatchNorm2d: 2-19 [8, 48, 129, 129] 96
│ └─ReLU: 2-20 [8, 48, 129, 129] --
│ └─Sequential: 2-21 [8, 11, 129, 129] --
│ │ └─Conv2d: 3-50 [8, 256, 129, 129] 700,416
│ │ └─BatchNorm2d: 3-51 [8, 256, 129, 129] 512
│ │ └─ReLU: 3-52 [8, 256, 129, 129] --
│ │ └─Dropout: 3-53 [8, 256, 129, 129] --
│ │ └─Conv2d: 3-54 [8, 256, 129, 129] 589,824
│ │ └─BatchNorm2d: 3-55 [8, 256, 129, 129] 512
│ │ └─ReLU: 3-56 [8, 256, 129, 129] --
│ │ └─Dropout: 3-57 [8, 256, 129, 129] --
│ │ └─Conv2d: 3-58 [8, 11, 129, 129] 2,827
===============================================================================================
Total params: 59,341,739
Trainable params: 59,341,739
Non-trainable params: 0
Total mult-adds (G): 742.22
===============================================================================================
Input size (MB): 25.26
Forward/backward pass size (MB): 13804.88
Params size (MB): 237.37
Estimated Total Size (MB): 14067.51
===============================================================================================
结果比第一种方法易读
文中内容以及图像除个人理解部分,均摘自各个参考链接,如有侵权,联系删除。