Spring+SpringMVC+MyBatis框架的整合+注解
联系,区别:1.Srping是一个一站式的轻量级的JAVA开发框架,核心是控制反转(IoC)和面向切面(AOP),然对于开发的web层(SrpingMVC),业务层(IoC),持久层(jdbcTemple)等提提供了多种配置解决方案。2.SpringMVC是Spring基础之上的一个MVC框架,主要处理WEB开发的路径映射和视图渲染,属于Spring框架web层开发的一部分,涵盖面包括前端视图开发,文件配置,后台接口逻辑开发,SpringBoot专注于开发微服务后台接口,不开发前端视图,一定程度 上取消XML配置,能快速开发单个微服务,SpringCloud大部分的功能插件都是基于SpringBoot去实现的,SpringCloud关注全局的微服务和管理多个SpringBoot单体微服务进行整合及管理,
联系:区别:1.Hibernate是全自动的,而MyBatis是半自动的,Hibernate完全可以通过对象关系模型实现,对数据库的操作拥有完整的JavaBean对象和数据库的映射结构来自动生成SQL,而MyBatis仅有基本的字段映射,对象数据以及对象实际关系依然需要通过手写SQL来实现和管理。
什么是SSM框架
什么是框架,框架就是一些类和接口的集合,通过调用这些类和接口来完成一系列功能的实现。
什么是SSM?市面上存在的框架有很多种 ,我们在这里讲的SSM就是这些框架中的3个,目前这3个框架是目前市面上最热门,搭配使用率最高的框架,
MyBatis简介
MyBatis主要是通过SqlSessionFactory产生sqlSession对象,进而通过sqlSessiion对象访问数据库,而spring整合MyBatis的本质就是把MyBatis的sqlSessionFactory对象交给spring管理。
MyBatis是一款优秀的持久层框架,它支持定制化SQL,存储过程及高级映射,MyBatis避免了几乎所有的JDBC代码和手动设置参数及获取结果集。MyBatis可以使用简单的XML或注解来配置和映射原生信息。将接口和JAVA的POJO(Plain Ordinary Java Object简单Java对象)映射成数据库中的记录。
认识SpringMVC
SpringMVC是一款优秀视图层框架 ,用于对后台Java程序和前台JSP页面进行连接(功能类似Servlet,SpringMVC低层就是Servlet)
SpringMVC具有以下特点:
- SpringMVC拥有强大的灵活性,非入侵性和可配置性,
- SpringMVC提供了一个前端控制器DispatcherServlet.开发者无须额外开发控制器,
- SpringMVC分工明确,包含控制器,验证器,命令对象,模型对象,处理程序映射视图解析器等,每个功能实现由一个专门的对象负责完成。
- SpringMVC可以自动绑定用户输入,并正确地转换数据类型。例如SpringMVC能自动解析字符串,并将其设置为模型的int或float类型的属性,
- SpringMVC使用一个名称/值的MAP对象实现更加灵活的模型数据传输。
- SpringMVC内置了常 见的校验器,可以校验用户输入,如果校验不通过,则重定向回输入表单,输入校验是可选的,并且支持编程 方式和声明
方式。 - SpringMVC支持国际化,支持根据用户区域显示多国语言,并且国际化的 配置非常简单。
- SpringMVC支持多种视图技术,最常见的有JSP技术及其他技术,包括Velocity和FreeMarker.
- Spring提供了一个简单而强大的JSP标签库,支持数据绑定功能 ,使得编写JSP页面更 加容易。
Spring概述
Spring是一个开源框架 ,该框架的主要优势之一就是其分层架构,分层架构允许使用者选择使用哪个组件,同时为J2EE应用程序开发提供集成的框架,Spring使用基本的JavaBean来完成以前只可能由EJB完成的事情,然而,Spring的应用不仅限于服务器端的开发,从简单性、可测试性和松耦合的角度来看,任何Java应用都可以从Spring中收益,Spring的核心是控制反 转IoC 和面向切面AOP.
简单来说具有如下特点:
- 方便解耦,简化开发。通过Spring提供的IoC容器,我们可以将对象之间的依赖关系交由Spring进行控制,避免硬编码所造成的过度程序耦合,有了Spring,用户不必再为单实例模式类,属性文件解析等底层的需求编写代码。可以更专注于上层的应用。
- AOP编程的支持。通过Spring提供的AOP功能,可以方便地进行面向切面的编程 ,许多不容易
用传统OOP实现的功能可以通过AOP轻松应付。 - 声明式事务的支持。在Spring中,我们可以从单调烦闷 的事务管理代码中解脱出来,通过声明式方式灵活地进行事务的管理,提高开发效率和质量。
- 方便程序的测试,可以用非容器依赖的编程方式进行几乎所有的测试工作。在Spring里,测试不再是昂贵的操作,而是随手可做的事情,例如:Spring提供了对JUnit4的支持,可以通过注解方便地测试Spring程序。
- 方便集成各种优秀框架 ,Spring不排斥各种优秀 的开源框架,相反,它可以 降低各种框架的使用难度,提供了对种优 秀框架 (Struts,Hibernate,Hession二进制的网络协议,Quartz定时任务框架Quartz)支持.Hessian是一个轻量级的remoting onhttp工具,使用简单的方法提供了RMI的功能. 相比WebService,Hessian更简单、快捷。采用的是二进制RPC协议,因为采用的是二进制协议,所以它很适合于发送二进制数据。
- 降低JavaEE API的使用难度,Spring对很多难用的JAVA EE API(如JDBC,JavaMail,远程调用等)提供了一个博博的封装层,通过Spring的简易封装,这些Java EE API 使用难度大为降低。
- 如果你想在短时间内迅速提高自已的Java技术水平和应用开发水平,那么学习和研究Sping源码将会是不错的选择。
- 原则上Spring不会区分每一层的类上用的注解是否正规,意思就是,如果在实体 类上使用@Respository或@Service 也是可以的,程序不会报错,只是在编程人员眼中不是很正规。
- 在使用了@Autowired注解以后,我们 就不需要自已去创建对像了,这项工作交给Spring来帮我们完成,例如,如果我们想在Service层调用DAO里面的方法,则不需要写new那句代码了,直接用注解的方式来完成,在下面的项目中会有具体实例。
为什么使用框架
我们在Servlet里面接收前台传过来的值需要写很多的request.getParameter()方法,而且在给实体类进行赋值的时候也需要定很多个set***()方法。现在我们应用了框架 ,这些重复且枯燥的操作完全不用我们自已去完成了,只需要应用相应框架里面封装好的方法就可以直接完成了,在使用了这三大框架 以后,对于每个普通的增删改查的方法,一个方法代码,基本上不会超过5行,有些甚至只需一行代码就可以实现我们想要的功能。
MyBais中KaTeX parse error: Expected 'EOF', got '#' at position 2: 和#̲: 1.#{}是预编译处理,M…{}是字符串替换,MyBatis在处理 时 会 把 将 s q l 中 的 {}时会把将sql中的 时会把将sql中的{}替换为变量的值,传入的数据不会加两边加上单引号,注意:使用${}会导致sql注入,不利于系统的安全性。
说明:jsp里调用控制层,控制层里处理过逻辑后,是通过ModelAndView(带参构 造)或mav.setViewName(“xx.jsp”)进行处理后的页面跳转。
如何使用SSM框架
- 搭建SSM框架
第一步:准备好三大框架所需要的.jar包,24个。还一个连接MySQL数据库的包,共25个.jar包。
第二步:在IDE中创建一个WEB Project,并把上面25个jar包粘贴到lib文件夹中。
第三步:在src文件夹中创建Spring框架的一个配置文件,并命名为application.xml
第四步:在application.xml配置文件第二 行,也就是在这句的下面写一对标签,并在开始的标签里写上声明头,如
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-4.0.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop-4.0.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx-4.0.xsd" >
<context:annotation-config />
<context:component-scan base-package="com.lyq" />
<bean id="datasource"
class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/db_shop" />
<property name="username" value="root" />
<property name="password" value="root" />
bean>
<bean id="sessionFactory"
class="org.springframework.orm.hibernate4.LocalSessionFactoryBean">
<property name="configLocation">
<value>classpath:hibernate.cfg.xmlvalue>
property>
bean>
<bean id="sqlSessionFactory" calss="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="mapperLocations">
<list>
<value>classpath:com/mr/*-Mapper.xmlvalue>
list>
property>
<property name="typeAliasesPackage" value="com.mr.entity">
bean>
<bean id="transactionManager"
class="org.springframework.orm.hibernate4.HibernateTransactionManager">
或"org.springframework.jdbc.datasource.DtaaSourceTransactionManager"
<property name="sessionFactory">
<ref bean="sessionFactory" />
property>
<property name="dataSource" ref="datasource">property>
bean>
<tx:annotation-driven transaction-manager="transactionManager" />
beans>
第五步:开始配置Spring配置文件里面的内容,无先后顺序,这里先配置C3P0连接数据库。在src根目录下创建一个连接数据库的配置文件,名为db.properties.或conf.xml(里面注册Mapper.xml文件,如果不用映射文件而是通过注解来实现,就要定义映射的接口,并在conf.xml里和注册映射文件一样的位置注册此映射接口)
user=root
password=root
driverClass=com.mysql.jdbc.Driver //数据库连接驱动
url=jdbc:mysql://127.0.0.1:3306/test //数据库连接地址
initialSize=连接也启动时的初始值
maxActive=连接池的最大值
maxIdle = 最大空闲值,当经过一个高峰时间后,连接也可以慢慢将已经用不到的连接慢慢释放,一直减少到maxIdle为止。
minIdle最小空闲值,当空闲的连接减少于阀值时,连接池就会预申请一些连接,以免洪峰来时来不及申请。
第六步 下面就继续回到Spring配置文件中开始配置C3P0,我们在头标 签和结束标签的中间来配置相关信息。
<context:property-placeholder location="classpath:db.properties"/>
<bean id="dataSource" calss="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="user" value="${user}"/>
<property name="driverClass" value="${driverClass}"/>
<property name="password" value="${password}/>
" jdbcUrl" value="${url}"/>
bean>
注意:所有带${}符号里面的内容是你在dp.properties文件中起的名字。
第七步:配置SqlSessionFactory,用于装载MyBatis框架 ,持久层的方法可以通过映射直接找到相应的Mapper文件里的SQL语句,具体配置如下:
<bean id="sqlSessionFactory" calss="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="mapperLocations">
<list>
<value>classpath:com/mr/*-Mapper.xmlvalue>
list>
property>
<property name="typeAliasesPackage" value="com.mr.entity">
bean>
注意:通过以上配置,我们就能成功地把spring和MyBatis框架整合到一起了,
下面我们来写持久层和业务逻辑层。看看MyBatis到底怎么用的。之后完成控制层和视图层的编写。
创建实体类
首先对照数据库表创建一个实体类,表已经准备好了,然后创建一个Java实体 类,并在里面声明私有属性和对应的公有方法。
@Component
@Alias("Users") //Springboot 整合mybatis的时候,别名的用法,以后在Mapper文件中直接调用这个名字而无须写类名及完整类名。
public class Users{
private int uid;
private String uName;
private int uAge;
public int getuId(){
return uId;
}
public void setuId(int uId){
this.uId = uId;
}
public String getuName(){
return uName;
}
public void setuName(String uName){
this.uName = uName;
}
public int getuAge(){
returen uAge;
}
public int setuAge(int uAge){
this.uAge = uAge;
}
}
编写持久层
在编写持久层之前,需要知道即将用到的MyBatis哪些对象或接口。
(1)SqlSessionFactory
每个基于MyBatis的应用都是以一个SqlSessionFactory的 实例为中心的,SqlSessionFactory的实例可以通过SqlSessionFactoryBuilder获取,而SqlSessionFactoryBuilder则可以从XML配置文件或一个预先定制的Configueration的实例构建出SqlSessionFactory实例。
(2)从SqlSessionFactory中获取SqlSession
既然有了SqlSessionFactory,顾名思义,我们就可以从中获取SqlSession的实例了,SqlSession完全包含了面向数据库执行SQL命令所需的所有方法,用户可以通过SqlSession实例直接执行已映射的SQL语句。
(3)映射实例,让程序知道人体到哪个Mapper文件中执行SQL代码。
以上三个对象是每个daoImpl方法里都需要写的,我们先把重复代码提取出来封装到一个类下,这样以 后就不用写每个方法都创建这3个对象了,那么我们先创建一个BaseDaoImpl类用于封装这3个对象。
@Repository
public class BaseDaoImpl<T>{
//1.声明SqlSessionFactory
@Autowired
private SqlSessionFactory sqlSessionFactory;
//2.声明SqlSession
protected SqlSession sqlSession;
//3声明mapper属性
private Class<T> mapper;
//4为mapper创建 get,set
public T getMapper(){ //在持久层里面的构造方法里调用此处的setMapper后,然后
return sql.SessionFactory.openSession().getMapper(mapper);
}
public void setMapper(Class<T>mapper){
this.mapper= mapper;
}
}
1. 现在开始编写持久层代码,
补充知识:
在项目中,某些实体类之间肯定有关键关系,比如一对一,一对多等。在hibernate 中用one to one和one to many,而mybatis 中就用association和collection。
association: 一对一关联(has one)
collection:一对多关联(has many)
注意,只有在做select查询时才会用到这两个标签,都有三种用法,且用法类似。
mybatis进行多表查询时会用上association标签,它的属性包括:property,column,javaType等,它的作用是让实体类对角与数据库表的列相互对应,以便让mybatis可进行多表查询。
一、association的三种用法:
先看如下代码(省略set、get方法):
public class User {
private Integer userId;
private String userName;
private Integer age;
private Card card;//一个人一张身份证,1对1
}
public class Card {
private Integer cardId;
private String cardNum;//身份证号
private String address;//地址
}
public interface UserDao {
/**
* 通过userId查询user信息
* @param userId
* @return
*/
User queryById(int userId);
}
以上是实体类、dao层的设计以及在UserDao.xml中queryById方法的sql语句的编写,因为不论用association的哪种方式,sql语句都是一样的写,不同的只是userMap的写法,所以这里先给出这段代码。User询Card是一对一关系,在数据库中,tb_user表通过外键card_id关联tb_card表。下面分别用association的三种方法来实现queryById用法。
1、第一种用法:实体类各写各的DAO,各写各的*DAO.xml,然后association中使用select
这种用法需要再定义CardDao.java,如下:
public interface CardDao {
Card queryCardById(int cardId);
}
在CardDao.xml中实现该方法:
<select id="queryCardById" parameterType="int" resultType="Card">
SELECT *
FROM tb_card
WHERE card_id=#{cardId}
select>
然后再看UserDao.xml中是如何引用这个方法的:
<resultMap id="userMap标签的id即名字,可随意" type="User查询的主表对应的实体类名称或者实体类路径(如:domain.User)">
<result property="userName" column="user_name"/>
<result property="age" column="age"/>
<association property="card" column="card_id"
select="com.zhu.ssm.dao.CardDao.queryCardById">
association>
resultMap>
在这里直接通过select引用CardDao的queryById方法。个人感觉这种方法比较麻烦,因为还要在CardDao里定义queryCardById方法并且实现再引用才有用,不过这种方法思路清晰,易于理解。
2、第二种方法,嵌套resultMap
<resultMap id="cardMap标签的id即名字,可随意" type="Card查询的主表对应的实体类名称或者实体类路径(如:domain.User)" >
<id property="cardId实体类中表示主键的名称" column="card_id数据库表列名"/>
<result property="cardNum实体类属性" column="card_num数据库表列名"/>
<result property="address" column="address"/>
resultMap>
<resultMap id="userMap" type="User" >
<result property="userName" column="user_name"/>
<result property="age" column="age"/>
<association property="card实体类中表示主键的名称" resultMap="cardMap对另一个实体类的resultMap的引用">
association>
resultMap>
第二种方法就是在UserDao.xml中先定义一个Card的resultMap,然后在User的resultMap的association标签中通过resultMap="cardMap"引用。这种方法相比于第一种方法较为简单。
3、第三种方法:嵌套resultMap简化版
<resultMap type="User" id="userMap">
<result property="userName" column="user_name"/>
<result property="age" column="age"/>
<association property="card实体类中表示主键的名称" column="card_id另一张表的主键名称" javaType="Card另一张表对应的实体类">
<id property="cardId主键对应的实体类属性" column="card_id主键名称"/>
<result property="cardNum实体类属性" column="card_num数据库表列名"/>
<result property="address" column="address"/>
association>
resultMap>
这种方法就把Card的resultMap定义在了association 标签里面,通过javaType来指定是哪个类的resultMap,个人认为这种方法最简单,缺点就是cardMap不能复用。具体用哪种方法,视情况而定。
二、collection的三种用法:
一个土豪有多个手机,看如下代码:
User实体类
public class User{
private Integer userId;
private String userName;
private Integer age;
private List<MobilePhone> mobilePhone;//土豪,多个多机,1对多
}
// 手机类
public class MobilePhone {
private Integer mobilePhoneId;
private String brand;//品牌
private double price;//价格
private User user;//主人
}
// dao层
public interface UserDao {
/**
* 通过userId查询user信息
* @param userId
* @return
*/
User queryById(int userId);
}
UserDao.xml中的select查询语句
<select id="queryById" parameterType="int" resultMap="userMap">
SELECT u.user_name,u.age,
m.brand,m.price
FROM tb_user u,tb_mobile_phone m
WHERE m.user_id=u.user_id
AND
u.user_id=#{userId}
select>
数据库中,tb_mobile_phone中user_id作为外键。那么下面来看resultMap如何定义:
1、第一种方法:用select,跟association 中使用select类似:
先定义 MobilePhoneDao.java
public interface MobilePhoneDao {
List<MobilePhone> queryMbByUserId(int userId);
}
然后实现该方法 MobilePhoneDao.xml
<resultMap type="MobilePhone" id="mobilePhoneMap">
<id property="mobilePhoneId" column="user_id"/>
<result property="brand" column="brand"/>
<result property="price" column="price"/>
<association property="user"column="user_id" select=
"com.zhu.ssm.dao.UserDao.queryById">
association>
resultMap>
<select id="queryMbByUserId" parameterType="int" resultMap="mobilePhoneMap">
SELECT brand,price
FROM tb_mobile_phone
WHERE user_id=#{userId}
select>
做好以上准备工作,那就可以在UserDao.xml中引用了
<resultMap type="User" id="userMap">
<id property="userId" column="user_id"/>
<result property="userName" column="user_name"/>
<result property="age" column="age"/>
<collection property="mobilePhone" column="user_id"
select="com.zhu.ssm.dao.MobilePhoneDao.queryMbByUserId">
collection>
resultMap>
这种方法和association的第一种方法几乎是一样的不同之处就是mobilePhMap中用到了association ,queryMbByUserId中要使用mobilePhoneMap,而不能直接使用resultType。
2、第二种方法:嵌套resultMap
<resultMap type="MobilePhone" id="mobilephoneMap">
<id column="mobile_phone_id" property="mobilePhoneId"/>
<result column="brand" property="brand" />
<result column="price" property="price" />resultMap>
<resultMap type="User" id="userMap">
<result property="userName" column="user_name"/>
<result property="age" column="age"/>
<collection property="mobilePhone" resultMap="mobilephoneMap" >
collection>
resultMap>
定义好这两个resultMap,再引用UserMap就行了。
3、第三种方法:嵌套resultMap简化版
<resultMap type="User" id="userMap">
<result property="userName" column="user_name"/>
<result property="age" column="age"/>
<collection property="mobilePhone"column="user_id"
ofType="MobilePhone另一张表对应的实体类">
<id column="mobile_phone_id" property="mobilePhoneId" />
<result column="brand" property="brand" />
<result column="price" property="price" />
collection>
resultMap>
这种方法需要注意,一定要有ofType,collection 装的元素类型是啥ofType的值就是啥,这个一定不能少。
注意:
所有resultMap中的type、select 标签中的resultType以及association中的javaType另一张表对应的实体类,collection中的ofType另一张表对应的实体类,这里只写了类名,是因为在mybatis-config.xml中配置了typeAliases,否则就要写该类的全类名。配置如下:
<typeAliases>
typeAliases>
总结:
1、association表示的是has one的关系,一对一时使用。user has one card,所以在user的resultMap中接收card时应该用association;
2、collection表示的是has many的关系,一对多时使用。user has many mobilePhone,所以在user的resultMap中接收mobilePhone时应该用collection 。
3、都有三种方法,且非常类似,resultMap要复用建议第二种方法,不需要复用建议第三种方法。
4、特别注意表中主键字段要有所区分,不能都写成id,要写成user_id、card_id,反正要有所区分,不然查询的时候会查不到完整的数据。
首先创建UserDao接口及UsersDaoImpl实现类和映射文件,因为在DaoImpl类里面要与具体的CRUD方法,必然会用到上面提到的3个对象,现在我我们将这三个对象封装到上面说的一个名为BaseDaoImpl类中,所以我们在创建UserDaoImpl类时不但实现UserDaor接口,还要继承BaseDaoImpl类并重写本类的构造方法,然后在构造方法中调用父类的构造方法,这样程序就可以获取Mapper对象了,
//注意此处的UserDao接口要与Mapper文件命名空间一致,
public class UserDaoImpl extends BaseDaoImpl implements UserDao{
public UserDaoImpl(){
super();
this.setMapper(UserDao.class); //这样就指定对应的Mapper映射文件了
}
@Override
public List<Users>getAllUser(){
//通过调用父类的.getMapper()方法可以直接让程序找到对应的映射文件,至于映射文件后面的.getAllUser()用于到Mapper文件中找到具体的SQL语句。
return this.getMapper().getAllUser();//这里的getAllUser是映射配置文件里面具体SQL语句对应的id.
}
}
***-Mapper.xml中“星”号部分建议自已起的名字要和实体类同名,本例建议Users-Mapper.xml
DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.mr.dao.UserDao">
<resultMap type="student" id="onebyone">
<id column="id" property="id"/>
<result column="cnname" property="cnname"/>
<result column="sex" property="sex"/>
<result column="note" property="note"/>
<association property="idCard" javaType="idCard另一张表对应的实体类">
<id column="tss_id" property="id"/>
<result column="native" property="natives"/>
<result column="issue_date" property="issue_date"/>
<result column="end_date" property="end_date"/>
<result column="id" property="student_id"/>
association>
resultMap>
<select id="findById" parameterType="int" resultMap="onebyone">
SELECT
ts.*, tss.id AS tss_id,
tss.native native,
tss.issue_date,
tss.end_date
FROM
t_student ts
INNER JOIN t_student_selfcard tss ON ts.id = tss.student_id
WHERE
ts.id = #{id}
select>
<resultMap type="student" id="onetoMany">
<id column="id" property="id"/>
<result column="cnname" property="cnname"/>
<result column="sex" property="sex"/>
<result column="note" property="note"/>
<collection property="helthInfos" ofType="HelthInfo">
<id column="tshId" property="id"/>
<result column="id" property="student_id"/>
<result column="check_date"property="check_date"/>
<result column="heart" property="heart"/>
<result column="liver" property="liver"/>
collection>
resultMap>
<select id="findHealthInfo" resultMap="onetoMany">
SELECT
ts.*,
tsh.id tshId,
tsh.check_date,
tsh.heart,
tsh.liver,
tsh.spleen,
tsh.lung,
tsh.kidney,
tsh.prostate,
tsh.note as notetsh
FROM
t_student ts
INNER JOIN t_student_health_male tsh
on
tsh.student_id = ts.id where ts.id=#{id}`在这里插入代码片`
select>
mapper>
DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="test">
<select id="queryById" parameterType="int"
resultType="com.woniu.mybatis.entity.User">
SELECT * from t_user where id=#{value}
select>
<select id="queryByName" parameterType="string"
resultType="com.woniu.mybatis.entity.User">
SELECT * from t_user where cnname LIKE '${value}%'
select>
<delete id="deleteById" parameterType="int">
DELETE from t_user where id=#{value}
delete>
<update id="updateUserInfo" parameterType="com.woniu.mybatis.entity.User">
update t_user set cnname=#{cnname},age=#{age} where id=#{id}
update>
<insert id="saveUserInfo" parameterType="com.woniu.mybatis.entity.User">
INSERT INTO t_user(user_name,cnname,sex,mobile,email,note)
VALUES(#{user_name},#{cnname},#{sex},#{mobile},#{email},#{note})
insert>
mapper>
说明:
对于mybatis中#和$绑定参数的区别做个总结。
#{} 将传入的数据都当成一个字符串,会对自动传入的数据加一个双引号。如:order by #{id},如果传入的值是111,那么解析成sql时的值为order by “111”
${} 将传入的数据直接显示生成在sql中。如:order by ${id},如果传入的值是111,那么解析成sql时的值为order by 111, 如果传入的值是id,则解析成的sql为order by id。
-
方式能够很大程度防止sql注入。
- $ 方式无法防止Sql注入。
- $ 方式一般用于传入数据库对象,例如传入表名.
- 一般能用#的就别用$.,可能你会担心传入一个int类型被转化为String类型载入数据库了,不要担心主要你数据表对应的是INT/TNYINT的类型,他主动会转化回来
方法一:
<select id="findUserById" parameterType="int" resultType="fy.po.User">
select * from user where username like '%${value}%' ;
select>
${value}必须是value
调用时:sqlSession.selectList(“test.findUserByUsername”, “张”);
方法二:
<select id="findUserById" parameterType="int" resultType="fy.po.User">
select * from user where username like #{value} ;
select>
调用时:sqlSession.selectList(“test.findUserByUsername”, “%张%”);
#{}和${}
#{}表示一个占位符号,通过#{}可以实现preparedStatement向占位符中设置值,自动进行java类型和jdbc类型转换,#{}可以有效防止sql注入。 #{}可以接收简单类型值或pojo属性值。 如果parameterType传输单个简单类型值,#{}括号中可以是value或其它名称。
表 示 拼 接 s q l 串 , 通 过 {}表示拼接sql串,通过 表示拼接sql串,通过{}可以将parameterType 传入的内容拼接在sql中且不进行jdbc类型转换, 可 以 接 收 简 单 类 型 值 或 p o j o 属 性 值 , 如 果 p a r a m e t e r T y p e 传 输 单 个 简 单 类 型 值 , {}可以接收简单类型值或pojo属性值,如果parameterType传输单个简单类型值, 可以接收简单类型值或pojo属性值,如果parameterType传输单个简单类型值,{}括号中只能是value。
————————————————
2. 接下来实现业务层
到目前为止,持久层和实体类都已经完成了,接下来实现业务层,先创建业务层接口service,再创建业务层的实现类serviceImpl,并在实现类上面写上注解@service(“userService”),在业务层的注解括号里,参数部分要特别声明一个名字,因为稍后在Controller类里创建Service对象的时候要与这个名字相匹配,
业务层的主要工作是获取Dao层的方法并返回给下一层,晃Ctroller控制层。
@Service("userService")
public class UserServiceImpl implement UserService{
@Autowired
UserDao userDao;
@Override
public List<Users>getAllUsers(){
return userDao.getAllUser();
}
}.
3. 创建控制层
Servlet也是控制层,但是属于入侵性的(需要几层的HttpServlet),而SpringMVC则不用了,只需创建一个普通的类就可以了,只是需要用注解在声明 类代码时标注上这是一个控制层
@Controller
public class UserController{
@Autowired
UserService userService;//==userService==即控制层里创建的业务层对象要与业务层@Service(“userService”)参数里面的相同。
}
@Controller // 标识该类为Spring MVC中的handler
@RequestMapping("/UserHandler")//用于设定该控制器的请求路径,
public class UserHandler {
@AutoWired
UserService userService;//业务层对角
@RequestMapping("/login") // 标识url地址的,用于设定该控制器的请求路径,无论是从jsp页面发出的请求还是从其它控制器发出的请求,都要写这个路径UserHandler/login
public String doLogin(HttpServletRequest request, HttpServletResponse response) {
ModelAndView modelAndView=new ModelAndView();
//ListlistUser = userService.getAllUsers();//即调用业务层的方法
//ListlistUser = userService.getUserById(@Param("uId"Integer uId));//即调用业务层的方法,,前台传过来的参数用@Param()注解来获取,注解里面的参数是前台传参数时到用的名字(问号后面的名字),在注解参数外面直接声明变量。这里要注意,如果传递过来的是基本数据类型,那么直接声明该类型的封装类类型,并且声明变量的名字要和注解参数里的名字一样才自动赋值。相当于原来的Integer uId = request.getParameter("uId");
//ModelAndView modelAndView=new ModelAndView("getALL");//采用的是有参构造,直接跳转到此页面。
//modelAndView.addObject("listUser",listUser);
//return mav;
String userName = request.getParameter("userName");
String password = request.getParameter("password");
if ("admin".equals(password) && "admin".equals(userName)) {
return "success";
modelAndView.setViewName("success");//上面配置了视图解析器
} else {
return "fail";// 逻辑视图名
modelAndView.setViewName("fail");
}
return modelAndView;
}
}
以上为注解方式,以下继承类的方式
public class UserController implements Controller {
@Override
public ModelAndView handleRequest(HttpServletRequest request, HttpServletResponse response) throws Exception {
ModelAndView modelAndView=new ModelAndView();//无参构造
String userName = request.getParameter("userName");
String password = request.getParameter("password"); if("admin".equals(password)&&"admin".equals(userName)){
modelAndView.addObject("name","张三");//把我们要存的值存进去。
modelAndView.setViewName("success");//上面配置了视图解析器
modelAndView.setViewName("/Web-INF/view/index.jsp");//上面配置没有配视图解析器
}else{
modelAndView.setViewName("fail");
}
return modelAndView;
}
}
4.jsp页面代码的编写
在index页面中调用上面的Controller
<body>
<input type="button" value="查询所有" onclick="toGetAll()">
body>
<script type = "text/javascript">
funtion.href="UserHandler/login"; //调用控制器里面的方法
script>
下面为getAll.jsp页内容
<body>
<table>
<tr>
<td>序号td>
<td>姓名td>
<td> 年零td>
tr>
<c:forEach items="${listUser}" var = "list">
<tr>
<td>${"list.uId"}td>
<td>${"list.uName"}td>
<td> ${"list.uAge"}td>
tr>
table>
body>
配置SpringMVC
首先我们在\src\main\Webapp\WEB-INF或\src\main\resources下创建名为SpringMVC.xml,在web.xml里面进行调用。配置方式注解方见实站P77.
<beans xmlns="http://www.springframework.org/schema/beans" >
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:mvc="http://www.springframework.org/schema/mvc"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.1.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-4.1.xsd
http://www.springframework.org/schema/mvc
http://www.springframework.org/schema/mvc/spring-mvc-4.1.xsd">
<context:component-scan base-package="com.woniu.springmvc.handler"/>
<bean class="org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerMapping">bean>
<bean class="org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter">bean>
<bean class="org.springframework.web.servlet.view.InternalResourceViewResolver">
<property name="prefix" value="/WEB-INF/views/"/>
或 <property name="prefix" value="/WEB-INF/jsp/"/>
<property name="suffix" value=".jsp"/>
bean>
<bean>
<mvc:resources location="/WEB-INF/JSP" mapping="/jsp/**">
<mvc:resources location="/WEB-INF/JS" mapping="/js/**">
<mvc:resources location="/WEB-INF/css" mapping="/css/**">
<mvc:resources location="/WEB-INF/img" mapping="/img/**">
bean>
<context:component-scan base-package="com.mr.controller"/>
<bean name="/login.do" class="com.woniu.springmvc.handler.UserController"/>
<mvc:annotation-driven />
<mvc:default-servlet-handler/>
beans>
以上5点是一个SpringMVC文件最基本的配置,它们之间没有顺序之分,先 配置什么都可以,接下来完成Controller里面的内容,在前面介绍了Controller替代了原来的Servlet,也就是说Controller的作用是接收前台JSP页面的请求,并返回相应的结果。
在编写控制层的方法之前,先给大家介绍一个类–ModelAndView,它的作用是:业务处理器调用模型层处理完用户请求后,把结果数据存在该类的model属性中,把要返回的视图信息存储在该类的view属性中,然后让该类返回SpringMVC框架,框架通过调用配置文件中定义视图解析器,对该对象进行解析,最后把结果数据显示在指定的页面上。
WEB配置文件
<web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd"
id="WebApp_ID" version="3.1">
<display-name>Shopdisplay-name>
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListenerlistener-class>
listener>
<context-param>
<param-name>contextConfigLocationparam-name>
<param-value>classpath:applicationContext-*.xmlparam-value>
context-param>
<servlet>
<servlet-name>SpringMVCservlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServletservlet-class>
<init-param>
<param-name>contextConfigLocationparam-name>
<param-value>classpath:SpringMVC.xmlparam-value>
init-param>
<load-on-startup>0load-on-startup>
servlet>
<servlet-mapping>
<servlet-name>SpringMVCservlet-name>
<url-pattern>*.dourl-pattern>
<url-pattern>/url-pattern>
servlet-mapping>
<filter>
<filter-name>openSessionInViewFilterfilter-name>
<filter-class>org.springframework.orm.hibernate4.support.OpenSessionInViewFilterfilter-class>
filter>
<filter-mapping>
<filter-name>openSessionInViewFilterfilter-name>
<url-pattern>/*url-pattern>
filter-mapping>
<filter>
<filter-name>struts2filter-name>
<filter-class>org.apache.struts2.dispatcher.filter.StrutsPrepareAndExecuteFilterfilter-class>
<init-param>
<param-name>struts.action.extensionparam-name>
<param-value>htmlparam-value>
init-param>
filter>
<filter-mapping>
<filter-name>struts2filter-name>
<url-pattern>/*url-pattern>
filter-mapping>
<filter>
<filter-name>characterEncodingFilterfilter-name>
<filter-class>org.springframework.web.filter.CharacterEncodingFilterfilter-class>
<init-param>
<param-name>encodingparam-name>
<param-value>UTF-8param-value>
init-param>
<init-param>
<param-name>forceEncodingparam-name>
<param-value>trueparam-value>
init-param>
filter>
<filter-mapping>
<filter-name>characterEncodingFilterfilter-name>
<url-pattern>/*url-pattern>
filter-mapping>
<welcome-file-list>
<welcome-file>index.jspwelcome-file>
welcome-file-list>
web-app>
注解主要给编译器及工具类型的软件用的。注解的提取需要借助于java的反射 技术,反射比较慢,所以注解使用时也需要谨慎计较时间成本。我们写程序时候无论是导入包还是声明对象,有时候会出现黄线,感觉就很难受,@SupperWarings(“all”)注解主要用在取消一些编译器产生的警告对代码左侧行列的遮挡,有时候挡住我们的断点,这个时候就可以在方法上加此注解,all抑制所有警告,boxing抑制装箱、拆箱操作时候的警告,unchecked抑制没进行类型检查操作的警告,unused抑制没被使用过代码警告。
spring @component的作用详细介绍
1、@controller 控制器(注入服务)
2、@service 服务(注入dao),即业务层bean
3、@repository dao(实现dao访问)
4、@component (把普通pojo实例化到spring容器中,相当于配置文件中的)
@Component,@Service,@Controller,@Repository注解的类,并把这些类纳入进spring容器中管理。
下面写这个是引入component的扫描组件
其中base-package为需要扫描的包(含所有子包)
1、@Service用于标注业务层组件 ,分四种情况(1).指定name和type,通过name找 到唯一的bean,找不到抛出异常,如果type和字段类型不一致也会抛出异常。(2)指定name:通过name找到唯一的bean,找不 到抛出异常。(3)指 定type:通过type找到唯一的bean,找不到bean抛出异常。
2、@Controller用于标注控制层组件(如struts中的action,SpringMVC中的控制器)
3、@Repository用于标注数据访问组件,即技久层DAO组件.
4、@Component泛指组件,当组件不好归类的时候,我们可以使用这个注解进行标注。
复制代码
@Service
public class UserServiceImpl implements UserService {
}
@Repository
public class UserDaoImpl implements UserDao {
}
getBean的默认名称是类名(头字母小写),如果想自定义,可以@Service(“***”)这样来指定,这种bean默认是单例的,如果想改变,可以使用
@Service(“beanName”)
@Scope(“prototype”)
public class User {
}
来改变。可以使用以下方式指定初始化方法和销毁方法(方法名任意):
@PostConstruct
public void init() {
}
关于mybatis注解之@alias别名用法
Springboot 整合mybatis的时候,关于别名的用法,以后在Mapper文件中直接调用这个名字而无须写类名及完整类名。为国我们在Spring的配置文件中已经完成了相关配置。
此处列举比较常见的两种用法
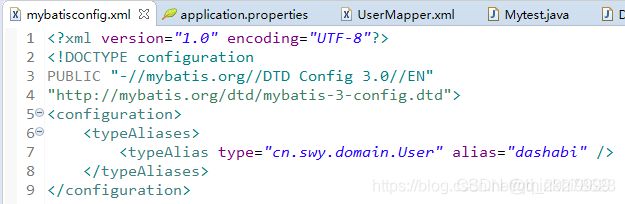
1.配置文件定义别名

如图所示:映射所需实体的类名
2.实体类注解别名

如图所示:实体类直接加注解

这样Mapper.xml中的返回值就直接可以用你自己定义的别名了。个人认为别名还是直接加在实体比较方便,但是配置文件更加利于查看一览。
@Scope注解的作用详解
@Scope默认是单例模式,即scope=“singleton”。另外scope还有prototype、request、session、global session作用域。scope="prototype"多例
例:@scope默认是单例模式(singleton)即:@scope(“prototype”)
1.singleton单例模式,
全局有且仅有一个实例
2.prototype原型模式,
每次获取Bean的时候会有一个新的实例
3.request
request表示该针对每一次HTTP请求都会产生一个新的bean,同时该bean仅在当前HTTP request内有效,
4.session
session作用域表示该针对每一次HTTP请求都会产生一个新的bean,同时该bean仅在当前HTTP session内有效
5.global session
global session作用域类似于标准的HTTP Session作用域,不过它仅仅在基于portlet的web应用中才有意义。Portlet规范定义了全局Session的概念,它被所有构成某个 portlet web应用的各种不同的portlet所共享。在global session作用域中定义的bean被限定于全局portlet Session的生命周期范围内。如果你在web中使用global session作用域来标识bean,那么web会自动当成session类型来使用。
request、session、global session使用的时候首先要在初始化web的web.xml中做如下配置:
如果你使用的是Servlet 2.4及以上的web容器,那么你仅需要在web应用的XML声明文件web.xml中增加下述ContextListener即可:
<web-app>
...
<listener>
<listener-class>org.springframework.web.context.request.RequestContextListenerlistener-class>
listener>
...
web-app>
但是最常用的一般会使用上面1和2两种
@Autowired 的作用是什么?不用自已创建对象了,这项工作交给Spring来完成。功能就是为我们注入一个定义好的bean.
@Autowired 是一个注释,它可以对类成员变量、方法及构造函数进行标注,让 spring 完成 bean 自动装配的工作。
@Autowired 默认是按照类去匹配,如果想使用名称装配可以配合 @Qualifier 指定按照名称去装配 bean。
使用方法:
方式一:成员属性字段使用 @Autowired,无需字段的 set 方法

方式二:set 方法使用 @Autowired
private ArticleService articleService;
@Autowired
public void setArticleService(ArticleService articleService) {
this.articleService = articleService;
}
**方式三:构造方法使用 @Autowired
private TagService tagService;
@Autowired
public TestController(TagService tagService) {
this.tagService = tagService;
}
@Autowired @Qualifier("tagService")
private TagService tagService;
等价于@Resource(name = "tagService")
private TagService tagService;
————————————————
@Override注解
表标重写(当然不写也可以覆盖),加上后会额外检测覆盖前后方法的参数类型是否相同,有如下好处:1.告诉读代码的人,这是一个复写方法,可当注解用,方便阅读。2.帮助自已检查是否正确的复写了父类中已有的方法和参数类型。
@WebServlet(“/DemoServlet”)
说明是Servlet3.0技术,也就是使用注解的方式实现URL映射,但2.0中是在Web.xml中进行配置。
<servlet>
<servlet-names>simpleServletservlet>
<servlet-class>Com.mr.SimpleServletservlet-class>
servlet>
<servlet-mapping>
<servlet-name>SimpleServletservlet-name>
<url-pattern>/DemoServlet url-pattern>
servlet-mapping>
@RequestMapping(“/hello”)
@RequestMapping(“/hello”)用这个路径来访问这个方法即采用springmvc的方法。
@ResponseBody
return “hello”;这个hello我们默认返回一个字符串json格式,而如果没有@ResponseBody是跳转到一个html页面,这就是有没有这个区别。
@RsetController
是一个组合注解 <=>@Controller+@Responsebody,用于将返回的结果放入Response Body。
认识Junit基本注解@Before、@After、@Test、@BeforeClass、@AfterClass(转)
一、unit中集中基本注解,是必须掌握的。
@BeforeClass – 表示在类中的任意public static void方法执行之前执行
@AfterClass – 表示在类中的任意public static void方法执行之后执行
@Before – 表示在任意使用@Test注解标注的public void方法执行之前执行
@After – 表示在任意使用@Test注解标注的public void方法执行之后执行
@Test – 使用该注解标注的public void方法会表示为一个测试方法
二、使用示例
【code】
package org.byron4j.spring_mvc_log4j;
import org.junit.After;
import org.junit.AfterClass;
import org.junit.Before;
import org.junit.BeforeClass;
import org.junit.Test;
public class BasicAnnotationTest {
// Run once, e.g. Database connection, connection pool
@BeforeClass
public static void runOnceBeforeClass() {
System.out.println("@BeforeClass - runOnceBeforeClass");
}
// Run once, e.g close connection, cleanup
@AfterClass
public static void runOnceAfterClass() {
System.out.println("@AfterClass - runOnceAfterClass");
}
// Should rename to @BeforeTestMethod
// e.g. Creating an similar object and share for all @Test
@Before
public void runBeforeTestMethod() {
System.out.println("@Before - runBeforeTestMethod");
}
// Should rename to @AfterTestMethod
@After
public void runAfterTestMethod() {
System.out.println("@After - runAfterTestMethod");
}
@Test
public void test_method_1() {
System.out.println("@Test - test_method_1");
}
@Test
public void test_method_2() {
System.out.println("@Test - test_method_2");
}
}
【输出】
@BeforeClass - runOnceBeforeClass
@Before - runBeforeTestMethod
@Test - test_method_1
@After - runAfterTestMethod
@Before - runBeforeTestMethod
@Test - test_method_2
@After - runAfterTestMethod
@AfterClass - runOnceAfterClass
补充知识
标准主流现在编程方式都是采用MVC综合设计模式,MVC本身不属于设计模式的一种,它描述的是一种结构,最终目的达到解耦,解耦说的意思是你更改某一层代码,不会影响我其它层代码,如果你会像Spring这样的框架,你会了解面向接口编程,表示层调用控制层,控制层调用业务层,业务层调用数据访问层。如果不使用任何框架,而单纯使用Servlet和JDBC技术,甚至只用JSP技术,同样可以实现JAVAWEB的项目开发,但这样的项目具体工作码量大,代码之间的耦合性极强,如果需要调整某一功能 ,出于连锁反应,可能要修改所有的源代码文件,这样的项目 维护起来存在极大的风险隐患。使用框 加可以省去很多繁琐,重复的代码操作,又大大降低了代码之间的耦合性,使用各种框架来搭建WEB项目已成为当今程序开发的注流。
MQ:MessageQueue消息对列,目前比较成熟的有RoketMQ,RabbitMQ,kafka
RocketMQ:低延迟,高性能和高可靠性,万亿级容量,同时具备灵活,可伸缩性强的分布式处理平台,由四部分组成:nameServers,brokers,producters,consumers,他们所有部分可以水平扩展,避免单点故障,
名称服务NameServer主要包括两个功能1.broker管理,NameServer接受来自brokerw集群的注册信息并提供心跳来检测他们是否可用,2.路由管理:每个NameServer都持有关于broke集群和队列的全部路由信息,用来向客户端提供查询。代理服务(brokerServer)负责消息的存储伟递,消息查询,保证高可用等,主从broker数据同步。
大数据主要技术组件:Hadoop,HBase,Kafka,hive,mangDB,Redis,Spark,