Class-Balanced Loss Based on Effective Number of Samples
论文标题:Class-Balanced Loss Based on Effective Number of Samples
会议:CVPR2019
pytorch版代码-GitHub地址:https://github.com/vandit15/Class-balanced-loss-pytorch/blob/master/class_balanced_loss.py
论文下载:https://arxiv.org/pdf/1901.05555.pdf
cifar10的训练代码在另一篇博客中:pytorch+resnet18实现长尾数据集分类
类别不平衡问题
现实世界的数据集,大部分都是分布不均匀的,几个主导类别拥有大量样本,而大多数其他的类别只有着相对较少的样本。使用这种长尾数据集训练CNNs时,模型在弱表示类中表现较差。
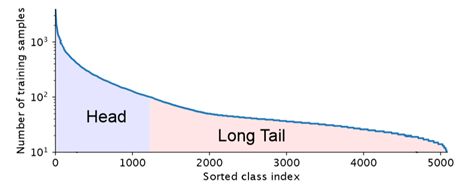
类别不平衡的处理策略:
通常情况下,对于长尾数据集,有以下两种应对策略
1.重新采样 理论及代码链接
上采样:人工合成/复制数据
上采样缺点:如果是复制小类样本,新增数据与原数据的特征高度相似,没有本质上的性能提升,容易造成模型过拟合。如果对小类样本进行合成(如SMOTE算法),由于新样本中存在噪声,模型仍然容易出错。
下采样:按照概率随机抽样,相当于删除大类样本中的一些样本。
下采样缺点:数据量减少,模型对于多样本类别的分类性能降低。
2.成本敏感学习
在这个方法中,为了匹配给定的数据分布,为样本分配权重。通常采用逆类频率加权或逆类频率的平方根的加权。但是样本难度与样本数量之间并没有直接的联系(比如,A类样本,数据量为2000,但是有1500张数据是类似的;B类样本,数据量为1000,数据都不相同,那么A类样本难度比B类样本难度低),这样简单粗暴的分配权重并没有对数据集的特征进行分析,该方法存在改进空间。
提出问题
如何找到合适的权重赋值方法,提高分类损失函数的效果?
边际效应
随着数据量增加,模型新增的收益越来越少
刚开始接收新数据的时候,网络能够很快学习特征。但是随着数据量的增加,新加入的数据,与之前的已有的数据存在特征重叠,新学到的特征越来越少。

数据采样和随机覆盖
一个类中,该类样本空间中所有可能数据的集合为 S S S。假设, S S S 的样本体积为 N N N。 S S S 中每个样本的体积都为1,但是由于样本存在特征重叠,所以两个样本的体积满足:1+1<=2。将数据采样过程考虑为一个随机覆盖问题,其中每个数据从 S S S 中随机抽样以覆盖整个 S S S 。抽样的数据越多, S S S 的覆盖越好。采样数据的期望总容量随着数据数量的增加而增加,并以 N N N为界。只要这一段理解了,后面就简单了。
定义
有效样本量是样本的期望体积
之前已经提到过样本体积的概念,样本体积是相对于所有可能数据的集合 S S S而言的, S S S为一个理论概念。在真实的样本中,由于存在特征重叠,所以有些样本是多余的,可以通过其他样本得到。这有点类似于线性代数中的极大无关组。我们把那些独一无二的样本的集合称为有效样本量,也就是样本的期望体积。对于独一无二的样本:1+1=2。
注意区分样本的期望体积和样本体积。
命题
计算有效样本量的方法:
提出公式: E n = ( 1 − β n ) / ( 1 − β ) E_{n}=\left(1-\beta^{n}\right) /(1-\beta) En=(1−βn)/(1−β)
其中 n n n为样本数量, N N N 为样本体积, β = ( N − 1 ) / N \beta=(N-1) / N β=(N−1)/N。
作者使用了数学归纳法证明命题正确。
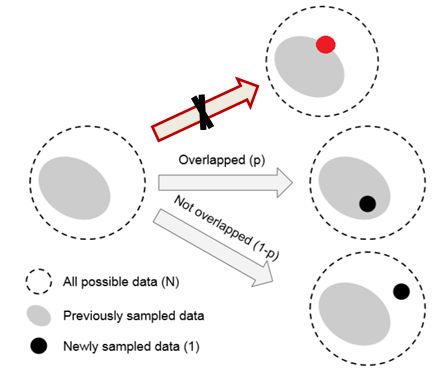
n n n 为1时: E 1 = ( 1 − β 1 ) / ( 1 − β ) = 1 E_{1}=\left(1-\beta^{1}\right) /(1-\beta)=1 E1=(1−β1)/(1−β)=1
假设 E n − 1 = ( 1 − β n − 1 ) / ( 1 − β ) E_{n-1}=\left(1-\beta^{n-1}\right) /(1-\beta) En−1=(1−βn−1)/(1−β)成立,第 n n n 个采样数据与前 n − 1 n-1 n−1 个数据重叠的概率为: p = E n − 1 / N p=E_{n-1} / N p=En−1/N
重叠情况下,这 n n n 个采样数据的样本体积为 E n − 1 E_{n-1} En−1;
未重叠情况下,这 n n n 个采样数据的样本体积为 E n − 1 + 1 E_{n-1} + 1 En−1+1
由于部分重叠情况复杂,作者表示不予考虑。这时,有效样本量为:
E n = p E n − 1 + ( 1 − p ) ( E n − 1 + 1 ) E_{n}=p E_{n-1}+(1-p)\left(E_{n-1}+1\right) En=pEn−1+(1−p)(En−1+1)
= ( 1 − β n ) / ( 1 − β ) = ∑ j = 1 n β j − 1 =\left(1-\beta^{n}\right) /(1-\beta)=\sum_{j=1}^{n} \beta^{j-1} =(1−βn)/(1−β)=∑j=1nβj−1
n → ∞ , E n = 1 / ( 1 − β ) = N \mathrm{n} \rightarrow \infty, E_{n}=1 /(1-\beta)=\mathrm{N} n→∞,En=1/(1−β)=N,意味着样本中采样的样本足够多时,有效样本量数目等于样本体积。同时也符合之前 β \beta β的计算公式。
推论:渐近性
β = 0 ( N = 1 ) , E n = 1 \beta=0(N=1), \quad E_{n}=1 β=0(N=1),En=1
β → 1 ( N → ∞ ) , E n → n \beta \rightarrow 1(N \rightarrow \infty), \quad E_{n} \rightarrow n β→1(N→∞),En→n
证明:
β = 0 , E n = ( 1 − 0 n ) / ( 1 − 0 ) = 1 \beta=0, \quad E_{n}=\left(1-0^{n}\right) /(1-0)=1 β=0,En=(1−0n)/(1−0)=1
β → 1 , \beta \rightarrow 1, \quad β→1, 令 f ( β ) = 1 − β n , g ( β ) = 1 − β f(\beta)=1-\beta^{n}, g(\beta)=1-\beta f(β)=1−βn,g(β)=1−β
lim β → 1 f ( β ) = lim β → 1 g ( β ) = 0 \lim _{\beta \rightarrow 1} f(\beta)=\lim _{\beta \rightarrow 1} g(\beta)=0 limβ→1f(β)=limβ→1g(β)=0
根据 洛必达法则: E n = n E_{n}=n En=n
说明样本体积 N N N 足够大,有效样本数和采样的样本数相等
类平衡损失函数
原文说到:
The proposed effective number of samples for class i i i is E n i = ( 1 − β i n i ) / ( 1 − β i ) , E_{n_{i}}=\left(1-\beta_{i}^{n_{i}}\right) /\left(1-\beta_{i}\right), Eni=(1−βini)/(1−βi), where β i = ( N i − 1 ) / N i . \beta_{i}=\left(N_{i}-1\right) / N_{i} . βi=(Ni−1)/Ni. Without further information of data for each class, it is difficult to empirically find a set of good hyperparameters N i N_{i} Ni for all classes. Therefore, in practice, we assume N i N_{i} Ni is only dataset-dependent and set N i = N , β i = β = ( N − 1 ) / N N_{i}=N, \beta_{i}=\beta=(N-1) / N Ni=N,βi=β=(N−1)/N for all classes in a dataset.
说白了就是,目前做不到给每个类都找到超参数 N i N_{i} Ni,所以,决定对于整个样本中,每个类的 N i N_{i} Ni都统一设置为 N N N,简单粗暴,至于 N i N_{i} Ni怎么办,发完这篇论文,以后再去研究。
类平衡损失函数:
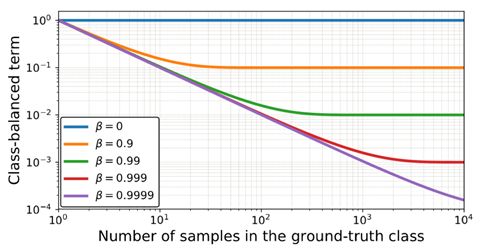
C B ( p , y ) = 1 E n L ( p , y ) = 1 − β 1 − β n y L ( p , y ) \mathrm{CB}(\mathrm{p}, y)=\frac{1}{E_{n}} L(\mathrm{p}, y)=\frac{1-\beta}{1-\beta^{n} y} L(\mathrm{p}, y) CB(p,y)=En1L(p,y)=1−βny1−βL(p,y)
其中, 1 E n \frac{1}{E_{n}} En1为类平衡因子, L ( p , y ) L(\mathrm{p}, y) L(p,y) 为通用损失函数,可以使用常用的分类损失函数(softmax,sigmoid,focal loss等)替换。
- Softmax: C E s o f t m a x ( z , y ) = − 1 − β 1 − β n y log ( exp ( z y ) ∑ j = 1 C exp ( z j ) ) . \mathrm{CE}_{\mathrm{softmax}}(\mathrm{z}, y)=-\frac{1-\beta}{1-\beta^{n_{y}}} \log \left(\frac{\exp \left(z_{y}\right)}{\sum_{j=1}^{C} \exp \left(z_{j}\right)}\right). CEsoftmax(z,y)=−1−βny1−βlog(∑j=1Cexp(zj)exp(zy)).
- Sigmoid: C B sigmoid ( z , y ) = − 1 − β 1 − β n y ∑ i = 1 C log ( 1 1 + exp ( − z i t ) ) \quad \mathrm{CB}_{\text {sigmoid }}(\mathrm{z}, y)=-\frac{1-\beta}{1-\beta^{n_{y}}} \sum_{i=1}^{C} \log \left(\frac{1}{1+\exp \left(-z_{i}^{t}\right)}\right) CBsigmoid (z,y)=−1−βny1−β∑i=1Clog(1+exp(−zit)1)
- Focal loss:
原始focal loss为: \quad Focal ( z , y ) = − α t ( 1 − p t ) γ log ( p t ) (\mathrm{z}, y) \quad=-\alpha_{\mathrm{t}}\left(1-p_{t}\right)^{\gamma} \log \left(p_{t}\right) (z,y)=−αt(1−pt)γlog(pt)
改进后focal loss: \quad C B focal ( z , y ) = − 1 − β 1 − β n y ∑ i = 1 C ( 1 − p i t ) γ log ( p i t ) \mathrm{CB}_{\text {focal }}(\mathrm{z}, y)=-\frac{1-\beta}{1-\beta^{n} y} \sum_{i=1}^{C}\left(1-p_{i}^{t}\right)^{\gamma} \log \left(p_{i}^{t}\right) CBfocal (z,y)=−1−βny1−β∑i=1C(1−pit)γlog(pit)
实验数据

CIFAR-10和CIFAR-100都是平衡数据集,作者通过删减数据的方式,将其变为长尾数据集。
实验结果1(小数据集)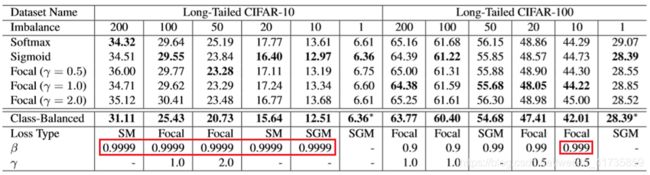
实验分析1
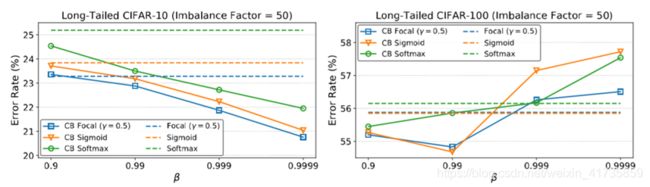
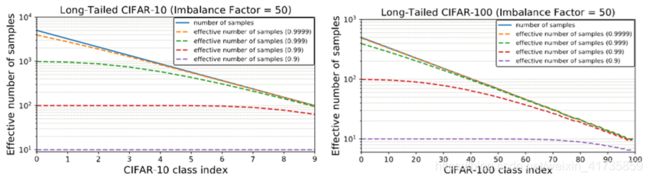
实验结果2(大数据集)
实验分析2

结论
- 论文从定义,命题,推论,实验中充分说明了作者提出的类别不平衡因子的有效性。
- 论文也有许多不足之处,虽然理论部分提出并证明了样本体积 N N N,以及参数 β β β。但是在实验部分,却并没有找到合适的方法去计算出样本体积,只是草率地将 β β β设置为超参数进行实验。寻找适合不同样本的自适应 β β β成为了作者的下一步工作。
论文解读应该存在问题,望指正!!!
参考链接:
论文翻译参考链接