Jetson nano部署YOLOv7
目录
-
- 前言
- 一、YOLOv7模型训练
-
- 1. 项目的克隆和必要的环境依赖
-
- 1.1 项目的克隆
- 1.2 项目代码结构整体介绍
- 1.3 环境安装
- 2. 数据集和预训练权重的准备
-
- 2.1 数据集
- 2.2 预训练权重准备
- 3 训练模型
-
- 3.1 修改模型配置文件
- 3.2 修改数据配置文件
- 3.3 训练模型
- 3.4 推理测试
- 二、YOLOv7模型部署
-
- 1. 源码下载
- 2. 环境配置
-
- 2.1 Jtop(option)
-
- 2.1.1 配置pip
- 2.1.2 安装jtop
- 2.1.3 使用jtop
- 2.2 编译Protobuf
-
- 2.2.1 解压
- 2.2.2 编译
- 2.2.3 安装
- 2.2.4 环境配置(option)
- 2.3 配置CMakeLists.txt
- 3. ONNX导出
-
- 3.1 源码下载
- 3.2 修改代码
- 3.3 导出ONNX模型
- 3.4 拓展-正确导出ONNX文件
- 4. 运行
-
- 4.1 源码修改
- 4.2 编译
- 4.3 模型构建和推理
- 4.4 拓展-摄像头检测
- 结语
- 下载链接
- 参考
前言
yolov7模型部署流程和yolov5几乎完全一致,大家可以先查看我之前的Jetson嵌入式系列模型部署教程。考虑到nano的算力,这里采用yolov7-tiny.pt模型,本文主要分享yolov7模型训练和jetson nano部署yolov7模型两方面的内容。若有问题欢迎各位看官批评指正!!!
一、YOLOv7模型训练
yolov7的代码风格和yolov5非常像,训练流程可参考yolov5的训练。博主主要参考炮哥带你学的利用yolov5训练自己的目标检测模型以及深度学习麋了鹿的yolov7训练测试自己的数据集
1. 项目的克隆和必要的环境依赖
1.1 项目的克隆
yolov7的代码是开源的可直接从github官网上下载,源码下载地址是https://github.com/WongKinYiu/yolov7,由于yolov7刚发布不久目前就只固定v0.1一个版本,而v0.1版本并未提供训练的详细说明,故采用主分支进行模型的训练和部署工作。Linux下代码克隆指令如下
git clone https://github.com/WongKinYiu/yolov7.git
也可手动点击下载,点击右上角的绿色的Code按键,将代码下载下来。至此整个项目就已经准备好了。也可以点击here[password:yolo]下载博主准备好的代码(注意该代码下载于2022/8/31日,若有改动请参考最新)
1.2 项目代码结构整体介绍
将下载后的yolov7的代码解压,其代码目录如下图
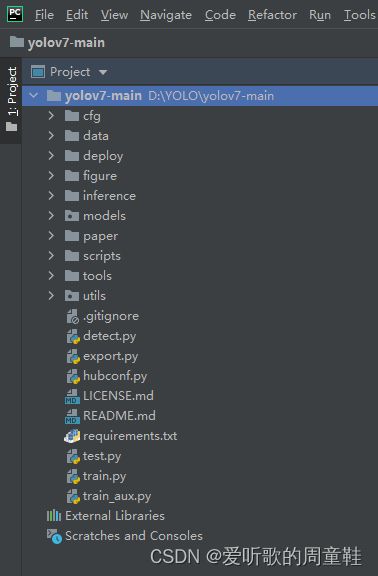
现在来对代码的整体目录做一个介绍
- |-cfg:存放yolov7不同模型的yaml文件,如yolov7.yaml、yolov7-tiny.yaml等,包括训练和部署时的yolov7模型yaml
- |-data:存放一些超参数的配置文件以及配置训练集和验证集路径的coco.yaml文件,如果需要修改自己的数据集,那么需要修改其中的yaml文件
- |-deploy:针对部署的文件夹
- |-figure:存放yolov7测试的效果图片
- |-inference:存放推理时的图片
- |-models:存放yolov7整体网络模型搭建的py文件
- |-paper:存放yolov7论文
- |-scripts:脚本文件,用于获取coco数据集
- |-tools:该文件夹主要存放一些示例教程,如yolov7关键点检测、yolov7实例分割、yolov7onnx等等
- |-utils:存放工具类函数,包括loss、metrics、plots函数等
- |-
- detect.py:检测代码,包括图像检测、视频流检测等
- export.py:模型导出代码,如onnx导出
- hubconf.py:pytorch扩展模型
- requirements.txt:文本文件,里面包含使用yolov7项目的环境依赖包以及相应的版本号
- test.py:测试代码
- train.py:训练代码
- train_aux.py:训练辅助头代码(不确定)
1.3 环境安装
关于深度学习的环境安装可参考炮哥的利用Anaconda安装pytorch和paddle深度学习环境+pycharm安装—免额外安装CUDA和cudnn(适合小白的保姆级教学),这里不再赘述。如果之前配置过yolov5的环境,yolov7可直接使用。
2. 数据集和预训练权重的准备
2.1 数据集
这里采用的数据集是口罩识别,来源于B站UP主HamlinZheng的口罩识别数据集,这里给出下载链接Baidu Drive[password:yolo],博主将原数据集整合了下,方便后续的训练,解压后整个数据集目录结构如下
VOCdevkit
└─VOC2007
├─Annotations
└─JPEGImages
其中JPEGImages中存放的是图像文件,Annotations存放的是对应的XML标签文件。关于标签的制作可参考B站UP主霹雳吧啦Wz的PASCAL VOC2012数据集讲解与制作自己的数据集,由于labelimg标注的是VOC格式标签的XML文件,需要转化为YOLO格式标签的txt文件,关于转换的代码可参考炮哥的目标检测—数据集格式转化及训练集和验证集划分,下面给出VOC格式转YOLO格式的代码:
# voc2yolo.py
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
# 1. 修改为自制数据集需检测的类别数
classes = ["have_mask", "no_mask"]
# 2. 训练集和验证集的比例
TRAIN_RATIO = 80
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' % image_id)
out_file = open('VOCdevkit/VOC2007/YOLOLabels/%s.txt' % image_id, 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "VOCdevkit/")
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image files
prob = random.randint(1, 100)
print("Probability: %d" % prob)
for i in range(0, len(list_imgs)):
path = os.path.join(image_dir, list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
prob = random.randint(1, 100)
print("Probability: %d" % prob)
if (prob < TRAIN_RATIO): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
else: # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()
代码总共需要修改两处
- 第11行,修改要检测的类别名称
- 第14行,修改训练集和验证集的划分比例
整个目录结构如下,注意voc2yolo.py与VOCdevkit处于同一级目录
VOCdevkit
└─VOC2007
├─Annotations
└─JPEGImages
voc2yolo.py
注:目录结构一定要与博主的一致,因为程序已经将对应目录写死。
运行voc2yolo.py代码之后得到如下结果

可以看到目录下有一些新的文件生成,首先VOCdevkit文件夹下分别生成了images和labels文件夹,分别存放着图像和对应的yolo格式的标签文件,每个文件夹下分别包含train和val两个子文件夹,代表各自对应的训练集和验证集。VOC2007文件夹下生成了YOLOLabels文件夹,存放着对应yolo格式的标签文件。然后还生成了yolov5_train.txt以及yolov5_val.txt两个txt文件,存放着训练集和验证集图片的完整路径。yolov7的训练只需要VOCdevkit目录下的images和labels两个文件夹,其它均不需要,故最终的目录结构如下
VOCdevkit
├─images
│ ├─train
│ └─val
└─labels
├─train
└─val
至此,数据集的准备工作完毕。
2.2 预训练权重准备
yolov7预训练权重可以通过here下载,博主也提供下载好的两个预训练权重Baidu Drive[password:yolo],注意这是yolov7-v0.1版本的预训练权重,若后续有版本更新,记得替换。本次训练自己的数据集使用的预训练权重为yolov7-tiny.pt。
3 训练模型
将准备好的数据集文件夹即VOCdevkit复制到yolov7项目环境中,将准备好的预训练权重yolov7-tiny.pt复制到yolov7项目环境中,完整的项目结构如下图所示。训练目标检测模型主要修改cfg文件夹下的模型配置文件yolov7-tiny.ymal以及data文件夹下的数据配置文件coco.yaml

3.1 修改模型配置文件
由于该项目使用的是yolov7-tiny.pt这个预训练权重,所有需要使用cfg/training目录下的yolov7-tiny.yaml这个文件夹(由于不同的预训练权重对应不同的网络结构,所以用错预训练权重会报错)。主要修改yolov7-tiny.yaml文件的第二行,即需要识别的类别数,由于这里识别佩戴口罩和不佩戴口罩两个类别,故修改为2即可,如下所示

3.2 修改数据配置文件
修改data目录下相应的yaml文件,找到目录下的coco.yaml文件,主要修改如下
- 1.注释第4行
- 2.修改第7行训练集的路径
- 3.修改第8行验证集的路径
- 4.注释第9行,因为未使用到测试集
- 5.修改第12行需要检测的类别数个数
- 6.修改第15行需要检测的类别数名称

3.3 训练模型
在终端执行如下指令即可开始训练,参考自yolov7的README.md/Training
python train.py --workers 8 --device 0 --batch-size 32 --data data/coco.yaml --img 640 640 --cfg cfg/training/yolov7-tiny.yaml --weights 'yolov7-tiny.pt' --name yolov7 --hyp data/hyp.scratch.p5.yaml
博主训练的模型为p5 models且使用的是单个GPU进行训练,显卡为2080Ti,操作系统为Ubuntu20.04,pytorch版本为1.7,训练时长大概1个小时。训练参数的指定和yolov5差不多,简要解释如下:
- –workers 最大工作核心数
- –device 指定训练的设备,cpu,0(代表第一个gpu设备)
- –batch-size 每次输入到网络的图片数
- –data 数据配置文件的路径
- –img 输入图像的尺寸
- –cfg 模型配置文件路径
- –weights 预训练权重路径
- –name 训练保存的文件夹名字
- –hyp 超参数文件路径
还有其它参数博主并未设置,如–epochs训练轮数等。大家一定要根据自己的实际情况(如显卡算力)指定不同的参数,如果你之前训练过yolov5,那我相信这对你来说应该是小case
训练完成后的模型权重保存在run/train/weights文件夹下,和yolov5不同的是它保存了多个权重文件,使用best.pt进行后续模型部署即可,这里提供博主训练好的权重文件下载链接Baidu Drive[password:yolo]
3.4 推理测试
利用项目中的detect.py文件进行测试,将需要推理的图片放入inference/images文件夹下,执行指令如下
python detect.py --weights runs/train/yolov7/weights/best.pt --conf 0.25 --img-size 640 --source inference/images/mask.png
推理完成后在run下面会生成一个detect目录,推理的结果保存在exp目录下,推理结果如下所示


也可进行视频或者摄像头推理,执行指令如下,0代表本地摄像头
python detect.py --weights runs/train/yolov7/weights/best.pt --conf 0.25 --img-size 640 --source 0
至此,yolov7模型训练已经完毕,下面开始jetson nano上的模型部署工作。
二、YOLOv7模型部署
Jetson nano上yolov7模型部署流程和yolov5基本一致,大家可以参考我之前发的Jetson嵌入式系列模型部署文章,在这里再重新copy一下吧,部署使用到的Github仓库是tensorRT_Pro。该仓库通过
TensorRT的ONNX parser解析ONNX文件来完成模型的构建工作。对模型部署有疑问的可以参考Jetson嵌入式系列模型部署-1,想了解通过TensorRT的Layer API一层层完成模型的搭建工作可参考Jetson嵌入式系列模型部署-2。本文主要是针对于tensorRT_Pro项目中的yolov7完成嵌入式模型部署,本文参考自tensorRT_Pro的README.md,具体操作流程作者描述非常详细,这里再简单过一遍,本次训练的模型使用yolov7-tiny,类别数为2,为口罩识别。
1. 源码下载
使用如下指令
$ git clone https://github.com/shouxieai/tensorRT_Pro.git
文件较大下载可能比较慢,给出下载好的源码链接Baidu Drive[password:yolo],若有改动请参考最新
删除不必要的文件,给出简化后的源码链接Baidu Drive[password:yolo],若有改动请参考最新
2. 环境配置
需要使用的软件环境有
TensorRT、CUDA、CUDNN、OpenCV、Protobuf。前四个软件环境在JetPack镜像中已经安装完成,故只需要配置protobuf即可。博主使用的jetpack版本为JetPack4.6.1(PS:关于jetson nano刷机就不再赘述了,需要各位看官自行配置好相关环境,外网访问较慢,这里提供Jetson nano的JetPack镜像下载链接Baidu Drive[password:nano]【更新完毕!!!】(PS:提供4.6和4.6.1两个版本,注意4GB和2GB的区别,不要刷错了),关于Jetson Nano 2GB和4GB的区别可参考链接Jetson NANO是什么?如何选?。(吐槽下这玩意上传忒慢了,超级会员不顶用呀,终于上传完了,折磨!!!)
2.1 Jtop(option)
可使用如下指令查看自己的JetPack版本简单信息
$ cat /etc/nv_tegra_release
使用Jtop可查看JetPack详细信息。Jtop是一个由第三方开发,用于显示Jetson开发板信息的包,可以查询当前板子CPU,GPU使用率,实时功耗,Jetpack软件包信息等,参考自Jetson nano安装jtop,Jetson nano安装pip并换源
2.1.1 配置pip
$ sudo apt install python-pip python3-pip
$ pip3 install --upgrade pip
$ pip install --upgrade pip
pip换源,指令如下
$ sudo mkdir .pip && cd .pip
$ sudo touch pip.conf
$ sudo vim pip.conf
添加如下内容
[global]
timeout = 6000
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
trusted-host = pypi.tuna.tsinghua.edu.cn
2.1.2 安装jtop
$ sudo pip3 install -U jetson-stats
2.1.3 使用jtop
$ sudo jtop
The jetson_stats.service is not active. Please run:
sudo systemctl restart jetson_stats.service
需要启动相关服务,指令如下
$ sudo systemctl restart jetson_stats.service
$ jtop
博主Jtop显示的jetson nano软件包信息页面如下

2.2 编译Protobuf
tensorRT_Pro需要Protobuf用于ONNX解析器,需要下载并编译protobuf源码。这里使用的protobuf版本为3.11.4,若需要修改为其他版本,请参照README/环境配置/适配Protobuf版本。关于protobuf的相关介绍请参考protubuf简介,给出protobuf的安装包下载链接Baidu Drive[password:yolo]。参考自Linux下编译protobuf,Linux下添加protobuf环境变量
2.2.1 解压
$ mkdir protobuf-3.11.4 && cd protobuf-3.11.4 // 创建protobuf编译的文件夹
$ uzip protobuf-3.11.4.zip // 解压protobuf压缩包
2.2.2 编译
$ cd protobuf-3.11.4/cmake
$ cmake . -Dprotobuf_BUILD_TESTS=OFF
$ cmake --build .
2.2.3 安装
$ mkdir protobuf // 创建protobuf安装的文件夹
$ make install DESTDIR=/home/nvidia/protobuf // 指定protobuf安装的路径
注:编译完成之后protobuf文件夹下仅仅只有user一个文件夹,需要将编译好的protobuf/user/local下的bin、include、lib文件夹复制到protobuf当前文件夹下,方便后续tensorRT_Pro项目CMakeLists.txt的指定。
2.2.4 环境配置(option)
-
配置环境变量
$ sudo vim /etc/profile添加如下内容保存并退出,注意路径修改为自己的路径
export PATH=$PATH:/home/nvidia/protobuf/bin export PKG_CONFIG_PATH=/home/nvidia/protobuf/lib/pkgconfig/source生效
$ source /etc/profile -
配置动态路径
$ sudo vim /etc/ld.so.conf追加如下内容,注意路径修改为自己的路径
/home/nvidia/protobuf/lib -
验证
protoc --version输出对应版本信息说明安装成功
2.3 配置CMakeLists.txt
主要修改三处
-
- 修改第10行,选择不支持python(也可选择支持)
set(HAS_PYTHON OFF) -
- 修改第20行,修改CUDA路径
set(CUDA_TOOLKIT_ROOT_DIR "usr/local/cuda-10.2") -
- 修改第33行,修改自编译的protobuf的路径

3. ONNX导出
- 训练的模型使用yolov7-tiny,torch版本1.7
- 参考自tensorRT_Pro/README/各项任务支持/YoloV7支持,导出细节的说明已经非常详细了,这里简单过一遍
3.1 源码下载
$ git clone https://github.com/WongKinYiu/yolov7.git
并将训练好的权重文件复制到yolov7文件夹中,给出权重下载链接Baidu Drive[password:yolo]
3.2 修改代码
主要修改以下两个文件的内容
- 1. yolov7/models/yolo.py
- 2. yolov7/export.py
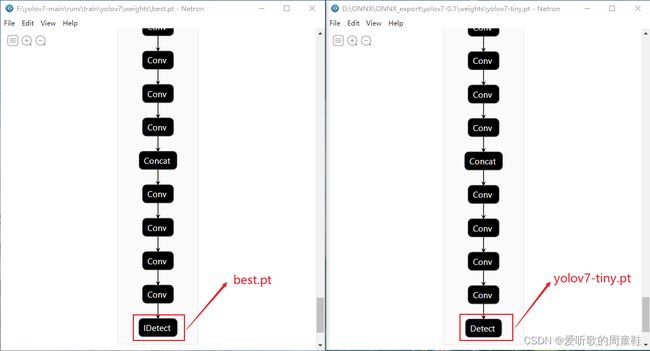
特别注意!!!,由于使用的模型是yolov7-tiny.pt,训练出来的检测头为IDetect而非部署时的Detect,可以利用Netron工具查看官方yolov7-tiny.pt和best.pt二者间区别,如下图所示。
主要有以下几点说明
1.可以查看yolov7项目中的cfg文件夹中的training和deploy文件夹下的
yolov7-tiny.yaml文件,可以看到训练和部署时二者的检测头不一致,训练时为IDetect检测头,部署时为Detect检测头,这也是export.py导出onnx文件时需要加上--grid参数的原因2.
yolov7-tiny.pt训练出的检测头为IDetect,故代码修改的地方与tensorRT_Pro项目修改地方有出入,但内容大体一致3.
yolo.py文件中Model类前向传播过程中(706行),执行的前向传播为m.fuseforward而非m.forward4.最终定位修改代码的地方在IDetect类中的fuseforward函数中即
yolo.py文件第140行具体修改可参考下面。若有更新请参考最新!!!
# 在yolov7/models/yolo.py的第146行
# bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
# x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
# 修改为如下代码,保证view部分不会操作batch size,对于batch维度一定是-1:
bs, _, ny, nx = map(int, x[i].shape) # x(bs,255,20,20) to x(bs,3,20,20,85)
bs = -1
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
# 在yolov7/models/yolo.py的第153行
# y = x[i].sigmoid()
# if not torch.onnx.is_in_onnx_export():
# y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
# y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
# else:
# xy, wh, conf = y.split((2, 2, self.nc + 1), 4) # y.tensor_split((2, 4, 5), 4) # torch 1.8.0
# xy = xy * (2. * self.stride[i]) + (self.stride[i] * (self.grid[i] - 0.5)) # new xy
# wh = wh ** 2 * (4 * self.anchor_grid[i].data) # new wh
# y = torch.cat((xy, wh, conf), 4)
# z.append(y.view(bs, -1, self.no))
# 修改为如下代码,目的去掉ScatterND、去掉Gather、Shape等节点:
y = x[i].sigmoid()
xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, -1, 1, 1, 2) # wh
classif = y[..., 4:]
y = torch.cat([xy, wh, classif], dim=-1)
z.append(y.view(bs, self.na * ny * nx, self.no))
# 在yolov7/models/yolo.py的第176行
# return out
# 修改为如下代码,去掉多余的输出部分:
return x if self.training else torch.cat(z, 1)
# 在yolov7/export.py第126行
# dynamic_axes = {'images': {0: 'batch', 2: 'height', 3: 'width'}, # size(1,3,640,640)
# 'output': {0: 'batch', 2: 'y', 3: 'x'}}
# 修改为如下代码,使得动态维度只出现在batch上:
dynamic_axes={'images': {0: 'batch'}, # size(1,3,640,640)
'output': {0: 'batch'}}
3.3 导出ONNX模型
ONNX模型导出指令如下
$ cd yolov7
$ python export.py --dynamic --grid --weights=best.pt
导出的ONNX模型可使用Netron可视化工具查看,给出ONNX文件下载链接Baidu Drive[password:yolo]。
下图对比展示了原始onnx输出(不加修改直接导出)和简化后onnx输出(按照以上要求修改后导出)的部分差别(第一张未修改直接导出,第二张修改后导出)。主要体现在以下几点:
- 修改后的onnx导出文件更加简洁
- 不必要的节点如Shape、Gather、Unsqueeze等去除
- batch维度指定为动态,其它维度不指定


3.4 拓展-正确导出ONNX文件
如何正确导出ONNX文件?主要包含以下几条:
对于任何用到shape、size返回值的参数时,例如:
tensor.view(tensor.size(0),-1)这类操作,避免直接使用tensor.size的返回值,而是加上int转换如tensor.view(int(tensor(0)),-1),断开跟踪对于nn.Unsample或nn.functional.interpolate函数,使用scale_factor指定倍率,而不是使用size参数指定大小
对于reshape、view操作时,-1的指定需放到batch维度。其他维度计算出来即可。batch维度禁止指定为大于-1的明确数字
torch.onnx.export指定dynamic_axes参数,并且只指定batch维度,禁止其他动态
使用opset_version=11,不要低于11
避免使用inplace操作,如
y[...,0:2] = y[..., 0:2] * 2 - 0.5尽量少的出现5个维度,例如ShuffleNet Module,可用考虑合并wh避免出现5维
尽量将后处理部分在onnx模型中实现,降低后处理复杂度
注:参考自手写AI的详解TensorRT高性能部署视频,这些做法的必要性体现在,简化过程的复杂度,去掉Gather、Shape类节点,很多时候不这么改看似也可以成功,但是需求复杂后,依旧存在各类问题。按照上述要求修改后,基本总能成,就不需要使用onnx-simplifer了。具体更多细节描述请观看视频。
4. 运行
4.1 源码修改
yolo模型的推理代码主要在
src/application/app_yolo.cpp文件中,需要推理的图片放在workspace/inference文件夹中,将上述修改后导出的ONNX文件放在workspace/文件夹下。源码修改较简单主要有以下几点:
- 1. app_yolo.cpp 177行 “yolov7"改成"best”,构建best.pt模型
- 2. app_yolo.cpp 100行 cocolabels修改为mylabels
- 3. app_yolo.cpp 25行 新增mylabels数组,添加自训练模型的类别名称
具体修改如下
test(Yolo::Type::V7, TRT::Mode::FP32, "best") //修改1 177行"yolov7"改成"best"
for(auto& obj : boxes){
...
auto name = mylabels[obj.class_label]; //修改2 100行cocolabels修改为mylabels
...
}
static const char* mylabels[] = {"have_mask", "no_mask"}; //修改3 25行新增代码,为自训练模型的类别名称
4.2 编译
编译生成可执行文件.pro,保存在workspace/文件夹下,指令如下:
$ cd tensorRT_Pro-main
$ mkdir build && cd build
$ cmake .. && make -j8
耐心等待编译完成(PS:需要一段时间),make -j参数的选取一般时以CPU核心数两倍为宜,参考自make -j参数简介,Linux下CPU核心数可通过lscpu指令查看,jetson nano的cpu核心数为4。
$ lscpu
Architecture: aarch64
Byte Order: Little Endian
CPU(s): 4
On-line CPU(s) list: 0-3
Thread(s) per core: 1
Core(s) per socket: 4
Socket(s): 1
Vendor ID: ARM
Model: 1
Model name: Cortex-A57
Stepping: r1p1
CPU max MHz: 1479.0000
CPU min MHz: 102.0000
BogoMIPS: 38.40
L1d cache: 32K
L1i cache: 48K
L2 cache: 2048K
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32
编译图解如下所示

4.3 模型构建和推理
编译完成后的可执行文件.pro存放在workspace/文件夹下,故进入workspace文件夹下执行以下指令
$ cd workspace // 进入可执行文件目录下
$ ls // 查看当前目录下所有文件
$ ./pro yolo // 构建模型并推理
模型构建和推理图解如下所示。在workspace/文件夹下会生成best.FP32.trtmodel引擎文件用于模型推理,会生成best_Yolov7_FP32_result文件夹,该文件夹下保存了推理的图片。

模型推理效果如下图所示


4.4 拓展-摄像头检测
简单写了一个摄像头检测的demo,主要修改以下几点:
- 1. app_yolo.cpp 新增app_yolo_video_demo()函数,具体内容参考下面
- 2. app_yolo.cpp 177行 注释
- 3. app_yolo.cpp 176行 新增调用app_yolo_video_demo()函数代码,具体内容参考下面
static void app_yolo_video_demo(const string& engine_file, TRT::Mode mode){ // 修改1 新增函数
auto yolo = Yolo::create_infer(
engine_file, // engine file
Yolo::Type::V7, // yolo type, Yolo::Type::V5 / Yolo::Type::X
0, // gpu_id
0.5f, // confidence threshold
0.5f, // nms threshold
Yolo::NMSMethod::FastGPU, // NMS method, fast GPU / CPU
1024, // max objects
false // preprocess use multi stream
);
if (yolo == nullptr){
INFO("Engine is nullptr");
return;
}
cv::Mat frame;
cv::VideoCapture cap(0);
if (!cap.isOpened()){
INFO("Engine is nullptr");
return;
}
while (true){
cap.read(frame);
auto t0 = iLogger::timestamp_now_float();
time_t now = time(0);
auto boxes = yolo->commit(frame).get();
for (auto &obj : boxes){
uint8_t b, g, r;
tie(r, g, b) = iLogger::random_color(obj.class_label);
cv::rectangle(frame, cv::Point(obj.left, obj.top), cv::Point(obj.right, obj.bottom), cv::Scalar(b, g, r), 5);
auto name = mylabels[obj.class_label];
auto caption = iLogger::format("%s %.2f", name, obj.confidence);
int width = cv::getTextSize(caption, 0, 1, 2, nullptr).width + 10;
cv::rectangle(frame, cv::Point(obj.left - 3, obj.top - 33), cv::Point(obj.left + width, obj.top), cv::Scalar(b, g, r), -1);
cv::putText(frame, caption, cv::Point(obj.left, obj.top - 5), 0, 1, cv::Scalar::all(0), 2, 16);
}
imshow("frame", frame);
auto fee = iLogger::timestamp_now_float() - t0;
INFO("fee %.2f ms, fps = %.2f", fee, 1 / fee * 1000);
int key = cv::waitKey(1);
if (key == 27)
break;
}
cap.release();
cv::destroyAllWindows();
INFO("Done");
yolo.reset();
return;
}
int app_yolo(){
app_yolo_video_demo("best.FP32.trtmodel", TRT::Mode::FP32); // 修改3 176行新增
// test(Yolo::Type::V7, TRT::Mode::FP32, "yolov7"); // 修改2 注释177行
// test(Yolo::Type::V5, TRT::Mode::FP32, "yolov5s");
// test(Yolo::Type::V3, TRT::Mode::FP32, "yolov3");
}
进入build/文件夹下编译,然后进行workspace/文件夹下运行即可调用摄像头检测,指令如下
$ cd build
$ make -j8
$ cd ../workspace
$ ./pro yolo
图解如下所示

结语
本篇博客介绍了关于yolov7模型训练的流程,以及在jetson nano嵌入式上的部署工作。博主在这里只做了最基础的演示,如果有更多的需求需要各位看官自己去挖掘啦。感谢各位看到最后,创作不易,读后有收获的看官请帮忙点个⭐️。
下载链接
- yolov7源码[password:yolo]
- 口罩识别数据集[password:yolo]
- yolov7-v0.1预训练权重[password:yolo]
- yolov7口罩识别模型权重[password:yolo]
- tensorRT_Pro源码[password:yolo]
- tensorRT_Pro简化源码[password:yolo]
- JetPack镜像[password:nano]
- protobuf安装包[password:yolo]
参考
- Jetson嵌入式系列模型部署教程
- 利用yolov5训练自己的目标检测模型
- yolov7训练测试自己的数据集
- yolov7
- 利用Anaconda安装pytorch和paddle深度学习环境+pycharm安装—免额外安装CUDA和cudnn(适合小白的保姆级教学)
- 口罩佩戴识别Demo
- PASCAL VOC2012数据集讲解与制作自己的数据集
- 目标检测—数据集格式转化及训练集和验证集划分
- tensorRT_Pro
- Jetson NANO是什么?如何选?
- Jetson nano安装jtop
- Jetson nano安装pip并换源
- Linux下编译protobuf
- Linux下添加protobuf环境变量
- Netron可视化工具
- 手写AI的详解TensorRT高性能部署视频 博主强烈推荐!!!