图像检测:图像分割
图像分割
所谓图像分割指的是根据灰度,颜色,纹理和形状等特征把图像划分为若干互不交迭的区域,并使这些特征在同一区域内呈现出相似性,而在不同区域间呈现出明显的差异性。
语义分割(Semantic Segmentation)
语义分割的目标是从像素水平上理解,识别图片的内容,输入图片后,输出同尺寸的分割标记(像素水平),每个像素会被识别为同一个类别。主要用于机器人视觉和场景理解,自动驾驶,医学X光领域。

算法研究阶段
2015之前:手工特征+图模型(CRF)
2015之后:深度神经网络模型。改进CNN,并使用预训练CNN层参数。传统CNN的问题是后半段网络无空间信息,输出图片尺寸固定。全卷积网络所有层都是卷积层,可以解决将采样后的低分辨率问题。
全卷积网络(Fully Convolutional Networks-FCN)
全卷积是将所有全连接层转换成卷积层,适应任意尺寸输入,输出低分辨率分割图片
反卷积可以将低分辨率图片进行上采样,输出同分辨率分割图片
跳层架构可以精化分割图片
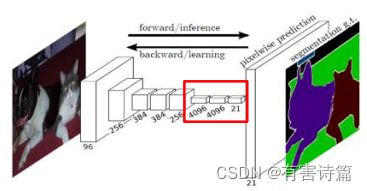
FCN卷积化
基础CNN网络:AlexNet,VGG16,GOOGLeNet,卷积后核尺寸:
FC6->(1x1,4096)
FC7->(1x1,4096)
FC8->(1x1,类别数)
分辨率降低32倍,5个卷积层,每层降2倍
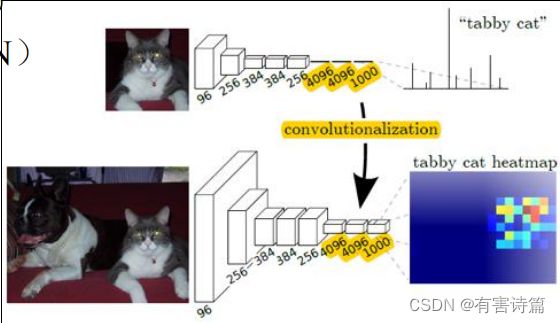
卷积化降维问题
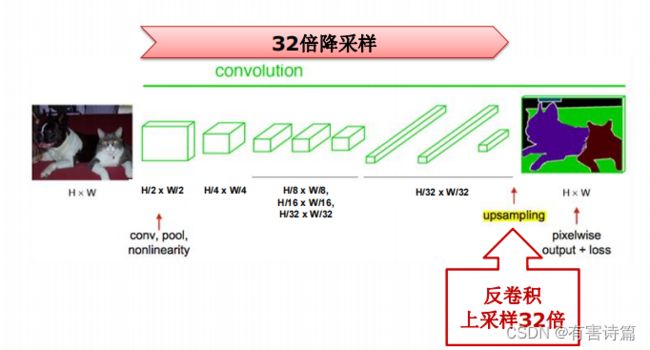
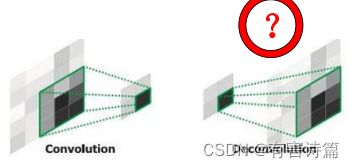
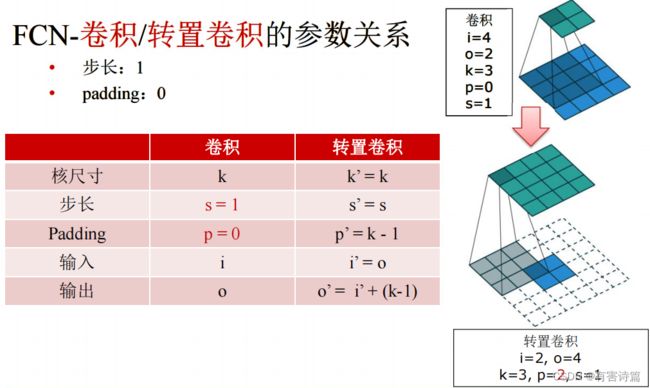
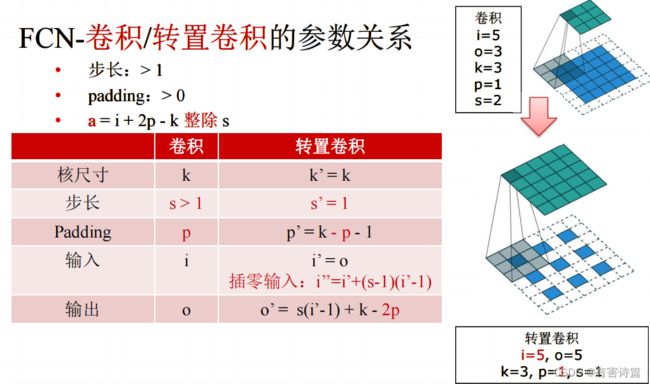
反卷积
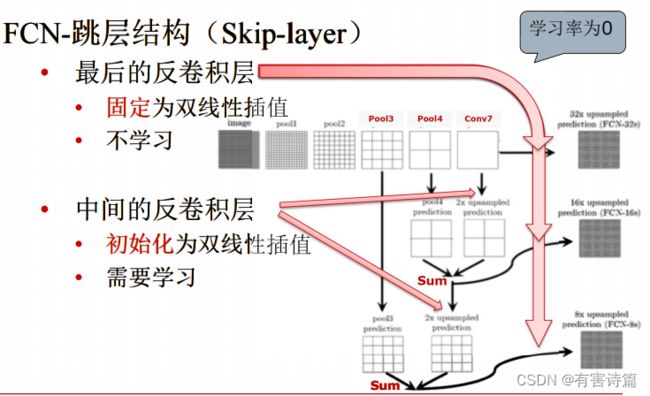
反卷积的前向和后向传播对应于卷积操作的后向和前向传播,优化上做颠倒。反卷积和是卷积核的转置,学习率为0。反卷积也叫转置卷积,它可以拟合出双线性插值。
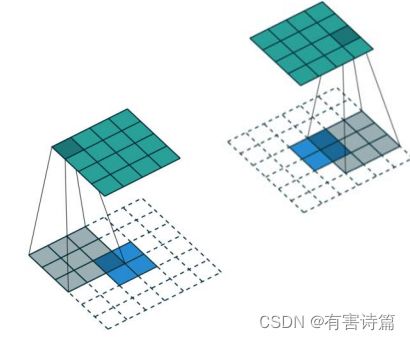
外围全补零反卷积,输入2X2,输出4X4,卷积核尺寸3X3,步长为1,padding为2。
FCN反卷积
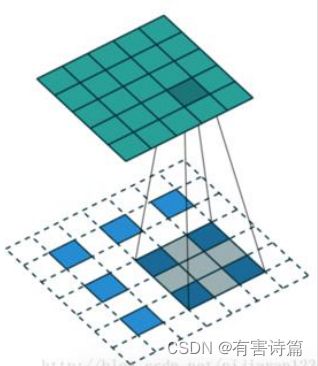
,插零分数步长卷积,输入3X3,输出5X5,卷积核尺寸3X3,步长为2,padding为1。
上采样的三种实现
- 双线性插值 :不需要进行学习,运行速度快,操作简单。
- 反卷积 : 为了还原原有特征图,类似消除原有卷积的某种效果,所以叫反卷积。
- 反池化 : 在池化过程中,记录下池化后的元素在对应kernel中的坐标,作为反池化的索引。
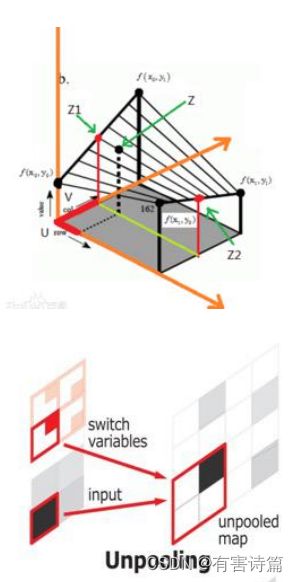
反池化
记录池化时的位置,形成池化索引,将输入特征按记录位置摆放回去
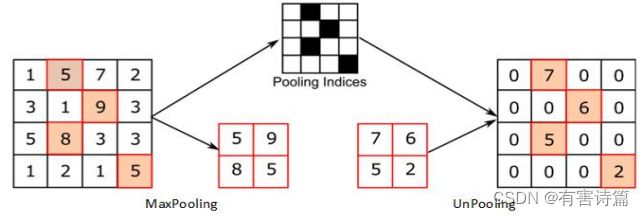
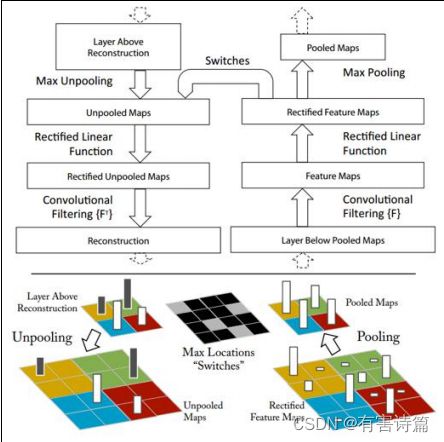
反卷积与反池化
反卷积与反池化之间最大的区别在于反卷积过程是有参数要进行学习的。理论上反卷积可以实现反池化,主要卷积核的参数设置的合理。

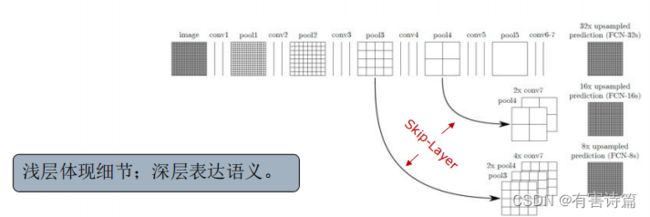
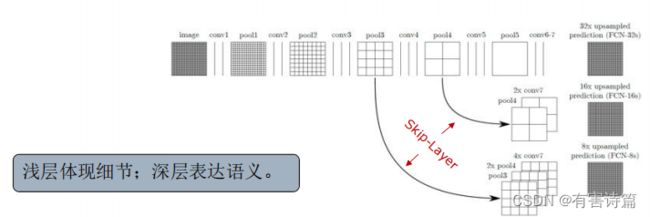
FCN-跳层结构
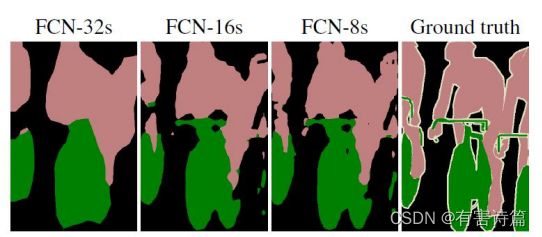
直接使用32倍反卷积得到的分割结果粗糙,使用前两个卷积层的输出做融合。
跳层:Pool4和Pool3后会增加一个1X1卷积层做预测,较浅的网络结构精细,较深的网络结果鲁棒。
FCN架构图例
构建FCN
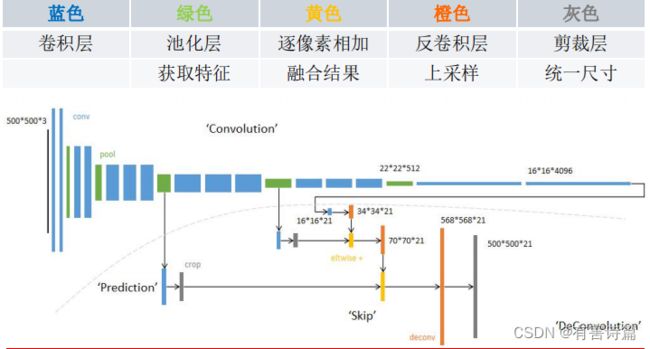
使用AlexNet构建FCN
第一步:使用AlexNet作为初始网络,保留参数,舍弃全连接层。

第二步(FCN-32s网络):
替换为两个同深度的卷积层(4096,1,1)->16x16x4096
追加一个预测卷积层(21,1,1)->16x16x21
追加一个步长为32的双线性插值反卷积层->500x500x21
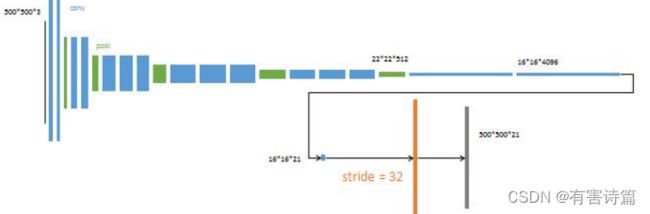
第三步(FCN-16s网络):
对最终层Conv7结果2倍上采样->34x34x21,提取Pool4输出,追加预测卷积层(21,1,1)->34x34x21,相加融合->34x34x21,追加一个步长为16的双线性插值反卷积层->500x500x21
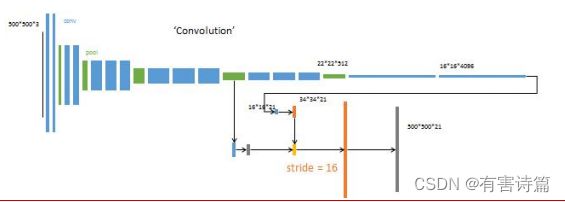
第四步(FCN-8s网络):
对上次融合结果2倍上采样->70x70x21,提取Pool3输出,追加预测卷积层(21,1,1)->70x70x21,相加融合->70x70x21,追加一个步长为8的双线性插值反卷积层->500x500x21
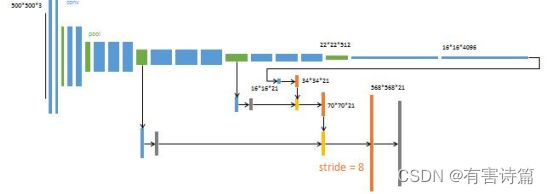
FCN训练
SGD with momentum(0.9)
学习率:learning rete:0.001(AlexNet),0.0001(VGG16),0.00001(GoogLeNet)
Minibatch:20
初始化:卷积层:前5个卷积层使用初始CNN网络参数,剩余第6和第7卷积层初始化为0。反卷积层:最后一层反卷积层固定为双线性插值,不做学习,剩余反卷积层初始化为双线性插值,做学习。
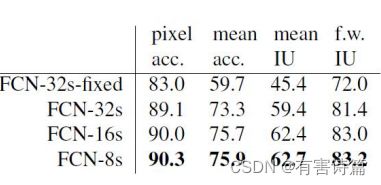
FCN性能
DeepLab V1
基本结构: 优化后的CNN + 传统的CRF图模型
新的上采样卷积方案: 带孔(hole)结构的空洞卷积。
边界分割的优化: 使用全连接条件随机场进行迭代优化。
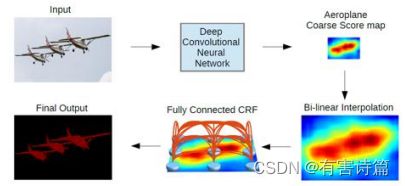
两个步骤: CNN输出粗糙的分割结果,全连接CRF精化分割结果
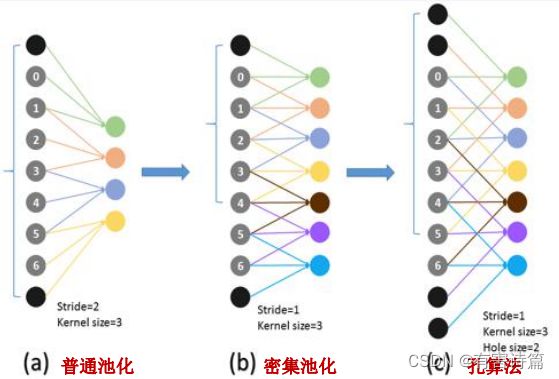
孔(Hole)算法
解决原始FCN网络的输出低分辨率问题;
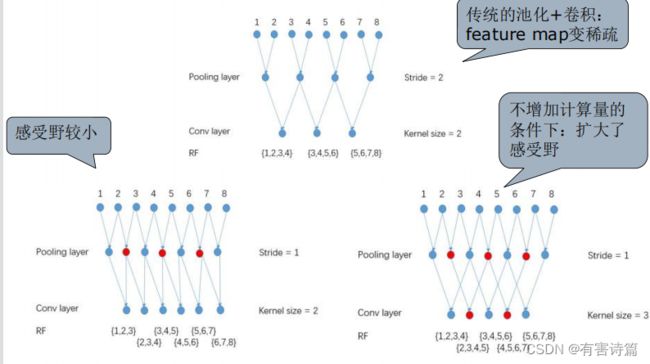
降低池化层的降采样倍数: VGG16网络Pool4和Pool5层的步长:2->1;减小降采样倍数:32->8;后续卷积核的感受野会变小。
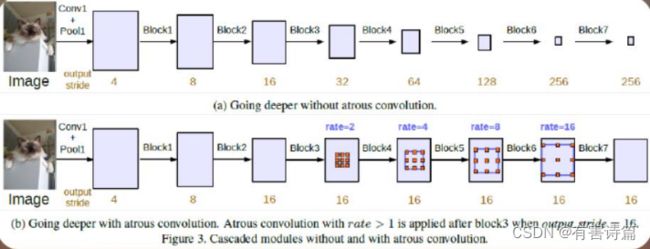
更改卷积核的结构->加孔(Hole): 无上采样功能,恢复感受野,可以用来fine-tune,保证了网络最终的高分辨率输出(仅8倍降采样)
卷积核结构: 尺寸不变(3x3),元素间距 变大(1->2),步长不变(1)
优势: 参数数量不变,计算量不变,高分辨输出
采用层: Conv5:孔尺寸2;Conv6:孔尺寸4。
空洞卷积
是孔算法的正式名称,与降低池化层步长配合使用,以取代上采样反卷积,孔尺寸->Rate,Rate越大,感受野越大。
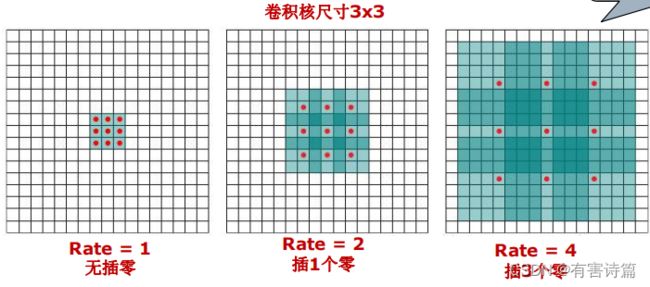
空洞卷积的参数:
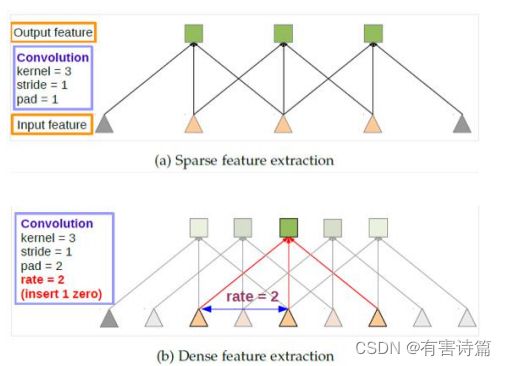
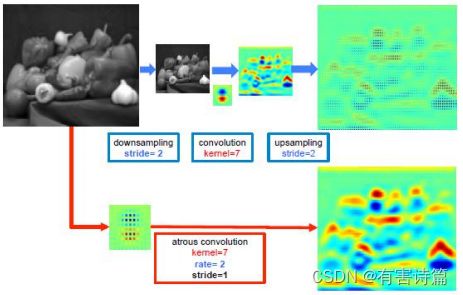
空洞卷积的效果: 稀疏特征的提取:x2降采样->7x7卷积->x2上采样;稠密特征提取:7x7空洞卷积。
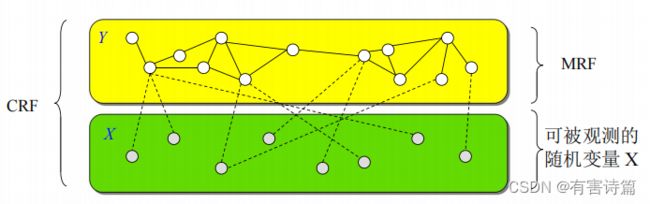
图像在CNN中逐层传递,是一个逐步抽象的过程,原来的位置信息会随着深度而减少甚至消失,CRF(条件随机场)的作用是,能在决定一个位置的像素值时,会考虑周围邻居的像素值(label)。short range的CRF可用于消除噪音,但是通过CNN得到的feature map在一定程度上已经足够平滑了,因此采用fully connected CRF,这样考虑的就是全局的信息了。
条件随机场(CRF)
随机场可以看成是一组“对应同一个样本空间的”随机变量的集合。当给每一个位置按照某种分布随机赋予一个值之后,其全体就叫做随机场。
马尔科夫随机场(MRF)对应一个无向图。此无向图上的每一个节点对应一个随机变量,节点之间的边表示节点对应的随机变量之间有概率依赖关系。
有向图模型中,每一个随机变量都有自己的条件概率(CPD);无向图模型中类似CPD的“关系”称作Factor–亲密关系。
求解无向图的联合概率方法;那把所有的Factor像有向图模型的贝叶斯网络那样都连乘起来,再做归一化。

这些联合概率实际上代表了无向图模型的概率分布,称为Gibbs分布。Gibbs分布就是利用Factor表示的无向图模型的概率分布,Gibbs分布的表示形式如下所示:
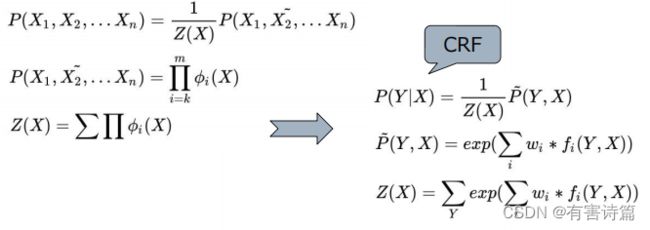
对于每个像素i具有类别标签Xi还有对应的观测值Yi,这样每个像素点作为节点,像素与像素间的关系作为边,即构成了一个条件随机场。而且我们通过观察变量Yi来推测i对应的类别标签Xi。条件随机场如下图:
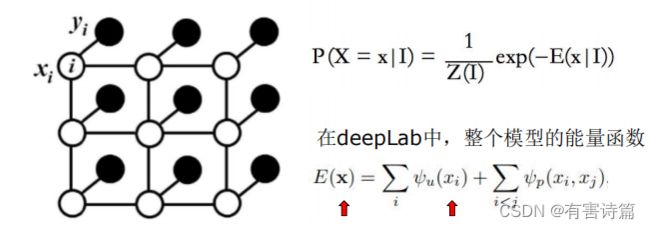

CRF的作用是通过迭代精化分割结果(恢复精确边界),其输入分为两种,首次输入时FCN网络输出结果的8倍双线性插值,非首次输入是上一轮迭代的结果,能量计算基于图片的RGB像素值
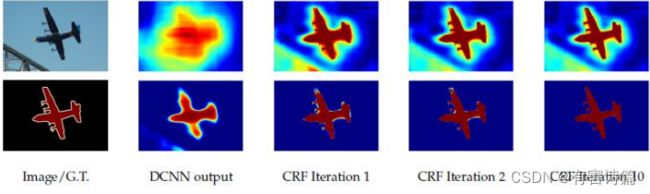
第一行:飞机类别的分值(softmax之前);第二行:飞机类别的概率值(softmax之后);
DeepLab V2
我们知道“多尺度”技术对性能提升很大,如果有多个感受野,就相当于一种“多尺度”
DeepLab V2有两个基础的网络结构,一个基于vgg16,另一个基于resnet101的,DeepLab v2通过多尺度对图片进行表达。多尺度实现方法,Atrous空间金字塔池化。
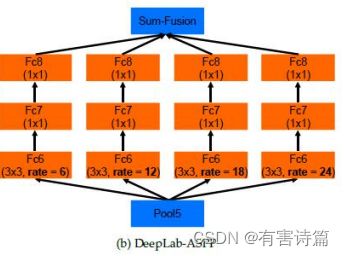
Atrous空间金字塔池化
不同感受野(rate)捕捉不同尺度上的特征,在Conv6层引入4个并行空洞卷积
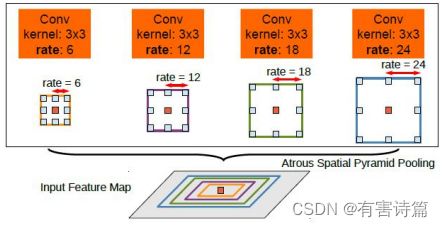
4个并行膨胀卷积,感受野:13x13,25x25,37x37,49x49
Fc6->Fc7->Fc8,深度:4096->2014->类别数量,卷积核:3x3->1x1->1x1;融合:概率相加。
DeepLab v3
- 提出了更通用的框架,适用于任何网络
- 复制了ResNet最后的block,并级联起来,block5-7是block4的副本
- 每个block中包含3个卷积层
- 在ASPP中使用BN层
- 最后一个特征图,采用全局平均池化
- 没有使用CRF
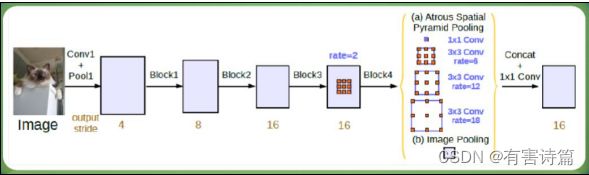
DeepLab V3采用了多种空洞率(atrous rate)的空洞卷积级联和并联的方式有效的提取多尺度的语境信息
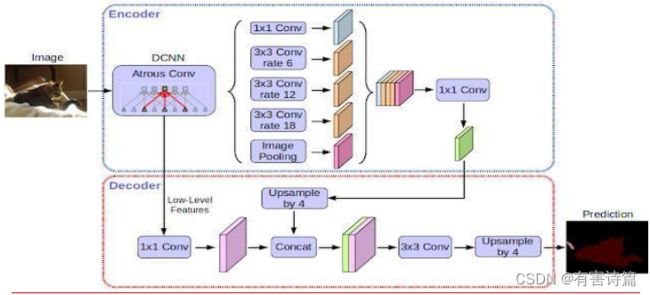
新的ASPP模块包括:一个1X1卷积和3个3x3的空洞卷积(采样率为(6,12,18)),每个卷积核都有256个且都有BN层。包含图像级特征(即全局平均池化)
DeepLab v3+
DeepLab V3+模型是DeepLab系列模型最新的改进方案,研究人员通过添加一个简单的解码器模型扩展DeepLab-V3,用于细化分割结果,在物体边界的划分上效果甚好。在v3的基础上增加了encoder-decoder模块,进一步保护物体的边缘细节信息。