yolov7训练BDD100k自动驾驶环境感知2D框检测模型
文章目录
- 数据集的选取
- bdd100k数据集介绍、下载
- 标签格式转换
-
- BDD转COCO
- COCO转YOLO
- 参考链接
数据集的选取
自动驾驶相关的数据集有很多,这里需要的是做目标检测。比较常用的数据集有:KITTI,nuScenes,bdd100k,COCO等。一开始选择了nuScenes,在训练后发现一些问题,比如数据集中各类型数据的数据量不均衡,有的类别很好训练,比如汽车,有许多类型的数据占比较低,训练难度大,并且缺少重要的标签类型交通灯,无法满足使用需求。考虑到yolov7的GT是2D框,数据集中给出的3D框需要进行转换,也存在精度损失的可能,故最终在有标定2D框的数据集中进行选择,bdd100k的数据量,标签类型,数据分布都比较符合要求,故最终选择了bdd100k数据集。
bdd100k数据集介绍、下载
官网:https://bair.berkeley.edu/blog/2018/05/30/bdd/
论文:https://arxiv.org/pdf/1805.04687.pdf
数据集:https://bdd-data.berkeley.edu/

近日,伯克利AI实验室发表了CV领域到目前为止规模最大、最多样化的开源视频数据集–BDD100K数据集。该数据集由100000个视频组成,每个视频大约40秒,720P,30fps,总时间超过1,100小时,视频序列还包括GPS位置、IMU数据和时间戳;视频带有由手机记录的GPS/IMU信息,以显示粗略的驾驶轨迹,这些视频分别是从美国不同的地方收集的,如上图所示,该数据库,涵盖了不同的天气状况,包含晴天、阴天和雨天以及在白天和夜天的不同时间。下图显示了BDD100K数据集和当前主流数据集的对比。
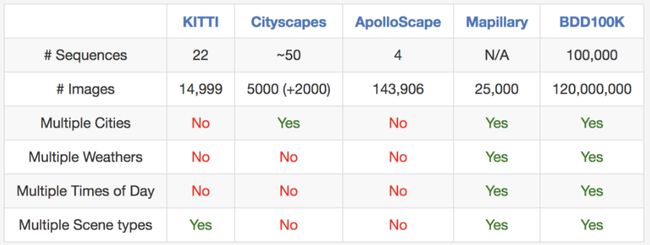
数据集在每个视频的第10秒抽取关键帧,并做了标注,主要分为以下几个层面,图像标记、道路对象边框、可行驶区域、车道标记和全帧实例分割。

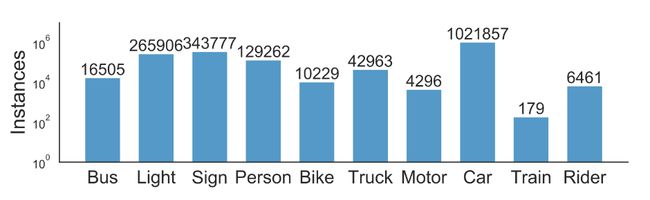
本文主要关注的是其道路物体检测的标签。BDD100K数据集在10万个关键帧图像中为道路上常见的对象标注BoundingBox,以了解对象的分布及其位置,下面的条形图显示各种目标的数目。
数据集下载:
访问BDD数据集网站https://bdd-data.berkeley.edu/,注册账号,点击download,根据需要下载所需的数据。这里选择100K images和labels。

标签格式转换
代码见附件。
BDD100k数据集的标签格式如下图,是由Scalabel生成的JSON格式。我们通过COCO数据集标签格式作为中间件进行转换,即先将BDD标签格式转为COCO格式,再将COCO格式转为YOLO格式。

BDD转COCO
核心代码如下。
for i in tqdm(labeled_images):
counter += 1
image = dict()
image['file_name'] = i['name']
image['height'] = 720
image['width'] = 1280
image['id'] = counter
empty_image = True
for label in i['labels']:
annotation = dict()
category=label['category']
if (category == "traffic light"):
color = label['attributes']['trafficLightColor']
category = "tl_" + color
if category in id_dict.keys():
empty_image = False
annotation["iscrowd"] = 0
annotation["image_id"] = image['id']
x1 = label['box2d']['x1']
y1 = label['box2d']['y1']
x2 = label['box2d']['x2']
y2 = label['box2d']['y2']
annotation['bbox'] = [x1, y1, x2-x1, y2-y1]
annotation['area'] = float((x2 - x1) * (y2 - y1))
annotation['category_id'] = id_dict[category]
annotation['ignore'] = 0
annotation['id'] = label['id']
annotation['segmentation'] = [[x1, y1, x1, y2, x2, y2, x2, y1]]
annotations.append(annotation)
if empty_image:
continue
images.append(image)
COCO转YOLO
修改coco2yolo.py中的config并运行。
if __name__ == '__main__':
config ={
"datasets": "COCO",
"img_path": "E:/CODE/deyi/dataset/bdd100k/iamges/100k/train",
"label": "E:/CODE/deyi/dataset/bdd100k/labels_coco/bdd100k_labels_images_det_coco_train.json",
"img_type": ".jpg",
"manipast_path": "./",
"output_path": "E:/CODE/deyi/dataset/bdd100k/labels_yolo/train",
"cls_list": "data/bdd100k.names",
}
# config ={
# "datasets": "COCO",
# "img_path": "E:/CODE/deyi/dataset/bdd100k/iamges/100k/val",
# "label": "E:/CODE/deyi/dataset/bdd100k/labels_coco/bdd100k_labels_images_det_coco_val.json",
# "img_type": ".jpg",
# "manipast_path": "./",
# "output_path": "E:/CODE/deyi/dataset/bdd100k/labels_yolo/val",
# "cls_list": "data/bdd100k.names",
# }
main(config)
整体文件结构、所用代码如下图所示。


格式转换完成后,先用check_label_image.py检查图片和标签是否一致,然后使用exportfiletxt.py导出训练集、验证集的图片路径到对应的txt文档,将yolo格式的label和数据集的图片按照yolov7要求格式放入训练文件夹即可。
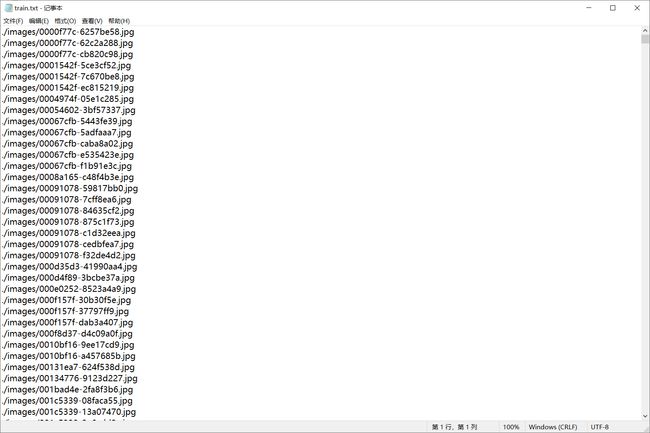
YOLOv7的数据存放格式与YOLOv5一致,将所有图像放到images文件夹下,与images同级的labels文件夹下存放所有的labels.txt文件,使用前述exportfiletxt.py导出的索引文档进行索引。下图中cache文件是训练时生成的,其余文件及文件夹结构如图所示。

参照./data/cooc.yaml文件编写bdd100k.yaml

在./cfg/training文件夹下选择你想要使用的模型类型,对其内容进行修改,例如yolov7.yaml,修改其nc = 13。这里主要是修改标签的类别数量nc,有需求的也可以进一步修改模型结构。

最后修改train.py中的参数,即可运行,也可使用对应的运行命令。
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='', help='initial weights path')
parser.add_argument('--cfg', type=str, default='cfg/training/yolov7.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/bdd100k.yaml', help='data.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.p5.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=4, help='total batch size for all GPUs')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--workers', type=int, default=0, help='maximum number of dataloader workers')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--entity', default=None, help='W&B entity')
parser.add_argument('--name', default='bdd100k', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table')
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B')
parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch')
parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used')
opt = parser.parse_args()
运行命令:在命令行中输入以下指令。
python train.py --workers 0 --device 0 --batch-size 4 --data data/bdd100k.yaml --img 640 640 --cfg cfg/training/yolov7.yaml --weights '' --name yolov7 --hyp data/hyp.scratch.p5.yaml
参考链接
本文对应代码下载地址:bdd100k数据集标签转COO再转YOLO程序
[1] 干货 | YOLOV5 训练自动驾驶数据集,并转Tensorrt,收藏!
[2] 一文彻底解决YOLOv5训练找不到标签问题
[3] yolov4、yolov5训练nuscenes数据集/nuscenes数据集转coco格式
[4] https://github.com/williamhyin/yolov5s_bdd100k