使用cityscapes数据集建立yolov7测试集
测试集的建立对评价模型好坏非常重要,本文使用cityscapes数据集,对其分割标签进行转换得到目标检测标签,并建立yolov7测试集,对训练的模型进行测试。
标签格式转换主要参考https://blog.csdn.net/Shenpibaipao/article/details/111240711
本文前述bdd100k数据集的下载、格式转换、yolov7训练流程链接:https://blog.csdn.net/qq_37214693/article/details/126708738?spm=1001.2014.3001.5501
在使用上文链接的程序进行转换后,得到的classes如下:
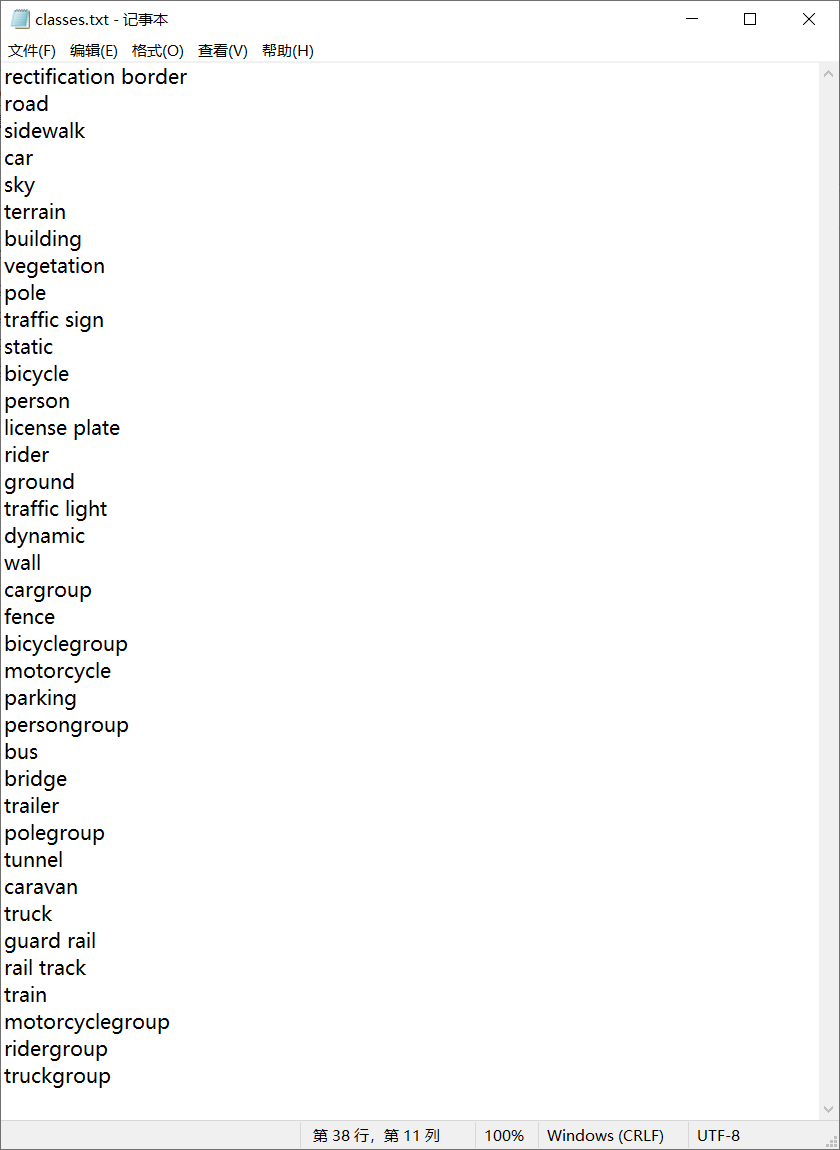
classes里有许多我们不需要的类别,以及类似”cargroup“这样的类型,查看官网的注释可以知道”如果无法清楚地看到此类实例之间的边界,则将整个人群/组标记在一起并注释为group,例如 cargroup。“由于此处为了建立一个测试集,之前训练的模型不需要考虑这种情况,因而有group的类别我们要抛去。
Single instance annotations are available. However, if the boundary between such instances cannot be clearly seen, the whole crowd/group is labeled together and annotated as group, e.g. car group.
筛选后的类别如下图所示。
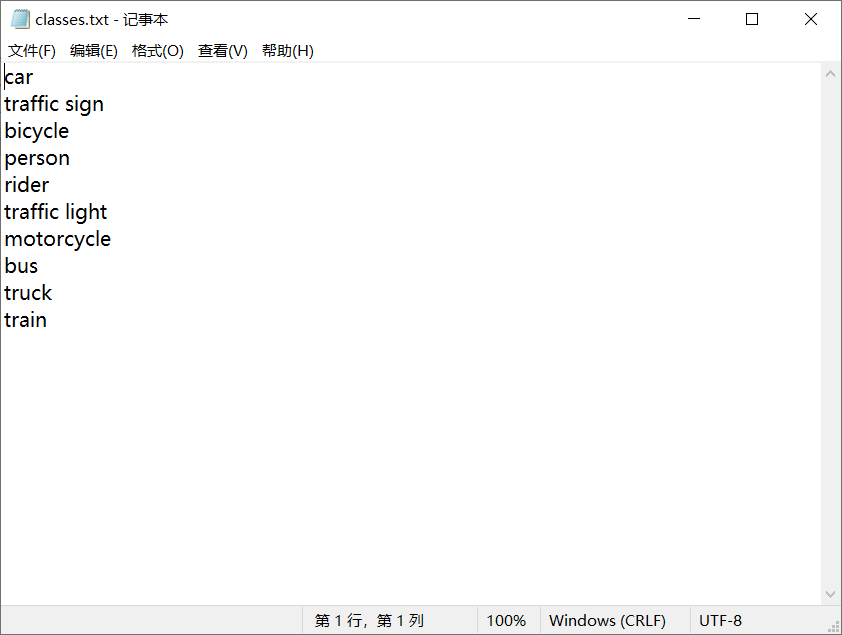
修改代码,将下列代码屏蔽,并定义label_map,重新运行程序便得到了我需要的类别标号及对应的每张图片的yolo格式标签。
# if obj_label not in label_map.keys(): # 记录目标类型转为int值
#
# label_map[obj_label] = len(label_map.keys()) # 标签从0开始
label_map = {"person": 0, "rider": 1, "car": 2, "bus": 3, "truck": 4, "bicycle": 5, "motorcycle": 6,
"traffic light": 10, "traffic sign": 11, "train": 12}
转换后得到的文件结构如下:
gtFine
test
train
val
labels
test
train
val
leftImg8bit
test
train
val
在test、train、val文件夹下根据采集城市又分为多个不同城市的数据,根据我们的需要将所有图片放在一个文件夹,标签放在一个文件夹,两个文件夹一起放在训练文件夹下,修改yolo相关的参数即可进行训练或测试。
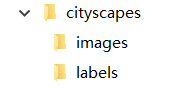
最终yolov7/data/cityscapes文件夹下的结构如图所示,images下是所有的图片,labels下是所有的标签。
根据data/coco.yaml进行修改,得到cityscapes.yaml。因为这里仅用来测试,故只需定义val即可。

运行下列命令进行测试
python test.py --data data/cityscapes.yaml --img 640 --batch 4 --conf 0.001 --iou 0.65 --device 0 --weights runs/train/bdd100k6/weights/best.p
t --name bdd100k6_val_20220907
python test.py --data data/cityscapes.yaml --img 640 --batch 32 --conf 0.001 --iou 0.65 --device 0 --weights yolov7_bdd.pt --name bdd100k6_val_202209071515
测试结果如图所示,由于模型训练轮数还比较少,因此mAP较低,但训练集中交通灯分红黄绿和none四个类别,测试集中没有颜色属性,所以检测结果中tl_none的mAP较低,需要进一步处理,将所有交通灯都归到一起。train的mAP显然脱离正常范围,猜测是数据量过少的原因,在bdd100k中,train的标签只有179个,可以考虑去掉该class,并且由于自动驾驶环境下火车基本不用考虑,因此对模型的使用影响不大。
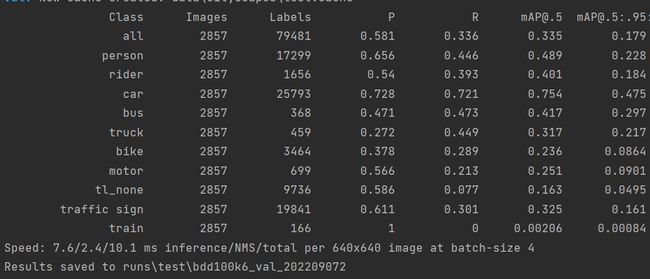
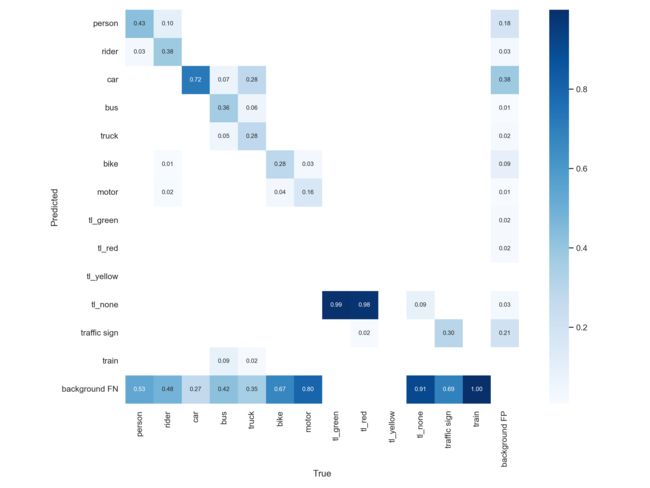
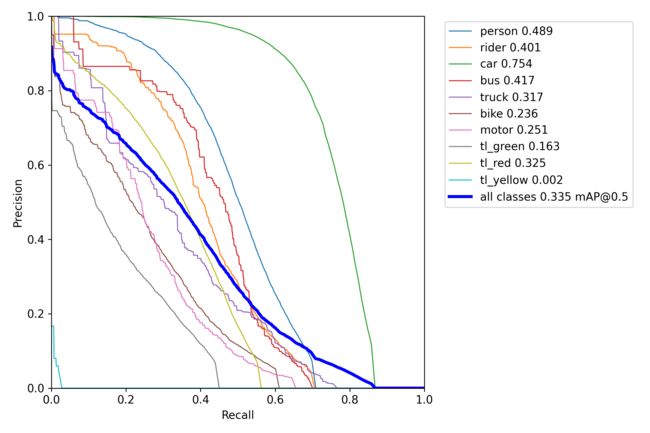
虽然模型精度还很低,但测试结果仍有值得分析的点,下面给出混淆矩阵、PR曲线和测试图例。
分析混淆矩阵可知,汽车、人类、骑手、公交车等类别的精确度都能明显看出训练是有效的,但由于模型训练还不到位,存在大量漏检,由于汽车的标签数量相对其它类别至少要出一个数量级,所以汽车的精度达到0.72是合理的,说明模型的预测有效,但仍需要多轮迭代。交通灯方面印证了上述猜测,交通灯的mAP低是因为测试集中交通灯无法区分颜色导致的,train全部漏检,说明模型对train的训练基本无效,这也是样本数量过小导致的。
PR曲线也可以看到,汽车的训练效果明显好于其他类别,整个模型还有待训练
下面给出三组test batch,可以看出,整体的预测效果还可以,大部分label都检测出来了,但仍然存在一定的漏检和许多错检,这一方是因为模型精度还不够,另一方面可以发现,部分label有误,这和cityscapes本身的标签是分割标签,转到检测标签会有一定的误差有关,还有就是不同数据集在进行标签的标定时标准不同,例如在test batch1中,第二个字图左侧,检测出了两个交通标志,但标签只有正面的一个。
test_batch0_labels

test_batch0_pred

test_batch1_labels

test_batch1_pred

test_batch2_labels

test_batch2_pred
