算法工程-Faiss原理和使用总结
1.Faiss的概念
faiss是一个Facebook AI团队开源的库,全称为Facebook AI Similarity Search,该开源库针对高维空间中的海量数据(稠密向量),提供了高效且可靠的相似性聚类和检索方法,可支持十亿级别向量的搜索,是目前最为成熟的近似近邻搜索库。
官方资源地址https://github.com/facebookresearch/faiss
2.Faiss基础依赖
1)矩阵计算框架:Faiss与计算资源之间需要一个外部依赖框架,这个框架是一个矩阵计算框架,官方默认配置安装的是OpenBlas,另外也可以用Intel的MKL,相比于OpenBlas使用MKL作为框架进行编译可以提高一定的稳定性。
2)OpenMP:如果向量之间的相似性搜索是逐条进行的那计算效率会非常低,而Faiss内部实现使用了OpenMP,可以以batch的形式来进行搜素,实现计算效率的提升。
3.Faiss工作数据流
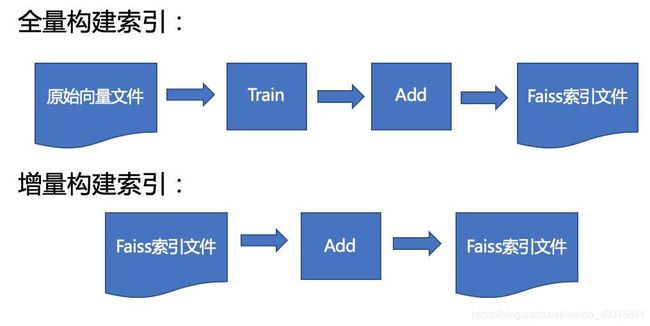
在使用Faiss进行query向量的相似性搜索之前,需要将原始的向量集构建封装成一个索引文件(index file)并缓存在内存中,提供实时的查询计算。在第一次构建索引文件的时候,需要经过Train和Add两个过程。后续如果有新的向量需要被添加到索引文件的话还可以有一个Add操作从而实现增量build索引。
4.Faiss的核心
Faiss本质上是一个向量(矢量)数据库。进行搜索时,基础是原始向量数据库,基本单位是单个向量,默认输入一个向量x,返回和x最相似的k个向量。其中的核心就是索引(index对象),Index继承了一组向量库,作用是对原始向量集进行预处理和封装,一般操作包括train和add,可以建成一个索引对象缓存在计算机内存中。所有向量在建立前需要明确向量的维度d,大多数的索引还需要训练阶段来分析向量的分布(除了IndexFlatL2)。当索引被建立就可以进行后续的search操作了。
Train
目的:生成原向量中心点,残差(向量中心点的差值)向量中心点,部分预计算的距离
流程:
1)把原始向量分成M个子空间,针对每个子空间训练中心点(如果每个子空间的中心点为n,则pq可表达n的M次方个中心点)。
2)查找向量对应的中心点
3)向量减去对应的中心点生成残差向量
4)针对残差向量生成二级量化器。
Search:
Search操作时索引的重要部分,search方法涉及实际的相似度计算,返回的检索结果包括两个矩阵,分别为xq中元素与近邻的距离大小和近邻向量的索引序号。
用法例子:
quantizer = faiss.IndexFlatL2(d)
index = faiss.IndexIVFFlat(quantizer, d, nlist, faiss.METRIC_L2)
index.train(xb)
index.add(xb)
D, I = index.search(xq, k) faiss中由多种类型的索引,如下图:
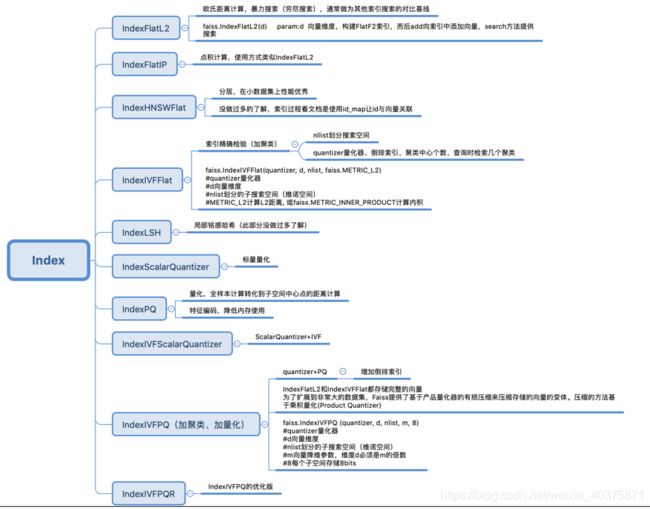
5. Faiss基础索引使用
三种常用的索引:IndexFlatL2、IndexIVFFlat、IndexIVFPQ
1)IndexFlatL2 - 最基础的索引
indexFlatL2是最简单最常用的索引类型,对向量执行暴力的L2距离搜索,也是唯一可以保证精确结果的索引类型
用法
index = faiss.IndexFlatL2(d)
index.add(xb)
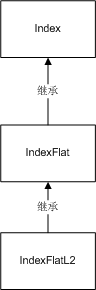
D, I = index.search(xq, k) IndexFlatL2与IndexFlat之间的继承关系如下图:
2)IndexIVFFlat-更快的索引
如果单纯使用IndexFlatL2速度不会太快,faiss提供了IndexIVFFlat这样的索引用于加速。其加速的原理是划分搜索空间,就是在d维空间中定义Voronoi单元格,每个数据库矢量都落入其中一个单元格中,将数据集分割成了若干部分。在搜索时,只有查询x所在单元中包含的数据库向量y与少数几个相邻查询向量进行比较。
IndexIVFFlat在建立时需要一个训练的过程,一般使用数据库向量执行,此外还需要另一个索引,即量化器(quantizer),其作用是将矢量分配给Voronoi单元。每个单元由一个质心定义,后续索引目的就是找到一个矢量所在的Voronoi单元包括在质心集中找到该矢量的最近邻居。
用法:
quantizer = faiss.IndexFlatL2(d)
index = faiss.IndexIVFFlat(quantizer, d, nlist, faiss.METRIC_L2)
index.train(xb)
index.add(xb)
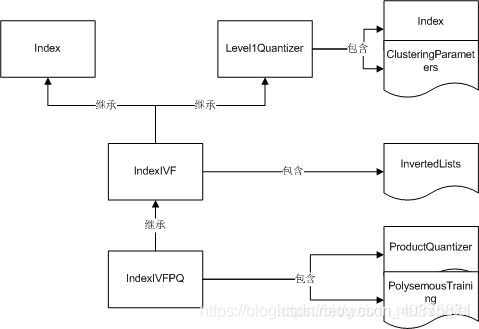
D, I = index.search(xq, k) 3)IndexIVFPQ-内存占用更小的索引
如果一个索引在处理很大规模向量数据时都往缓存中存储完整的向量,那么对硬件的压力会特别大, 为了扩展到非常大的数据集,Faiss提供了基于乘积量化(Product Quantizer)的方法来压缩存储的向量,减小数据量。除此之外,IndexIVFPQ会应用到K-means聚类中心算法,PCA降维等算法来对向量集进行压缩、编码。但是由于向量数据是有损压缩的,所以搜索方法返回的距离也是近似值。
其中,PQ压缩算法可以理解为首先把原始的向量空间分解为m个低维向量空间的笛卡尔积,并对分解得到的低维向量空间分别做量化。即是把原始D维向量(比如D=128)分成m组(比如m=4),每组就是D∗=D/m维的子向量(比如D∗=D/m=128/4=32),各自用kmeans算法学习到一个码本,然后这些码本的笛卡尔积就是原始D维向量对应的码本。用qj表示第j组子向量,用Cj表示其对应学习到的码本,那么原始D维向量对应的码本就是C=C1×C2×…×Cm。用k∗表示子向量的聚类中心点数或者说码本大小,那么原始D维向量对应的聚类中心点数或者说码本大小就是k=(k∗)m。原理就是把连续的空间离散化,将向量分段分散,每段分别聚类得到多个量化结果(每段一个量化结果),这样的好处是同较小的码本来表达非常大量的码,在计算时也可以加速。
quantizer = faiss.IndexFlatL2(d) # 内部的索引方式依然不变
index = faiss.IndexIVFPQ(quantizer, d, nlist=100, m=4, 8)# 每个向量都被编码为8个字节大小
index.train(xb)
index.add(xb)
D, I = index.search(xq, k)6.Faiss 进阶
1)index_factory简化索引构建
index_factory提供了更简化的方式建立声明索引类型,在给定字符串的情况下建立不同的索引,参数:1.前处理部分;2.倒排表(聚类);3.细化后处理部分
index = faiss.index_factory(d, “IVF100,PQ8”)
index = faiss.index_factory(d, “IVF4096, Flat”)
index = index_factory(d, "PCA80,Flat") # 原始向量128维,用PCA降为80维,然后应用精确搜索
index = index_factory(d, “OPQ16_64,IMI2x8,PQ8+16”) #原始向量128维,用OPQ降为64维,分为16类,用2*8bit的倒排多索引,用PQ编码为8byte保存,检索时使用16byte。2)PCA降维-PCAMatrix
coarse_quantizer = faiss.IndexFlatL2(256)
sub_index = faiss.IndexIVFPQ (coarse_quantizer, 1024, ncoarse, 16, 8)
pca_matrix = faiss.PCAMatrix (2048, 256, 0, True)
index = faiss.IndexPreTransform (pca_matrix, sub_index)
index.train(xb)
index.add(xb)为了使得在整个降维的过程中信息丢失最少,需要对待转换向量进行分析计算得到相应的转换矩阵(p*q)。也就是说这个降维中乘以的转换矩阵是与待转换向量息息相关的。假设期望使用PCA预处理来减少Index中的存储空间,那在整个处理流程中,除了输入搜索图库外,必须多输入一个转换矩阵,但是这个转换矩阵是与向量库息息相关的,是可以由向量库数据计算出来的。
3)IndexRefineFlat-对搜索结果进行精准重排序
由于使用IndexPQ类的索引会对结果精度造成影响,faiss提供了重排序的方法
q = faiss. IndexPQ (d, M, nbits_per_index)
rq = faiss.IndexRefineFlat (q)
rq.train (xt)
rq.add (xb)
rq.k_factor = 4
D, I = rq.search (xq, 10)从IndexPQ的最近4*10个邻域中,计算真实距离,返回最好的10个结果
4)Faiss使用gpu加速
如果本身硬件有gpu的话,可以调用gpu进行加速,量越大加速越明显
res = faiss.StandardGpuResources()
cpu_index = faiss.IndexFlatL2(d)
gpu_index_flat = faiss.index_cpu_to_gpu(res, 0, cpu_index)拷贝至gpu中
#gpu_index = faiss.index_cpu_to_all_gpus(cpu_index)
gpu_index_flat.add(xb)
D, I = gpu_index_flat.search(xq, k)5)Faiss索引保存至磁盘
如果使用一个服务器在调用faiss进行计算,那在处理多种向量库数据时会造成硬件(缓存)的压力,对于不常用或者随着时间慢慢消逝的索引,可以直接将其保存在硬盘中。
index = faiss.IndexFlatL2(d)
faiss.write_index(index, tmpdir + "trained.index")
index = faiss.read_index(tmpdir + "trained.index")——————————
文章中部分图来自:https://blog.csdn.net/rangfei/category_10080429.html