机器学习/深度学习中常见数据集加载(读取)方法
数据集有不同的类型,例如图像、文本、二进制、文件夹等等格式,用何种方法去加载这些数据,以及加载数据后的数据类型是什么(tensor、array、dataframe等等)?这里总结一下常见种类的数据集读取函数。
文本文件:CSV、TSV、Json、Txt
CSV文件是逗号分隔值(Comma-Separated Values,CSV),其文件以纯文本形式存储表格数据(数字和文本);
TSV 是Tab-separated values的缩写,即制表符分隔值,与csv和txt都同属于文本文件。不同点在于csv和tsv文件的字段间分别由逗号和tab键隔开(所以csv叫字符分隔值,tsv叫制表符分隔值)。
Txt文件则没有明确要求,可使用逗号/制表符/空格等多种不同的符号。
JSON (JavaScript Object Notation) 是一种轻量级的数据交换格式,它起初来源于JavaScript这门语言,但因其采用完全独立于语言的文本格式,所以在使用时与开发语言无关,几乎每门开发语言都有处理JSON的方法。
读取TSV、CSV文件可以用以下两个函数:
(1)csv.reader()
with open(filename, ’r’, encoding='utf-8') as fp:
data = csv.reader(fp)
csv.reader()函数是将每行数据当做列表返回的。但要注意,上述步骤返回一个reader对象(迭代器,个人感觉它更像一个指针,因为它必须在close操作之前使用)。这里有两种办法将这个迭代器转换为列表:一种是通过一个循环,另一种是直接通过list列表转换。
循环法:
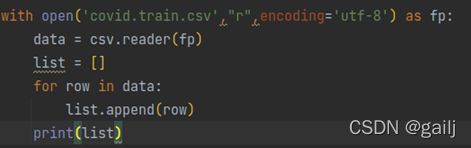
list列表直接转换:
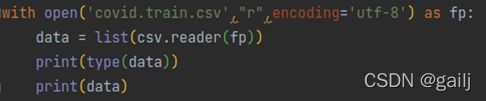
因为csv.reader()函数是默认读取csv文件的,因此分隔符默认是逗号;如果要读取tsv文件,需要修改一下默认分隔符:csv.reader(fp, delimiter = ‘\t’)
随后,再可以根据需要,转换为数组(array)或者张量(Tensor)
(2)pd.read_csv()
filename = ‘XXX’
data = pd.read_csv(filename, sep=’,’)
data = np.array(data)
这里seq参数默认为seq=',' 因为csv文件是以逗号分隔的,所以读取csv文件时seq这个参数也可以省略不写(不过tsv文件读取时,就需要将seq改为seq=’\t’,因为tsv文件是制表符分隔的)
该函数返回值是一个dateframe类型,可以直接通过array函数转换为数组,也可以通过切片的方式选择需要的行/列,具体参考dataframe的用法。
这个函数(read_csv)有几个参数比较重要,一个是encoding,可以选择utf-8,避免中文乱码;另一个是index_col,用于行索引的列标号或者列名;再是header,用于列名的行号,pd.read_csv函数中默认为0(默认第一行就是列名,不读进去),如果第一行不是列名,而是正儿八经的数据,那就令header=None
小技巧:
值得注意的是pd.read_csv函数比csv.reader函数有优势的地方在于,前者可以通过drop函数直接去掉指定的行或者列(当有些数据不需要时)。例如:
data.drop(1,axis = 0) 去掉第2行
data.drop([1,5,6,8],axis = 0) 去掉第2 6 7 9行
data.drop(‘col1’,axis = 1) 去掉第1列 (假设第一列的列名叫col1)
data.drop([‘col1’, ‘col3’],axis = 1) 去掉第1,3列(假设第1,3列的列名叫col1、col3)
可以查看dataframe的用法
TXT文件:
此外,部分数据集是txt文件形式的,txt文件有许多读取方法,不过上述两种方法也完全适用,这里就不再介绍新方法了。本人尝试了np.loadtxt函数,但发现该函数要求txt文件中数据列数要一致,否则报错;且该方法要求txt文件中数据只能以空格间隔(例如逗号间隔会报错);而csv和pd.read函数并不会报错,且可以处理多种间隔符号。
读取Json文件:
json.load()
import json
with open('train.json','r',encoding='utf-8') as fp:
data = json.load(fp)json读取到的data是一个字典类型的;接下来再就是对字典操作了
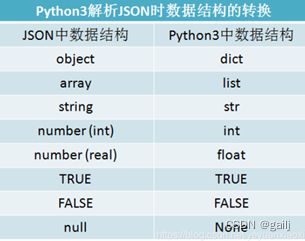
json格式的数据在解析到Python中数据结构也会发生相应的变化,解析前后json与Python数据结构的对应关系如下
小技巧:
(一):data里面有许多数据,我们可以通过循环的方式拿出来:例如李宏毅老师hw7中的例子,data中的question是一个字典(键),这个键对应的值是一个列表,列表中又有几万个字典。先通过data[‘question’]拿出列表,再遍历整个列表,取出列表中的几万个字典中的question_text键值。
(二):也有比较简单的方法,通过pandas.io.json模块中的json_normalize()函数,可以直接将已经解析成dict或list的json转化成dataframe,省去了循环提取的操作,方便好用。
import json
from pandas.io.json import json_normalize
with open('hw7_train.json','r',encoding='utf-8') as fp:
data = json.load(fp)
data = json_normalize(data['questions'])
print(data)
结果:
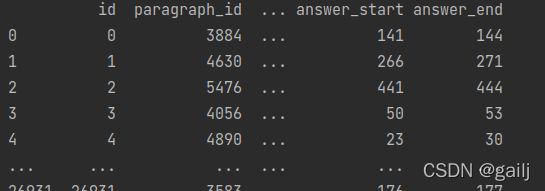
data = list(data['question_text']) #或者list(np.array(data)[:,2]) 这个2就是quesetion_test的位置
print(data)
结果:
二进制文件:npy
.npy文件是numpy专用的二进制文件。
np.load:
train = np.load(data_root + 'train.npy')返回类型是numpy.array,可以设置编码类型:ASCII latin1 bytes等, 比较简单就不过多赘述
图片文件:jpg、jpeg、png等
读取图片文件常用3个函数,分别介绍:
(1)skimage库的 io.imread()函数
import skimage.io as io
data = io.imread(‘dirpath/figure1.jpg’)
scikit-image是基于scipy的一款图像处理包,它将图片作为numpy数组进行处理,返回的数据正好是numpy.ndarray格式。
data是数组类型,它的形状是 (h,w,c) 高、宽、通道(RGB) 像素值范围是0-255
(2)opencv库的 cv2.imread()函数
import cv2
data = cv2.imread(‘dirpath/figure1.jpg’)
data = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # 转化为RGB,也可以用data = data[:, :, (2, 1, 0)]
opencv是一种最常见的图像处理库,返回的图片是一个numpy数组了,彩色图片维度是(高度,宽度,通道数)像素值范围是0-255,但需要格外注意的是,返回的通道排列是BGR,而不是主流的RGB。所以要有一步转换
(3)Python Imaging Library的Image.open()函数
from PIL import Image
data = Image.open(‘dirpath/figure1.jpg’)
data = np.array(data)
PIL,即 Python Imaging Library,也即为我们所称的Pillow,是一个很流行的图像库,它比opencv更为轻巧,正因如此,它深受大众的喜爱。(HWC,RGB)
PIL读进来的图像是一个PIL对象,而不是我们所熟知的numpy 矩阵。所以要先进行一下array的转换
小技巧:
(1):机器学习时经常会分类图片(应用于pytorch),假设所有的图片按文件夹保存,每个文件夹下面存贮同一类别的图片,文件夹的名字为分类的名字。这时候可以直接用ImageFolder或者DatasetFolder函数读入pytorch中,就可以省去一张一张读取的麻烦了。
ImageFolder(root,transform=None,target_transform=None,loader)
DatasetFolder(root,transform=None,target_transform=None,loader,extensions)
root就是文件夹的位置
extensions就是类型(因为DatasetFolder不止可以加载图片,所以可以指定‘jpg’等类型)
transform: 对PIL Image进行转换操作,transform 输入是loader读取图片返回的对象(注意这个对象必须是PIL类型,否则会报错)
target_transform :对label进行变换
loader:给定路径后如何读取图片,默认读取为RGB格式的PIL Image对象(在ImageFolder中可省略,默认就是Image.open(),但在DatasetFolder中不能省略)
train_set = DatasetFolder("food-11/training/labeled", loader=lambda x: Image.open(x), extensions="jpg", transform=train_tfm)
train_set = ImageFolder("food-11/training/labeled", transform=train_tfm)
label在这个ImageFolder或者DatasetFolder函数中会给处理好的,不需要特别去写,推荐使用ImageFolder函数
想要看ImageFolder函数读入了多少张图片,只需要将train_set变量打印出来即可;
想要看图片矩阵,print(train_set[2][0]) 第三张图片的矩阵
想看图片标签,print(train_set[2][1]) 第三张图片的标签
想要看图片尺寸,print(train_set[2][0].size()) 第三张图片的形状
想要查看子文件夹与图片标签的映射,print(train_set.class_to_idx)
(2):有些数据集不是按照这种文件夹分类的,例如GAN根本就不需要分类,所有图片都在一个文件夹内,这时候怎么读取呢。采用glob.glob函数可以一次性获取所有的匹配路径,就把所有的匹配路径都放在一个列表里了,这时候再从列表取值就行了
fname = glob.glob(os.path.join(makedir,'*'))
for i in range(len(fname))
img.append(io.imread(fname[i]))
