RoBERTa 详解
文章目录
- 0. 背景
- 1. 介绍
- 2. 背景
- 3. 实验设置
-
- 3.1 配置
- 3.2 数据
- 3.3 评估
- 4. 训练过程分析
-
- 4.1 Static vs Dynamic Masking
- 4.2 Model Input Format and NSP
- 4.3 Training with large batches
- 4.4 Text Encoding
- 5. RoBERTa
-
- 5.1 GLUE上的结果
- 5.2 SQuAD上的结果
- 5.3 RACE上的结果
- 6. 总结
0. 背景
机构:Facebook & 华盛顿大学
作者:Yinhan Liu 、Myle Ott
发布地方:arxiv
论文地址:https://arxiv.org/abs/1907.11692
论文代码:https://github.com/pytorch/fairseq
1. 介绍
RoBERTa 模型是BERT 的改进版(A Robustly Optimized BERT,即简单粗暴称为强力优化的BERT方法)。
在模型规模、算力和数据上,与BERT相比主要有以下几点改进:
- 更大的模型参数量(论文提供的训练时间来看,模型使用 1024 块 V100 GPU 训练了 1 天的时间)
- 更大bacth size。RoBERTa 在训练过程中使用了更大的bacth size。尝试过从 256 到 8000 不等的bacth size。
- 更多的训练数据(包括:CC-NEWS 等在内的 160GB 纯文本。而最初的BERT使用16GB BookCorpus数据集和英语维基百科进行训练)
另外,RoBERTa在训练方法上有以下改进:
- 去掉下一句预测(NSP)任务
- 动态掩码。BERT 依赖随机掩码和预测 token。原版的 BERT 实现在数据预处理期间执行一次掩码,得到一个静态掩码。 而 RoBERTa 使用了动态掩码:每次向模型输入一个序列时都会生成新的掩码模式。这样,在大量数据不断输入的过程中,模型会逐渐适应不同的掩码策略,学习不同的语言表征。
- 文本编码。Byte-Pair Encoding(BPE)是字符级和词级别表征的混合,支持处理自然语言语料库中的众多常见词汇。原版的 BERT 实现使用字符级别的 BPE 词汇,大小为 30K,是在利用启发式分词规则对输入进行预处理之后学得的。Facebook 研究者没有采用这种方式,而是考虑用更大的 byte 级别 BPE 词汇表来训练 BERT,这一词汇表包含 50K 的 subword 单元,且没有对输入作任何额外的预处理或分词。
RoBERTa建立在BERT的语言掩蔽策略的基础上,修改BERT中的关键超参数,包括删除BERT的下一个句子训练前目标,以及使用更大的bacth size和学习率进行训练。RoBERTa也接受了比BERT多一个数量级的训练,时间更长。这使得RoBERTa表示能够比BERT更好地推广到下游任务。
经过长时间的训练,本文的模型在GLUE排行榜上的得分为88.5分,与Yang等人(2019)报告的88.4分相当。本文模型在GLUE 9个任务的其中4个上达到了state-of-the-art的水平,分别是:MNLI, QNLI, RTE 和 STS-B。此外,RoBERTa还在SQuAD 和 RACE 排行榜上达到了最高分。
总结而言,本文的贡献有:
(1)提出了一套重要的BERT设计选择和训练策略,并引入了能够提高下游任务性能的备选方案;
(2)使用一个新的数据集CCNEWS,并确认使用更多的数据进行预训练可以进一步提高下游任务的性能;
(3)本文的训练改进表明,在正确的设计选择下,预训练的masked language model与其他所有最近发表的方法相比都更具有竞争力。 同时发布了在PyTorch中实现的模型、预训练和微调代码。
2. 背景
主要介绍了Bert
3. 实验设置
3.1 配置
略
3.2 数据
RoBERTa 采用 160 G 训练文本,远超 BERT 的 16G 文本,其中包括:
- BOOKCORPUS 和英文维基百科:原始 BERT 的训练集,大小 16GB。
- CC-NEWS:包含2016年9月到2019年2月爬取的6300万篇英文新闻,大小 76 GB(经过过滤之后)。
- OPENWEBTEXT:从 Reddit 上共享的 URL (至少3个点赞)中提取的网页内容,大小 38 GB 。
- STORIES:CommonCrawl 数据集的一个子集,包含 Winograd 模式的故事风格,大小 31GB 。
3.3 评估
使用以下三个基准评估下游任务的预训练模型。
- GLUE 通用语言理解评估(GLUE)基准是用于评估自然语言理解系统的 9 个数据集的集合。
- SQuAD 斯坦福问题答疑数据集(SQuAD)提供了一段背景和一个问题。任务是通过从上下文中提取相关跨度来回答问题。
- RACE 考试的重新理解(RACE)任务是一个大型阅读理解数据集,有超过 28000 个段落和近100000 个问题。该数据集来自中国的英语考试,专为中学生和高中生设计。
4. 训练过程分析
本节探讨在保持模型架构不变的情况下,哪些量化指标对预训练BERT模型有影响。首先维持训练BERT模型架构不变,其配置与BERT-base相同(L = 12, H = 768, A = 12,110M 参数)。
4.1 Static vs Dynamic Masking
原始静态mask:
BERT中是准备训练数据时,每个样本只会进行一次随机mask(因此每个epoch都是重复),后续的每个训练步都采用相同的mask,这是原始静态mask,即单个静态mask,这是原始 BERT 的做法。
修改版静态mask:
在预处理的时候将数据集拷贝 10 次,每次拷贝采用不同的 mask(总共40 epochs,所以每一个mask对应的数据被训练4个epoch)。这等价于原始的数据集采用10种静态 mask 来训练 40个 epoch。
动态mask:
并没有在预处理的时候执行 mask,而是在每次向模型提供输入时动态生成 mask,所以是时刻变化的。
不同模式的实验效果如下表所示。其中 reference 为BERT 用到的原始静态 mask,static 为修改版的静态mask。

从Table1中可以看出,修改版的静态mask与BERT原始静态mask效果相当;动态mask又与静态mask效果差不多,或者说略好了静态mask。基于上述结果的判断,及其动态mask在效率上的优势,本文后续的实验统一采用动态mask。
4.2 Model Input Format and NSP
原始的BERT包含2个任务,预测被mask掉的单词和下一句预测。鉴于最近有研究(Lample and Conneau,2019; Yang et al., 2019; Joshi et al., 2019)开始质疑下一句预测(NSP)的必要性,本文设计了以下4种训练方式:
-
SEGMENT-PAIR + NSP:
输入包含两部分,每个部分是来自同一文档或者不同文档的 segment (segment 是连续的多个句子),这两个segment 的token总数少于 512 。预训练包含 MLM 任务和 NSP 任务。这是原始 BERT 的做法。 -
SENTENCE-PAIR + NSP:
输入也是包含两部分,每个部分是来自同一个文档或者不同文档的单个句子,这两个句子的token 总数少于 512 。由于这些输入明显少于512 个tokens,因此增加batch size的大小,以使 tokens 总数保持与SEGMENT-PAIR + NSP 相似。预训练包含 MLM 任务和 NSP 任务。 -
FULL-SENTENCES:
输入只有一部分(而不是两部分),来自同一个文档或者不同文档的连续多个句子,token 总数不超过 512 。输入可能跨越文档边界,如果跨文档,则在上一个文档末尾添加文档边界token 。预训练不包含 NSP 任务。 -
DOC-SENTENCES:
输入只有一部分(而不是两部分),输入的构造类似于FULL-SENTENCES,只是不需要跨越文档边界,其输入来自同一个文档的连续句子,token 总数不超过 512 。在文档末尾附近采样的输入可以短于 512个tokens, 因此在这些情况下动态增加batch size大小以达到与 FULL-SENTENCES 相同的tokens总数。预训练不包含 NSP 任务。
上述4种训练模式的对比结果如Table 2所示:

BERT采用的是SEGMENT-PAIR(可包含多句话)的输入格式,从实验结果来看,如果在采用NSP loss的情况下,SEGMENT-PAIR 是优于SENTENCE-PAIR(两句话)的。我们发现单个句子(individual sentence)会损害下游任务的性能,可能是如此模型无法学习远程依赖。
接下来对比的是,在不采用NSP loss的情况下,用来自单个文档(DOC-SENTENCES)的文本块进行训练。我们发现,与Devlin等人(2019)相比,该设置的性能优于最初发布的BERT-base结果:与原始BERT相比,去掉NSP损失能够使得下游任务的表现持平或略微升高。所以原始 BERT 实现采用仅仅是去掉NSP的损失项,但是仍然保持 SEGMENT-PARI的输入形式的训练方式是可能的。
最后,实验还发现将序列限制为来自单个文档(DOC-SENTENCES)的性能略好于序列来自多个文档(FULL-SENTENCES)。但是 DOC-SENTENCES 策略中,位于文档末尾的样本可能小于 512 个 token。为了保证每个 batch 的 token 总数维持在一个较高水平,需要动态调整 batch-size 。出于处理方便,后面采用FULL-SENTENCES输入格式。
4.3 Training with large batches
以往的神经机器翻译研究表明,采用非常大的mini-batches进行训练时候,搭配适当提高学习率既可以提高优化速度,又可以提高最终任务性能。最近的研究表明,BERT也可以接受 large batch训练。Devlin等人(2019)最初训练BERT-base只有100万步,batch size为256个序列。通过梯度累积,训练batch size=2K序列的125K步,或batch size=8K的31K步,这两者在计算成本上大约是是等价的。
在表3中,比较了BERT-baseE在增大 batch size时的perplexity(困惑度,语言模型的一个指标,越低越好)和最终任务性能。可以观察到,large batches训练提高了masked language modeling 目标的困惑度,以及最终任务的准确性。large batches也更容易分布式数据并行训练, 在后续实验中,文本使用bacth size=8K进行并行训练。
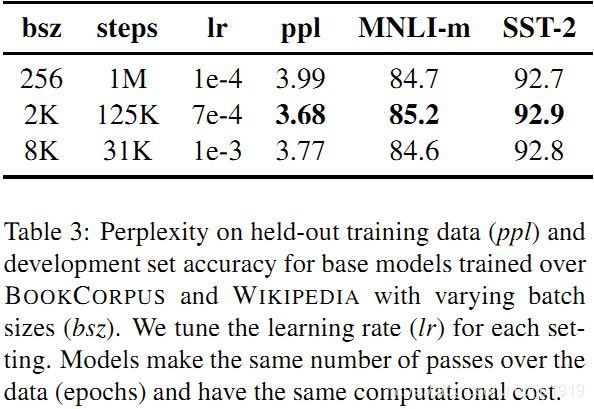
另外,You et al. (2019)在训练BERT时候,甚至将batch size增大到32k。至于batch size值的极限探索,留待后续研究。
4.4 Text Encoding
字节对编码(BPE)(Sennrich et al.,2016)是字符级和单词级表示的混合,该编码方案可以处理自然语言语料库中常见的大量词汇。BPE不依赖于完整的单词,而是依赖于子词(sub-word)单元,这些子词单元是通过对训练语料库进行统计分析而提取的,其词表大小通常在 1万到 10万之间。当对海量多样语料建模时,unicode characters占据了该词表的大部分。Radford et al.(2019)的工作中介绍了一个简单但高效的BPE, 该BPE使用字节对而非unicode characters作为子词单元。
总结下两种BPE实现方式:
- 基于 char-level :原始 BERT 的方式,它通过对输入文本进行启发式的词干化之后处理得到。
- 基于 bytes-level:与 char-level 的区别在于bytes-level 使用 bytes 而不是 unicode 字符作为 sub-word 的基本单位,因此可以编码任何输入文本而不会引入 UNKOWN 标记。
当采用 bytes-level 的 BPE 之后,词表大小从3万(原始 BERT 的 char-level )增加到5万。这分别为 BERT-base和 BERT-large增加了1500万和2000万额外的参数。
之前有研究表明,这样的做法在有些下游任务上会导致轻微的性能下降。但是本文作者相信:这种统一编码的优势会超过性能的轻微下降。且作者在未来工作中将进一步对比不同的encoding方案。
5. RoBERTa
总结一下,RoBERTa使用dynamic masking,FULL-SENTENCES without NSP loss,larger mini-batches和larger byte-level BPE(这个文本编码方法GPT-2也用过,BERT之前用的是character粒度的)进行训练。除此之外还包括一些细节,包括:更大的预训练数据、更多的训练步数。
为了将这些因素与其他建模选择(例如,预训练目标)的重要性区分开来,首先按照BERT-Large架构(L=24,H=1024,A=16355m)对RoBERTa进行训练。正如在Devlin et al.中使用的一样,本文用BOOKCORPUS和WIKIPEDIA数据集进行了100K步预训练。我们使用1024块V100 GPU对模型进行了大约一天的预训练。
结果如表4所示,当控制训练数据时,观察到RoBERTa比最初报告的BERT-large结果有了很大的改进,再次证实我们在第4章中探讨的设计选择的重要性。

表4:RoBERTa的开发集结果,因为预先训练了更多数据(16GB→160GB的文本)和预训练更长时间(100K→300K→500K步),每行累积上述行的改进。RoBERTa 符合BERTLARGE 的架构和训练目标。
5.1 GLUE上的结果
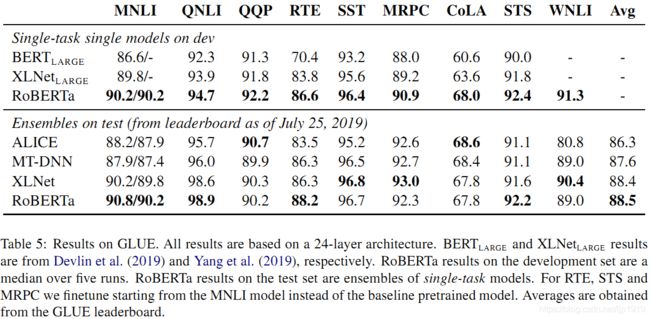 表5 :GLUE 的结果。所有结果均基于24 层架构。开发集上的RoBERTa 结果是五次运行的中位数。测试集上RoBERTa 的结果是单任务模型的集合。对于RTE, STS 和MRPC,从 MNLI 模型开始,而不是基线预训练模型。平均值可以从GLUE 排行榜获得。
表5 :GLUE 的结果。所有结果均基于24 层架构。开发集上的RoBERTa 结果是五次运行的中位数。测试集上RoBERTa 的结果是单任务模型的集合。对于RTE, STS 和MRPC,从 MNLI 模型开始,而不是基线预训练模型。平均值可以从GLUE 排行榜获得。
5.2 SQuAD上的结果
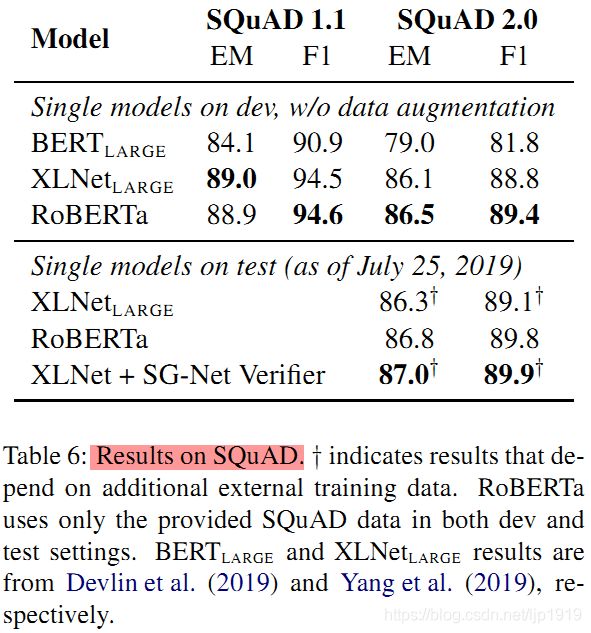
表6 :SQuAD 的结果。†表示取决于其他外部训练数据的结果。RoBERTa 仅在开发和测试设置中使用提供的SQuAD 数据。
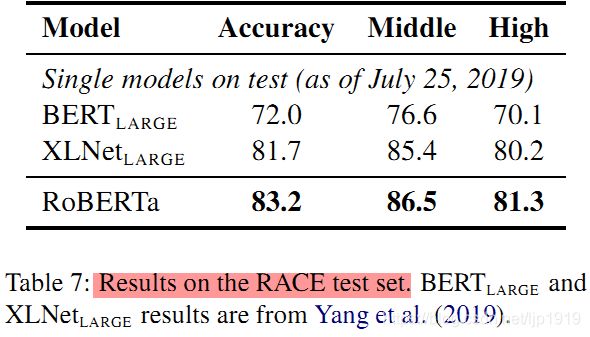
5.3 RACE上的结果
6. 总结
预训练 BERT 模型时,我们仔细评估了许多设计决策。 我们发现,通过更长时间地训练模型,在更多数据上使用更大的批次,移除下一句预测目标,训练更长的序列, 并动态更改应用于训练数据的屏蔽模式可以显着提高性能 。 我们改进的预训练程序,我们称之为 RoBERTa,在 GLUE、RACE 和 SQuAD 上取得了最先进的结果。
备注:在GLUE上没有进行多任务微调,在SQuAD上没有使用附加数据。 这些结果说明了这些先前被忽视的设计决策的重要性,并表明 BERT 的预训练目标与最近提出的替代方案相比仍然具有竞争力。