PyTorch 笔记Ⅸ——数据增强
文章目录
-
- 数据增强说明
- 导入必要的包
- 读取图片并显示
-
- 显示方式一
- 显示方式二
- Pytorch 数据增强
-
- transforms 之旋转
- transforms 之裁剪
- transforms.functional 之裁剪
- 特殊数据增强方式
- Augmentor
-
- 导入 Augmentor 包
- 读取图像并进行弹性形变
- 数据增强实践
-
- 导入新需要的模块
- 定义数据增强函数
- 开始处理
- 效果展示
数据增强说明
1.本次将演绎常用的Pytorch数据增强方式
2.本次将简单介绍数据增强模块Augmentor的使用方式
导入必要的包
import PIL.Image as Image
import os
from torchvision import transforms
from IPython import display
import matplotlib.pyplot as plt
读取图片并显示
transforms是对PIL图像进行处理(特殊函数除外RandomErasing),因此我们需要导入PIL包进行图像读取
显示方式一
利用IPython.display模块展示图片
display.Image('./augmentation/Pytorch_logo.png')

显示方式二
读取图片
image = Image.open('./augmentation/Pytorch_logo.png')
image.size
(1025, 205)
image

Pytorch 数据增强
transforms 之旋转
随机水平(左右)翻转
torchvision.transforms.RandomHorizontalFlip(p=0.5)
以给定的概率水平翻转给定的图像。该图像可以是PIL图像或torch Tensor,在这种情况下,它应具有[…, H, W]形状,其中...表示任意数量的前导维度,比如...可以是通道数,或者是batchsize和通道数,最后两位必须指定高度与宽度
参数:
p(float)–图像被翻转的可能性。默认值为0.5
fig = plt.gcf()
fig.set_size_inches(15, 4)
for i in range(4):
randomHorizontalFlip = transforms.RandomHorizontalFlip(p=0.5)(image)
ax = plt.subplot(2, 2, i+1)
ax.imshow(randomHorizontalFlip)
ax.set_xticks([])
ax.set_yticks([])
plt.show()
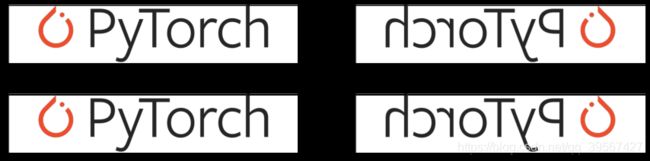
随机垂直(上下)翻转
torchvision.transforms.RandomVerticalFlip(p=0.5)
含义与上面水平翻转相同,不过一个是水平翻转一个是垂直翻转
fig = plt.gcf()
fig.set_size_inches(15, 4)
for i in range(4):
randomVerticalFlip = transforms.RandomVerticalFlip(p=0.5)(image)
ax = plt.subplot(2, 2, i+1)
ax.imshow(randomVerticalFlip)
ax.set_xticks([])
ax.set_yticks([])
plt.show()

随机角度翻转
torchvision.transforms.RandomRotation(degrees, resample=False, expand=False, center=None, fill=None)
给图像旋转一个角度
参数:
degrees(sequence或者float及int) - 旋转角度的范围选取,如果使用sequence如(min, max)则会在此范围内随机旋转,如果只指定一个数A,那么旋转范围在(-A, A)
resample({PIL.Image.NEAREST, PIL.Image.BILINEAR, PIL.Image.BICUBIC}, optional) - 图像重采样(插值)的方法,省略或图像模式指定为“1”或“P”,将采用PIL.Image.NEAREST(最近邻插值)【图像模式为“1”与“P”是PIL读取图像指定的,类似于RGB与BGR这种不同的模式,具体可以参见此处介绍的“L”与“P”模式】
expand(bool, optional)-可选参数。如果为true,则扩展输出以使其足够大以容纳整个旋转的图像。如果为false或省略,则使输出图像与输入图像具有相同的尺寸。需要注意的是扩展过程中旋转中心并未平移
center(2-tuple, optional)-可选参数,指定旋转的中心,默认值为图像中心为旋转中心
fill(n-tuple or int or float)-可选参数,旋转图像外部区域的像素填充值。如果为int或float,则该值分别用于所有区域。默认为0,即默认填充白色。【注意此选项仅适用于pillow>=5.2.0】
fig = plt.gcf()
fig.set_size_inches(15, 4)
for i in range(4):
if i>1:
randomRotation = transforms.RandomRotation(10, expand=True)(image)
else:
randomRotation = transforms.RandomRotation(10)(image)
ax = plt.subplot(2, 2, i+1)
ax.imshow(randomRotation)
ax.set_xticks([])
ax.set_yticks([])
plt.show()
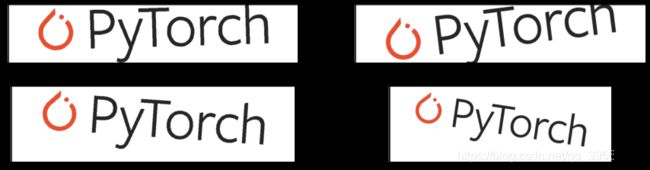
transforms 之裁剪
中心裁剪
torchvision.transforms.CenterCrop(size)
参数:
size(sequence或int)-指定裁剪尺寸(h, w)
fig = plt.gcf()
fig.set_size_inches(15, 4)
for i in range(4):
centerCrop = transforms.CenterCrop((250, 700))(image)
ax = plt.subplot(2, 2, i+1)
ax.imshow(centerCrop)
ax.set_xticks([])
ax.set_yticks([])
plt.show()

四角与中心裁剪
torchvision.transforms.FiveCrop(size)
参数:
size(sequence或int)-指定裁剪尺寸,如果为sequence则指定长宽,为int则裁剪为正方形,宽高相同
此函数裁剪后返回五张图片,分别从四个角以及中心进行裁剪
fig = plt.gcf()
fig.set_size_inches(20, 5)
fiveCrop = transforms.FiveCrop((170, 700))(image)
for i in range(5):
ax = plt.subplot(1, 5, i+1)
ax.imshow(fiveCrop[i])
ax.set_xticks([])
ax.set_yticks([])
plt.show()
![]()
fiveCrop
(,
,
,
,
)
随机位置裁剪指定尺寸
torchvision.transforms.RandomCrop(size, padding=None, pad_if_needed=False, fill=0, padding_mode=‘constant’)
参数:
size(sequence或int)-指定裁剪尺寸,如果为sequence则指定长宽,为int则裁剪为正方形,宽高相同
padding(int或sequence, optional)-图像每个边框上的可选填充。默认为None,即无填充。如果提供了长度为4的序列,则将其分别用于填充左边界,上边界,右边界和下边界。如果提供了长度为2的序列,则将其分别用于填充左/右,上/下边框
pad_if_needed(boolean)-如果小于所需大小,它将填充图像,以避免引发异常。由于裁剪是在填充之后完成的,因此填充似乎是在随机偏移下完成的【此参数非常重要】
fill –恒定填充的像素填充值。默认值为0。如果一个元组的长度为3,则分别用于填充R,G,B通道。仅当padding_mode恒定时使用此值
padding_mode-
填充类型。应该是:常量,边缘,反射或对称。默认为常数。
constant(常数):具有恒定值的填充,此值由填充指定
edge(边缘):在图像边缘具有最后一个值的填充
reflect(反射):具有图像反射的填充板(不重复边缘上的最后一个值)在反射模式下在两侧填充2个元素的[1、2、3、4]填充将导致[3、2、1、2、3、4、3、2]
symmetric(对称):具有图像反射的垫(重复边缘上的最后一个值)在对称模式下在两侧填充2个元素的[1、2、3、4]填充将导致[2、1、1、2、3、4、4、3]
【特别注意剪裁越界问题】
fig = plt.gcf()
fig.set_size_inches(15, 4)
for i in range(4):
randomCrop = transforms.RandomCrop(size=(250,700), padding=(10, 100))(image)
ax = plt.subplot(2, 2, i+1)
ax.imshow(randomCrop)
ax.set_xticks([])
ax.set_yticks([])
plt.show()

随机大小剪裁
torchvision.transforms.RandomResizedCrop(size, scale=(0.08, 1.0), ratio=(0.75, 1.3333333333333333), interpolation=2)
将给定的PIL图像裁剪为随机大小并缩放为指定纵横比
参数:
size – 期望输出尺寸的大小
scale – 裁剪原图尺寸的范围
ratio – 裁剪图像的宽高比范围
interpolation – 默认: PIL.Image.BILINEAR(线性插值)
【注意:scale是裁剪原图尺寸范围,意味着在原图上裁剪区域的范围;ratio是需要裁剪图像的宽高比,即在原图上指定的裁剪范围内裁剪出一个指定宽高比的图片,最后通过缩放成指定的size输出】
fig = plt.gcf()
fig.set_size_inches(15, 4)
for i in range(4):
randomResizedCrop = transforms.RandomResizedCrop(size=(250,700),
scale=(0.08, 1.0),
ratio=(0.75, 1.3333333333333333),
interpolation=2)(image)
ax = plt.subplot(2, 2, i+1)
ax.imshow(randomResizedCrop)
plt.show()

十种类裁剪
torchvision.transforms.TenCrop(size, vertical_flip=False)
与五种类裁剪相似,只是加上翻转操作,所以变为10种类,其中size指定大小,vertical_flip指定是垂直翻转还是水平翻转
fig = plt.gcf()
fig.set_size_inches(20, 3)
tenCrop = transforms.TenCrop((170, 700))(image)
for i in range(10):
ax = plt.subplot(2, 5, i+1)
ax.imshow(tenCrop[i])
ax.set_xticks([])
ax.set_yticks([])
plt.show()

tenCrop
(,
,
,
,
,
,
,
,
,
)
transforms.functional 之裁剪
与transforms对应功能相同,不做多的解释
中心裁剪
fig = plt.gcf()
fig.set_size_inches(15, 4)
functional_center_crop = transforms.functional.center_crop(image, output_size=(900,2000))
ax = plt.subplot(1, 1, 1)
ax.imshow(functional_center_crop)
ax.set_xticks([])
ax.set_yticks([])
plt.show()

functional指定框裁剪
fig = plt.gcf()
fig.set_size_inches(15, 4)
functional_crop = transforms.functional.crop(image,0, 0, 100, 600)
ax = plt.subplot(1, 1, 1)
ax.imshow(functional_crop)
ax.set_xticks([])
ax.set_yticks([])
plt.show()

functional五种类裁剪(不能越界)
fig = plt.gcf()
fig.set_size_inches(20, 5)
functional_five_crop = transforms.functional.five_crop(image, (170, 700))
for i in range(5):
ax = plt.subplot(1, 5, i+1)
ax.imshow(functional_five_crop[i])
ax.set_xticks([])
ax.set_yticks([])
plt.show()
![]()
functional剪裁与尺寸调整
fig = plt.gcf()
fig.set_size_inches(15, 4)
functional_resized_crop = transforms.functional.resized_crop(image,0, 300, 200, 300, (100, 600))
ax = plt.subplot(1, 1, 1)
ax.imshow(functional_resized_crop)
ax.set_xticks([])
ax.set_yticks([])
plt.show()

functional十种类裁剪
fig = plt.gcf()
fig.set_size_inches(20, 3)
functional_ten_crop = transforms.functional.ten_crop(image, (170, 700))
for i in range(10):
ax = plt.subplot(2, 5, i+1)
ax.imshow(functional_ten_crop[i])
ax.set_xticks([])
ax.set_yticks([])
plt.show()

functional_ten_crop
(,
,
,
,
,
,
,
,
,
)
特殊数据增强方式
随机擦除
随机选择图像中的矩形区域并删除其像素
torchvision.transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=0, inplace=False)
参数:
p – 执行擦除的概率
scale – 删除区域相对于输入图像的比例范围
ratio – 擦除区域的宽高比范围
value – 擦除像素的值,默认为0,如果为单个int,则用于擦除所有像素。如果元组的长度为3,则分别用于擦除R,G,B通道。如果str为“随机”,则使用随机值擦除每个像素
inplace – 默认为False,这个参数设置为False就行了
fig = plt.gcf()
fig.set_size_inches(15, 4)
image_jpg = Image.open('./augmentation/Pytorch_logo.jpg')
image_tensor = transforms.ToTensor()(image_jpg)
randomErasing = transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=(255/255, 0, 0), inplace=False)(image_tensor)
ax = plt.subplot(1, 1, 1)
ax.imshow(randomErasing.numpy().transpose(1, 2, 0))
ax.set_xticks([])
ax.set_yticks([])
plt.show()
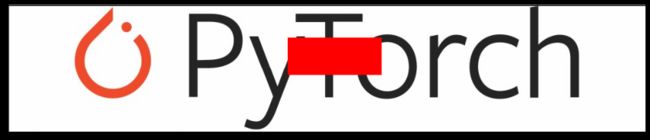
注意:
fig = plt.gcf()
fig.set_size_inches(15, 4)
image_png = Image.open('./augmentation/Pytorch_logo.png')
image_tensor = transforms.ToTensor()(image_png)
randomErasing = transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=(254/255, 0, 0, 0), inplace=False)(image_tensor)
ax = plt.subplot(1, 1, 1)
ax.imshow(randomErasing.numpy().transpose(1, 2, 0))
ax.set_xticks([])
ax.set_yticks([])
plt.show()
如果读取png格式的图片应采用这串代码,因为png格式具有4个通道
其中还包括一些颜色变换,亮度调节,对比度等,这些可以通过查询官网文档进行详细了解
Augmentor
导入 Augmentor 包
import Augmentor
读取图像并进行弹性形变
img = Augmentor.Pipeline('./augmentation')
Initialised with 5 image(s) found.
Output directory set to ./augmentation\output.
img.random_distortion(probability=0.7, grid_width=4, grid_height=4, magnitude=6)
img.sample(20)
Processing : 100%|█| 20/20 [00:01<00:00, 12.39 Samples/
img.status()
Operations: 1
0: Distort (probability=0.7 grid_width=4 grid_height=4 magnitude=6 randomise_magnitude=True )
Images: 5
Classes: 1
Class index: 0 Class label: augmentation
Dimensions: 5
Width: 1574 Height: 520
Width: 1579 Height: 776
Width: 1025 Height: 205
Width: 1024 Height: 204
Width: 1600 Height: 874
Formats: 2
PNG
JPEG
You can remove operations using the appropriate index and the remove_operation(index) function.
程序会在指定的文件夹下创建一个output文件夹并将生成的图片保存进取

数据增强实践
本次数据增强为扩增hymenoptera_data数据集,原始的hymenoptera_data数据集是一个二分类数据集,其包含文件关系如下:
|--hymenoptera_data
| |--train(245文件)
| | |---ants
| | |---bees
| |--val(153文件)
| | |---ants
| | |---bees
我们按照随机裁剪以及缩放的方式,扩增数据集为原来的11倍,也就是新增10倍数据集,为了方便数据的管理,我们将所有文件夹下的数据集重命名,重命名的bat文件编写参加我的另一篇博客Win10利用bat文件实现文件与文件夹批量重命名,我们将所有图片命名为i_0.jpg的格式。
●注意图片可能有其它格式需要将这些格式全部转换成统一类型例如jpg格式,我一般使用格式工厂或自定义脚本进行,切勿直接重命名!可以通过图片按类型排序找出其它类型图片
●注意图片是否能打开,可以通过图片按照大小排序可以很快找出不能打开的图片,因为往往这类图片的大小很小!
●PIL读取png的模式为RGBA,不能保存为jpg格式只能保存为png格式,而PIL读取jpg的模式为RGB,可以保存为jpg格式以及png格式,因此同一数据集统一图片格式是很重要的
导入新需要的模块
import os
import numpy as np
定义数据增强函数
def augmentation(image):
ratio = np.random.uniform(low=0.7, high=1.0, size=None)
image = transforms.RandomRotation(20, expand=False)(image)
image = transforms.RandomHorizontalFlip(p=0.5)(image)
image = transforms.RandomVerticalFlip(p=0.5)(image)
functional_ten_crop = transforms.functional.ten_crop(image, (int(image.size[1] * ratio), int(image.size[0] * ratio)))
return functional_ten_crop
开始处理
nums = 0
for train_val_dir in os.listdir('hymenoptera_data'):
for class_dir in os.listdir(os.path.join('hymenoptera_data', train_val_dir)):
saved_dir = os.path.join('hymenoptera_data', train_val_dir, class_dir)
for image_file in os.listdir(saved_dir):
nums += 1
image = Image.open(os.path.join(saved_dir, image_file))
image = augmentation(image)
i = 0
for pic in image:
i += 1
pic.save(os.path.join(saved_dir, image_file[0:-6]+'_'+str(i)+'.jpg'))
if nums % 10 == 0:
print('INFO: ', nums, ' images have been dealt!')
print('INFO: total ', nums, ' images have been dealt!\nData Augmentation finished!')
INFO: 10 images have been dealt!
INFO: 20 images have been dealt!
INFO: 30 images have been dealt!
INFO: 40 images have been dealt!
INFO: 50 images have been dealt!
INFO: 60 images have been dealt!
INFO: 70 images have been dealt!
INFO: 80 images have been dealt!
INFO: 90 images have been dealt!
INFO: 100 images have been dealt!
INFO: 110 images have been dealt!
INFO: 120 images have been dealt!
INFO: 130 images have been dealt!
INFO: 140 images have been dealt!
INFO: 150 images have been dealt!
INFO: 160 images have been dealt!
INFO: 170 images have been dealt!
INFO: 180 images have been dealt!
INFO: 190 images have been dealt!
INFO: 200 images have been dealt!
INFO: 210 images have been dealt!
INFO: 220 images have been dealt!
INFO: 230 images have been dealt!
INFO: 240 images have been dealt!
INFO: 250 images have been dealt!
INFO: 260 images have been dealt!
INFO: 270 images have been dealt!
INFO: 280 images have been dealt!
INFO: 290 images have been dealt!
INFO: 300 images have been dealt!
INFO: 310 images have been dealt!
INFO: 320 images have been dealt!
INFO: 330 images have been dealt!
INFO: 340 images have been dealt!
INFO: 350 images have been dealt!
INFO: 360 images have been dealt!
INFO: 370 images have been dealt!
INFO: 380 images have been dealt!
INFO: 390 images have been dealt!
INFO: total 397 images have been dealt!
Data Augmentation finished!
效果展示
最终生成的效果如下,原始图像一共397张图片,新扩增10倍后,数据集数量为原来的11倍,达到 397 × 11 = 4367 397×11=4367 397×11=4367张