极简sklearn-决策树(二)
前言
上一篇中介绍了决策树模型的基本使用,这篇来讲解下如何调参。
首先我们来谈谈如何提升预测的准确性,
第一步当然是选择正确的模型了,在学习机器学习算法的过程中,我们需要知道每个模型的特点,它擅长什么样的数据集,不擅长什么样的数据集,但有时候我们对数据集的分布并不是很清楚,这个时候就需要一个个尝试了。
第二步就是特征工程,sklearn当中的数据集往往很完美,没有缺失数据,但现实中的数据集有很多的问题,需要对数据做一定的处理才能使用,有些高手甚至能从已有特征中创建出新的特征,特征工程的掌握程度是区别菜鸟与高手的一个重要标志。
第三步就是调参了,其实我们现在数据集确定了,模型确定了,唯一能提升模型效果的就只有调参了,这也是为什么机器学习工程师被称为调参侠的原因 O(∩_∩)O哈哈~
第一个参数,criterion
criterion是用来衡量不纯度的指标,有两个参数可供选择,gini(基尼系数)和entropy(信息增益)
gini是默认参数,它跟entropy相比比较迟钝,所以不容易发生过拟合,在数据集特征多或者噪音多时有更好的表现,大部分情况下用这个
entropy,如果模型拟合度不好,可以试试这个
过拟合与欠拟合
说到调参我们再说说什么是过拟合与欠拟合
简单来说,如果模型在训练集上表现很好,在测试集上表现糟糕就是过拟合,比如在训练集上分数是95,在测试集上只有80分,那明显是过拟合了
如果在训练集和测试集上表现都不好,就是欠拟合了
random_state和splitter
random_state表示决策树随机种子,如果特征很多,决策树不会计算所有特征,而是随机选择一些特征来计算,通过splitter来控制随机策略,best表示优先选择关联度高的特征,random表示完全随机
max_depth
限制树的最大深度,超过设定深度的树枝全部剪掉,用的最广泛的剪枝参数,决策树多生长一层,对样本量的需求会增加一倍,所以限制树的深度能够有效防止过拟合。调参时可以从3开始尝试。
clf = tree.DecisionTreeClassifier(criterion="gini", random_state=20
,max_depth=3)
clf.fit(xtrain, ytrain)
score = clf.score(xtest, ytest)
print(score)![]()
可以看到效果立竿见影,分数从之前0.88上升到0.94
min_samples_leaf和min_samples_split
学习曲线
如果更直观的调参呢?这时候就可以用到学习曲线了.
#学习曲线
import matplotlib.pyplot as plt
%matplotlib inline
test = []
for i in range(10):
clf = tree.DecisionTreeClassifier(criterion="gini", random_state=20
,max_depth=i + 1 #z最大深度
,min_samples_leaf=10 #叶子节点最小样本数
,min_samples_split=10) #节点允许分枝样本数
clf = clf.fit(xtrain, ytrain)
score = clf.score(xtest, ytest)
test.append(score)
plt.plot(range(1, 11), test, color="red", label="max_depth")
plt.legend()
plt.show()
可以看到max_depth设为3的时候效果最好,再大对模型提升也没什么效果了
预测结果
clf.predict(xtest) #预测结果用来预测数据对应的标签
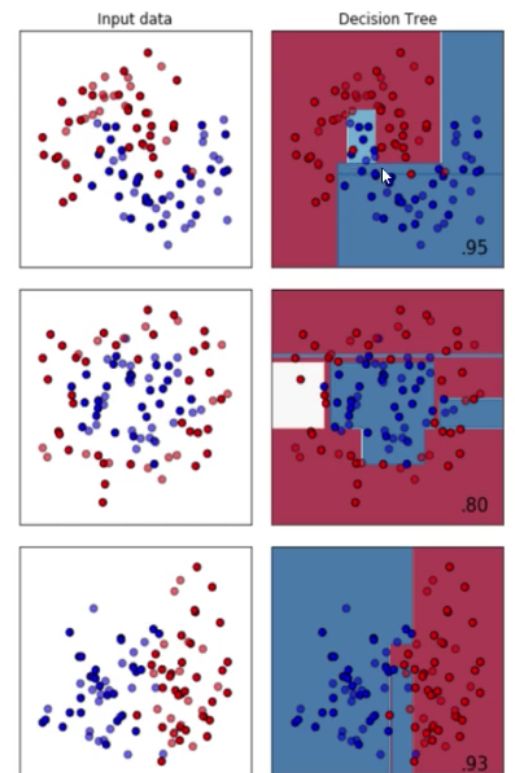
决策树擅长的数据集
决策树擅长月亮型和对半分型数据,不擅长环形数据
最擅长月亮型数据的是最近邻算法,支持向量机和高斯过程
最擅长环形数据的是最近邻算法和高斯过程
最擅长对半分数据的是朴素贝叶斯,神经网络和随机森林