dll文件日志怎么看_看懂Gurobi的日志文件(log file)
Gurobi日志文件(log file)的格式可以分为6类:Simplex、Barrier、Sifting、MIP、Multi-Objective、Distributed MIP。
第一类:Simplex
Simplex log可以划分为3部分: presolve、simplex progress 和 summary。
(1)Presolve部分
当优化求解一个模型的时候,Gurobi做的第一件事是用一个presolve算法简化模型。Presolve log信息表示presolve在多大程度上成功了。比如:

表示presolve可以去掉2381行、3347列,用时0.12秒。Presolve之后的模型规模是3690行、8883列。丢给simplex优化器求解的模型是presolve之后的模型。
(2)Progress部分

第1列:迭代次数;第2列:当前最优解;第3列:当前基违反约束(constraint)、边界(bound)的绝对值之和(注意不是违反约束或边界的个数);第4列:当前基违反对偶约束的绝对值之和;第5列:当前所用时间(墙上时钟时间,墙上时钟时间 = 阻塞时间 + 就绪时间 +CPU时间)。
Gurobi默认的单纯形法是对偶单纯形,如果发现了初始对偶可行基,第4列则为0。当第3列和第4列同时为0时,当前基是最优的。
Gurobi优化器默认5秒产生一行log信息,可以通过DisplayInterval参数进行修改。
(3)Summary部分
一般情况:
用户中止运行:
设定时间限制:
第二类:Barrier
Barrier log可以被划分为5个部分: Presolve、Barrier Preprocessing、Progress、Crossover 和 Summary。
(比较小众,暂时略过)
第三类:Sifting
Sifting log可以被划分为3个部分: presolve、Sifting Progress 和 Summary。
(比较小众,暂时略过)
第四类:MIP
MIP Log可以被划分为3个部分:Presolve、Progress 和 Summary。
(1)Presolve部分
当优化求解一个模型的时候,Gurobi做的第一件事是用一个presolve算法简化模型。Presolve log信息表示presolve在多大程度上成功了。比如:
表示presolve可以去掉2381行、3347列,用时0.12秒。Presolve之后的模型规模是3690行、8883列。丢给simplex优化器求解的模型是presolve之后的模型。
(2)Progress部分
该部分跟踪branch-and-cut搜索。
第一件事:在root relaxation被解之前找到整数可行解。

第二件事:找到root relaxation的解。
如果root被解的很快,可能只有一行数据:
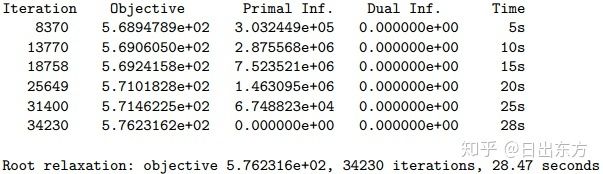
如果root relaxation需要花较多时间(5秒以上),就会附加显示一个详细的simplex log:
第三件事:branch-and-cut树的搜索过程。
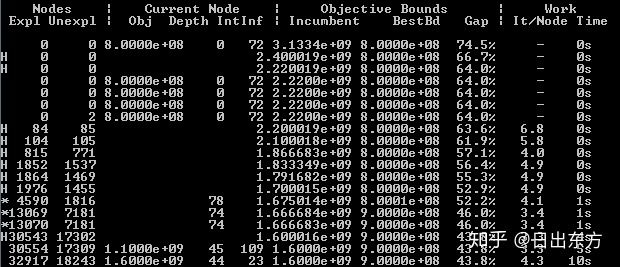
Nodes Section(1-2列):搜索过程的定量信息。第1列:已经被搜索过的节点个数。第2列:还没有被搜索的叶子节点。(The first column shows the number of branch-and-cut nodes that have been explored to that point, while the second shows the number of leaf nodes in the search tree that remain unexplored.) 第1列数字一定是逐渐增大,第2列数字不是严格单调递增,可能偶尔减小。前面的H或*标记表示一个新的可行解被找到了,H表示通过heuristic方法,*表示通过branching方法。
Current Node Section(3-5列):branch-and-cut tree中被搜索过的特定节点的信息。第3列:相应relaxation的目标值。第4列:branch-and-cut tree中节点的深度。第5列:非整数值的整数变量的个数。
Objective Bounds Section(6-8列):关于可行解的区间信息。第6列:上界(最优可行解)。第7列:下界(最优线性松弛解)(对于最小化问题)。第8列:上下界之间的gap((上界-下界)/上界)。如果gap小于MIPGap参数,则停止优化。
Work Section(9-10列):求解运算的工作量。第9列:branch-and-cut tree中每个节点simplex迭代的平均次数,Number of iterations/node。第10列:模型求解时间。
提示:已搜索节点数“长时间”为0表示Gurobi MIP solver正在处理根节点。在根节点需要花时间产生cutting plane,以及尝试多种heuristic方法来减小后面branch-and-cut tree的规模。
(3)Summary部分
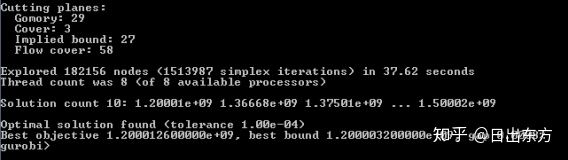
用37.62秒求到了最优解,8个可用的CPU核被用到8个(可通过Threads参数限制用到的CUP核的数量),最优解和最优bound之间的gap小于0.0008%,小于默认的MIPGap参数值,达到了最优中止状态。
第五类:Multi-Objective
log内容取决于求解模型所用的方法:(1)blended方法,多个目标函数值被融合为一个目标函数值,因此和single-objective模型的log格式相同。(2)hierarchical方法,多个优先级不同的模型依次被求解。(2.1)对于pure hierarchical multi-objective问题,假如3个目标函数,optimization process log 以此开始:
(2.1)对于mixed hierarchical-blended multi-objective问题,假如5个目标函数3个优先级,optimization process log 以此开始:
对于每个子目标函数求解,以此开始:
Name是被优化的目标函数的名字。每个子目标函数的optimization log与single-objective的optimization log格式相同。
第六类:Distributed MIP
Distributed MIP 和 standard MIP的log格式非常相似,主要区别在于progress section。Standard MIP以此开头:
相比之下,Distributed MIP倒数第2列不同,该列显示自上一行日志以来的运算时间:
节点数有时可能不是单调增加的,因为有多个机器在以不同的速率独立地处理节点。
另外一个不同点如下第一行,提示分布ramp-up阶段完成,此时运算由并行转为分布式。该行提示了哪个机器是并行计算中的winner,分布式MIP从该机器划分search tree而继续运算(注意第一行中的10661和第二行中的10660.9635)。

另外一个不同点体现在Summary Section,提示了时间是被如何分配的:

该例表示93%的时间用在了MIP nodes,6%的时间用在了等待与其他处理器同步,1%的时间用在了机器之间的同步。
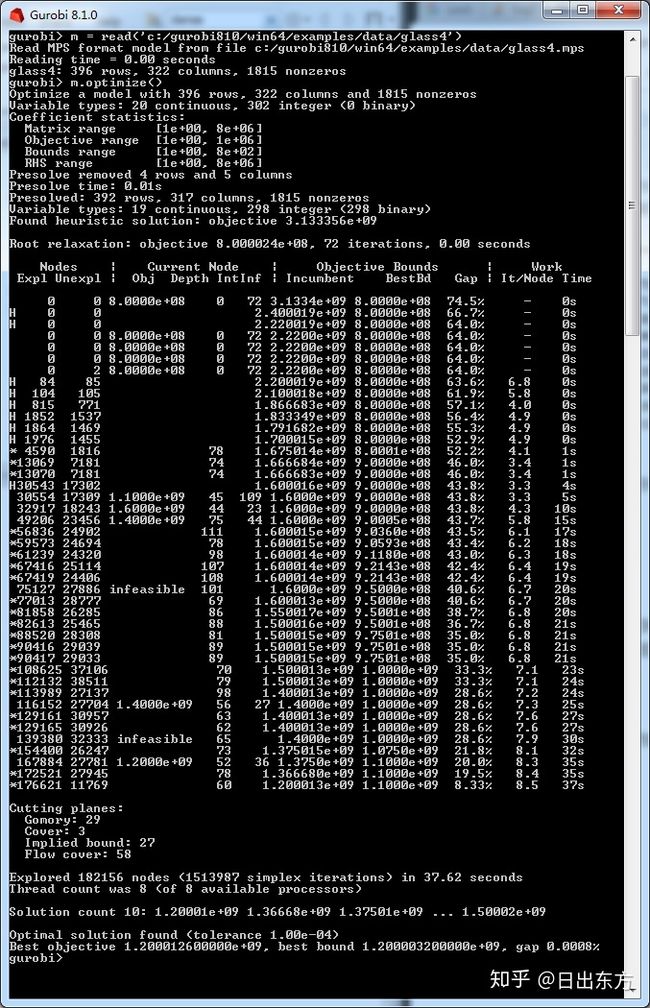
现在下图的信息是不是一目了然:
Additional Notes:
(1)图中Optimize a model with 396 rows, 322 columns and 1815 nonzeros是指constraints的系数矩阵。
(2)下图表示约束矩阵的系数范围是[1,8e+06],目标函数的系数范围是[1,1e+06],Variable bounds的范围是[1,8e+02],Right Hand Side (RHS)的系数范围是[1,8e+06]。

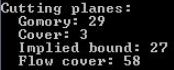
(3)下图表示用到的每种cut的个数。Comory:Root Gomory cut pass limit,对应参数GomoryPasses;Cover:Cover cut generation,对应参数CoverCuts;Implied bound:Implied bound cut generation,对应参数ImpliedCuts;Flow cover:Flow cover cut generation,对应参数FlowCoverCuts。