RNN->LSTM->BiLSTM神经网络结构
最近在学习《自然语言处理 基于预训练模型的方法》,打打公式吧。
RNN(Recurrent Neural Network)
h t = t a n h ( W x h x t + b x h + W h h h t − 1 + b h h ) h_t = tanh(W^{xh}x_{t}+b^{xh}+W^{hh}h_{t-1}+b^{hh}) ht=tanh(Wxhxt+bxh+Whhht−1+bhh)
y = s o f t m a x ( W h y h n + b h y ) y=softmax(W^{hy}h_{n}+b^{hy}) y=softmax(Whyhn+bhy)
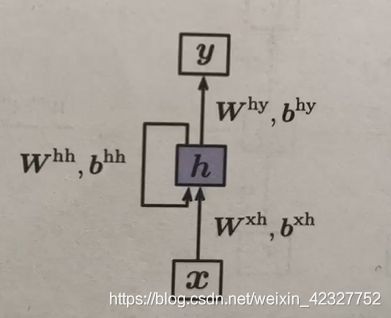
如果是文本分类问题,可以只在最后进行输出结果,如下图所示:
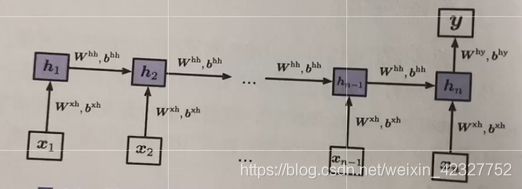
除此之外,还可以在每一时刻进行输出,可以用来处理序列标注问题,比如词性标注,NER,甚至分词。

LSTM(Long Short-Term Memory )
由于在普通的RNN结构中,信息是通过隐含层逐层进行传递的,这样每传递一层就会导致信息的损失,由此出现了长短时记忆网络。
为了不只是相邻两层有消息传递,有:
u t = t a n h ( W x h x t + b x h + W h h h t − 1 + b h h ) u_t = tanh(W^{xh}x_{t}+b^{xh}+W^{hh}h_{t-1}+b^{hh}) ut=tanh(Wxhxt+bxh+Whhht−1+bhh)
h t = h t − 1 + u t h_t=h_{t-1}+u_t ht=ht−1+ut
即: h t = h t − 1 + u t = h t − 2 + u t − 1 + u t = . . . . = h 1 + u 1 + . . . + u t h_t=h_{t-1}+u_t=h_{t-2}+u_{t-1}+u_{t}=....=h_1+u_1+...+u_t ht=ht−1+ut=ht−2+ut−1+ut=....=h1+u1+...+ut
这样保证了对于 k < t k
考虑到二者不应该知识线性的加权,所以引入了权重:
f t = σ ( W f , x h x t + b f , x h + W f , h h h t − 1 + b f , h h ) f_t = \sigma(W^{f,xh}x_{t}+b^{f,xh}+W^{f,hh}h_{t-1}+b^{f,hh}) ft=σ(Wf,xhxt+bf,xh+Wf,hhht−1+bf,hh)
h t = f t ⊗ h t − 1 + ( 1 − f t ) ⊗ u t h_t = f_t\otimes h_{t-1} + (1-f_t) \otimes u_t ht=ft⊗ht−1+(1−ft)⊗ut
其中, σ \sigma σ是sigmoid函数,通过该函数得到0-1之间的值,可以看作是权重。当值过小时,可以看作是将 h t h_t ht的知识给遗忘了,因此 f t f_t ft也被称作是遗忘门。同时发现,两项的系数成反比,对于有时候是正比的情况下,所以需要改进 u t u_t ut的权重系数。
有:
i t = σ ( W i , x h x t + b i , x h + W i , h h h t − 1 + b i , h h ) i_t = \sigma(W^{i,xh}x_{t}+b^{i,xh}+W^{i,hh}h_{t-1}+b^{i,hh}) it=σ(Wi,xhxt+bi,xh+Wi,hhht−1+bi,hh)
h t = f t ⊗ h t − 1 + i t ⊗ u t h_t = f_t\otimes h_{t-1} + i_t \otimes u_t ht=ft⊗ht−1+it⊗ut
其中 i t i_t it用来控制输入变量 u t u_t ut的贡献,被称作是输入门
有了遗忘门控制过去时刻的贡献,输入门控制现在输入变量的贡献,下面引进输出门控制输出。
o t = σ ( W o , x h x t + b o , x h + W o , h h h t − 1 + b o , h h ) o_t = \sigma(W^{o,xh} x_{t}+b^{o,xh}+W^{o,hh}h_{t-1}+b^{o,hh}) ot=σ(Wo,xhxt+bo,xh+Wo,hhht−1+bo,hh)
c t = f t ⊗ c t − 1 + i t ⊗ u t c_t = f_t \otimes c_{t-1} + i_t \otimes u_t ct=ft⊗ct−1+it⊗ut
h t = o t ⊗ t a n h ( c t ) h_t = o_t \otimes tanh(c_t) ht=ot⊗tanh(ct)
其中,c-t被称为记忆细胞,即存储了截至到当前时刻的2所有重要信息。
BiLSTM
我们发现了,无论是传统的RNN还是LSTM,都是从前往后传递信息,这在很多任务中都有局限性,比如词性标注任务,一个词的词性不止和前面的词有关还和后面的词有关。
为了解决该问题,设计出前向和方向的两条LSTM网络,被称为双向LSTM,也叫BiLSTM。其思想是将同一个输入序列分别接入向前和先后的两个LSTM中,然后将两个网络的隐含层连在一起,共同接入到输出层进行预测。
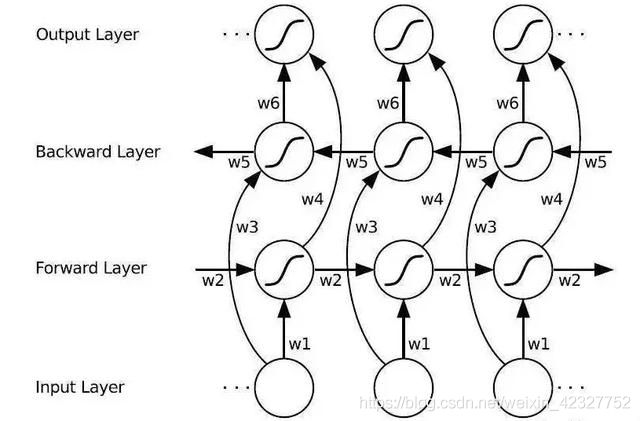 另外一种对RNN改进的方式是通过将多个网络堆叠起来,形成stacked Rnn.
另外一种对RNN改进的方式是通过将多个网络堆叠起来,形成stacked Rnn.