第一次~通过MockingBird进行声音模仿的感悟
伊始通过叶学长的途径看了b站的视频
AI杀疯了!2021年高能的AI算法,超乎想象!_哔哩哔哩_bilibili2021年高能的AI算法,尽在本期视频~求个免费的赞喽! https://www.bilibili.com/video/BV1RF411B7hT?p=1&share_medium=android&share_plat=android&share_session_id=7fc00e4d-cba7-4d9b-aa13-3dcd91d4d65c&share_source=WEIXIN&share_tag=s_i×tamp=1639098114&unique_k=cRangdH
https://www.bilibili.com/video/BV1RF411B7hT?p=1&share_medium=android&share_plat=android&share_session_id=7fc00e4d-cba7-4d9b-aa13-3dcd91d4d65c&share_source=WEIXIN&share_tag=s_i×tamp=1639098114&unique_k=cRangdH
我对其中的AI声音模仿大感兴趣,起初的目的是通过这个算法能"搞一搞"身边的朋友。
带着最原始的欲望直接开干,在2021年的12月13日中午,我迫不及待地开始了我的环境布置
危!我用python克隆了女朋友的声音!
别再折腾开发环境了,一劳永逸的搭建方法
Pytorch深度学习实战教程(一):语义分割基础与环境搭建
以上三个微信公众号的文章是我搭载环境的主要来源,当然除了这些还有通过百度/简书/CSDN/知乎进行的各种基本软件的安装,如CUDA,VS等,特别提一句安装这些软件妥妥的让我晕头转向,期间各种英文网站,英文内容让本就基础薄弱的我雪上加霜,如履薄冰,网络的不通畅让我对着电脑干瞪眼。
从创建虚拟环境开始我就直接请来了度娘,正所谓
吾尝终日而思矣,不如须臾之所学也。
我第一个学习到的命令就是
conda create -n your_name jupyter notebook #创建一个叫your_name的虚拟环境
conda info -e #查看已有环境
activate your_name #激活环境堪堪三句命令就让我费了不少时间,开始的我有点像无头苍蝇,不知道怎么办。
随后我们需要在虚拟环境上搭载各种库以期实现咱们梦寐以求的算法
无知的我以为直接使用
conda install PyTorch #可以运行但是加载的包不对进行下载就可以了,呵呵了,后来才知道要进入pytorch官网用他筛选后的代码下载,如图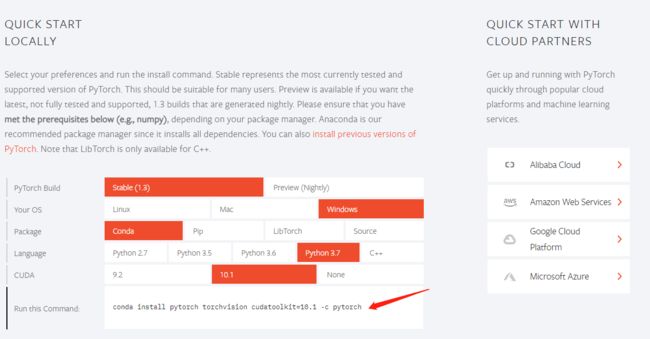
所以问题又来了,我们得下载CUDA,这里还得提一句,我们不是要下载最新版的CUDA,而是匹配自己GPU的版本,那么问题来了以前的版本又怎么找?
网址你进得去吗?

还好看的懂一些英文

这上面有previous cuda releases
点进入如图

那么我们的CUDA又是哪个版本呢?
打开NVIDIA控制面板,点帮助,点系统信息,点组件。。。
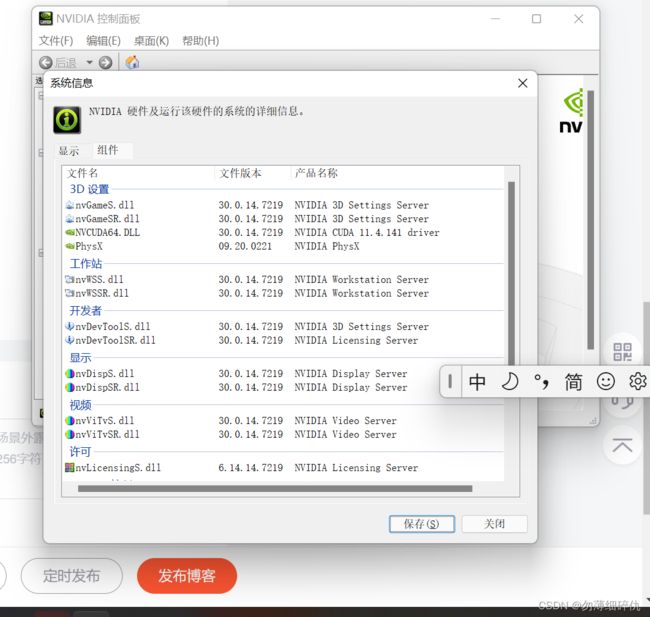
可以看到我们的是11.4.141版本的CUDA,所以咱们下11.4版本的就行。
什么????下载CUDA前还要下载VS????????????????????
我了个大草,能咋办去微软的vs官网下载呗。。。哇!这么多版本选哪个?好在有好在有知乎的保姆教程我成功安装了vs,特喵的期间为了下载一些网盘的东西还特地开了一个超级会员。。。。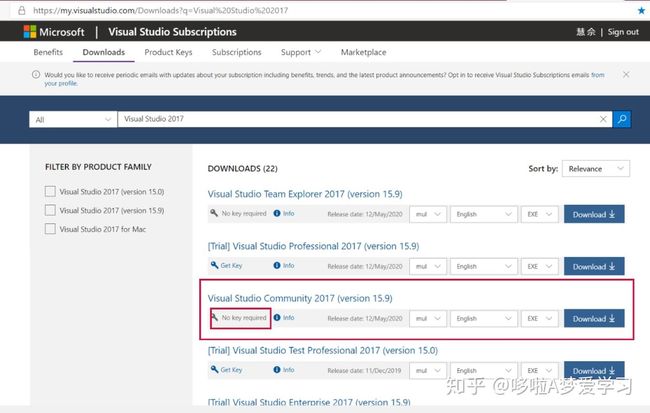
又是一轮漫长的安装,cuda和vs算是装完了。
然后配置各种环境变量

最后验证cuda是否安装成功查看cuda的安装版本,(如果不跑模型的话这个基本用不到)点击进入保姆教程 https://zhuanlan.zhihu.com/p/144311348
https://zhuanlan.zhihu.com/p/144311348
安装ffmpeg(此处看似轻描淡写实则大费周章)
Builds - CODEX FFMPEG @ gyan.dev
打开上面这个链接你就知道我当时多迷茫了,太多下载链接了……好在有度娘

这才哪里到哪里?
为了保证anaconda prompt上下载的速度百度了如何更改下载源
1.执行命令,生成.condarc文件
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes
执行完上述命令后会在当前用户目录下生成.condarc文件
2.确认.condarc文件内容
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- defaults
show_channel_urls: true
3.无误以后关闭窗口重开,确实起飞。
然后安装cuDNN,一行代码搞定
conda install cudnn到此为止我已经基本上算是耗费了一天的时间来操作了,但意外的是我的注意力仍然无比集中,如果不是第二天有课,我感觉我能干个通宵。
接下来我们可以开始下载第三方依赖库
这时候我们的GitHub又开始抽风了一会儿上不去一会上的去,我不得不借助码云来进行下载,这中间也有很多波折,因为是第一次接触这些东西所以很多操作都很陌生,还得借助度娘,比如码云里面通过哪里进行下载,输入网址的哪一些部分进行下载。
https://github.com/babysor/MockingBird/blob/main/README-CN.md
请问这个链接截止到哪里?答案是main为止,可以在码云上通过url下载,那么我之前知道吗?我并不知道。
这个库里面的东西超级多,眼花缭乱。
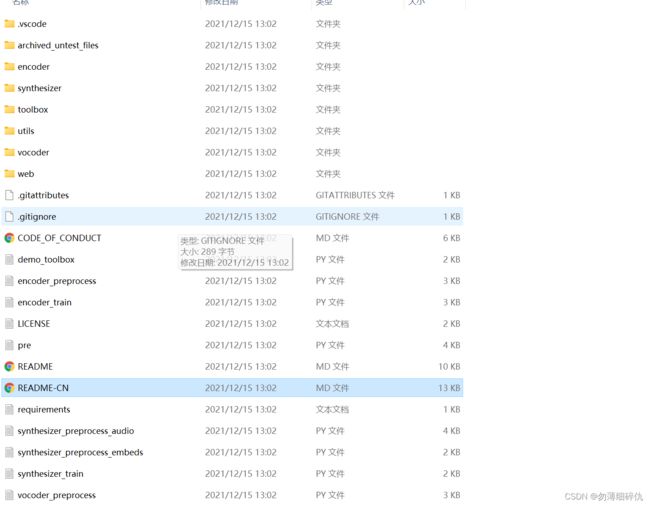
直到后来我才知道这个需要运行这个项目库里的toolbox(工具箱)文件进行操作。
在此之前需要安装requirements.txt里面的各种包
pip install -r requirements.txt
pip install webrtcvad-wheels #另外一个包那么当这个时候我兴致勃勃地运行了代码
python demo_toolbox.py发现在encoder synthesizer 和vocoder里面是没有选项的,经过咨询我才知道还需要模型,要么自己跑,要么借用别人训练好地成品,我义无反顾地选择了后者。
最终成品如下,但是还是会遇到一些问题。
比如说这样的

后来中午的时候我去找学长碰头,经过他的指引在这个项目的issue区里面找到了答案:下载十月二十号左右的版本,新版本和模型不兼容。。。
https://github.com/babysor/MockingBird/issues
又费了些时间我终于跑出来了第一个AI模拟的声音,虽然说效果没有视频那么好吧。。。
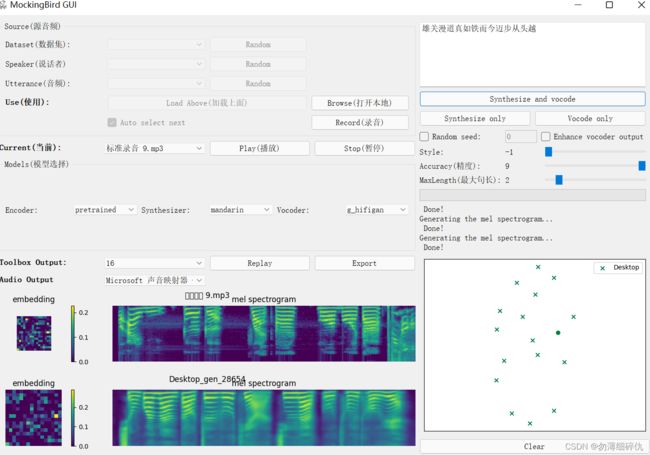
给女朋友看了一下好像说是挺像的。
其实本篇文章并没有把全部过程罗列出来,一来呢是详细的过程太过冗杂,如果全部罗列出来绝对是一项巨大的流水账,写这些一来是响应学长号召养成总结的好习惯,二来呢就是为了体现这第一次的各种青涩与不熟练,现在回头看这些东西其实并不是特别难如果熟练的话并且网络可以一天时间内绝对可以出来,这第一次的成功让我增添了不少的底气,但我知道我还有很多不足,我对于其中的各种代码细节,原理,框架不求甚解,我只能说是照猫画虎,拾人牙慧,可冰冻三尺非一日之寒,希望我能一直保持着一颗学习的心走下去……
在这里我要郑重感谢一下叶学长,如果没有他的不厌其烦的指导,如果没有他给予我的各种帮助,我一个人真的很难做下去,没有一个优秀的引路人单靠自己的一腔热血,大概率会是铩羽而归,真心感谢!!!