【二】BERT and its family
总结
本课讲解了能考虑上下文的预训练模型。预训练模型能大体了解人类语言,在处理具体NLP任务的效果更好
微调模型:训练整个模型(预训练+特定任务层)的参数多模型非常大,提出了adaptor和权重的方法
训练模型的方法:自监督学习,预测token学习依赖关系,学习句子层面的联系。
- 可以跨segment读取的XLNet,对BERT的质疑:打乱输入顺序,不给看mask标记,表现是比较好的。
- 自回归模型状态下,为了让bert解决s2s问题,用自监督训练模型,输入必须做扰动。
- 句子层面的训练:SOP预测顺序问题更难,训练效果更好
讲解了模型发展的三个方向:变大、变小、解决更长的sequence
目录
一、可以读人类语言的预训练模型长什么样,可以做什么事
1、过去的word2vec、Glove、FastText、CNN作图片处理汉字:不考虑上下文
2、Contextualized Word Embedding:ELMo、BERT,考虑上下文的
二、有了预训练模型,如何fine-tune
1、NLP任务的8个分类
2、有一些特定任务的有标记数据,怎么微调模型?
2.1 有两种方法:固定预训练模型参数,只训练特定任务层;训练整个大模型。
三、如何训练一个预训练模型
3.1 自监督学习:把数据分成两部分,用一部分输入去预测另外一部分输入
3.2 训练方法
3.2.1 predict next token:预测下一个token,擅长做生成。如下左图
3.2.2 BERT-masking input,预测盖住位置的内容,不擅长做生成
3.2.3 ELECTRA 不做预测,二元分类问题,判断token是否被置换
3.2.4 Sentence Level 句子层面的embedding,代表整个sequence,学习句子之间的信息
(1)如今流行趋势就是模型越来越大
(2)穷人在做的BERT,小模型
怎么把模型变小
参考资料:各种模型及其压缩技术
(3) 另外一个方向:让模型能读很长的sequence
过去都是一个任务一个模型
现在逐渐迈向:先让机器了解人类语言然后再做各式各样的任务,常见做法是:
1、pre-train:先用大量无标记数据,训练一个能读懂人类语言的模型
2、fine-tune:使用少量有标记资料去微调模型,去解各种NLP任务
一、可以读人类语言的预训练模型长什么样,可以做什么事
预训练模型:输入一排token sequence,输出一排vector sequence。希望把输入的每一个token表示成一个embedding vector,这个vector包含token的语义,含义相近的token会有相近的embedding,这些embedding的某些维度应该可以看出关联性。
1、过去的word2vec、Glove、FastText、CNN作图片处理汉字:不考虑上下文
模型架构:输入一个token,输出一个向量。问题在于同样的token,有同样的embedding。例如:word2vec、Glove。
若用英语作为token,英文词汇非常多,所以使用字母作为token,例如FastText
若用中文作为token,把文字看做一个图片,用CNN处理,期待CNN能学到偏旁部首
2、Contextualized Word Embedding:ELMo、BERT,考虑上下文的
模型架构:输入一个sequence的token,输出一个sequence。使用的是一个很多层的encoder,其中的network可以用LSTM(ELMo)、SA layers(BERT)、Tree-based model(不流行)
二、有了预训练模型,如何fine-tune
有了预训练模型之后,再叠加一层特定任务层,就可以去完成特定的NLP任务

1、NLP任务的8个分类

2、有一些特定任务的有标记数据,怎么微调模型?
2.1 有两种方法:固定预训练模型参数,只训练特定任务层;训练整个大模型。
通常是训练整个模型的,模型过大容易过拟合,但是由于预训练模型已经训练过了,所以影响不大
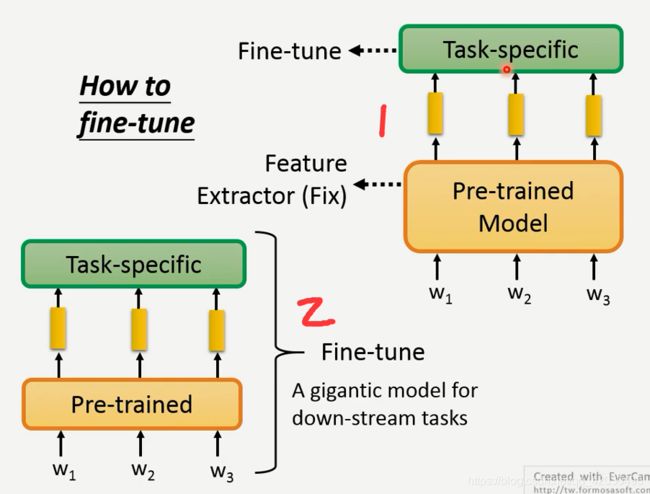
训练整个模型,最后得到的模型是非常大的,所以提出了adaptor
给预训练模型加上adaptor层(只占非常少量的参数),训练时只调adaptor(则存模型的时候,只存不变的模型本身参数,和预训练模型中adaptor的参数。)
adaptor的结构每个文献都不同,哪种好还无定论,

也许每一层抽取的信息是不同的,提出了weighted features
预训练时是让整个模型输入一排token sequence,经过多层输出一排vector,再微调使用到下游任务中去。但是也许每一层抽取的信息是不同的,通过权重相乘来得到一个新的embedding,这个新的embedding综合了所有层的输出,再使用到接下来的任务中去(其中的权重,可以视为特定任务的一部分,和特定任务一起被学习出来)

三、如何训练一个预训练模型
3.1 自监督学习:把数据分成两部分,用一部分输入去预测另外一部分输入
3.2 训练方法
3.2.1 predict next token:预测下一个token,擅长做生成。如下左图
-
如果同时输入所有token,就会偷看到后面的输入,模型就学不到东西。
-
预测下一个token其实就是在训练语言模型(LM)下图就是一个LM,LM都可以做生成。
-
这个方法使模型学习到上下文
(1)使用LSTM的ELMo,如下右图
- 知名使用LSTM的预训练模型
- 也是LM
- 也是希望预训练一个模型微调使用在各式各样的nlp任务中
- 能看到上下文,但都是单独考虑的,不能同时考虑


(2)使用self-attention,例如GPT、Megatron、turing NLG,注意要控制sa的范围,否则会偷看到答案
GPT-2可以做生成,可以产生文章

3.2.2 BERT-masking input,预测盖住位置的内容,不擅长做生成
- 无限制的self-attention,可以随意attend,就可以同时看到上下文
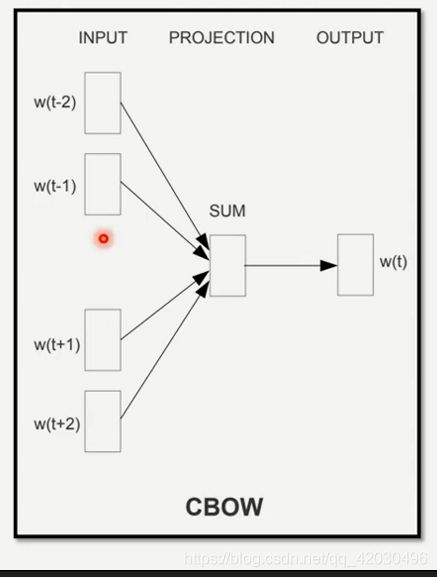
- 与CBOW(word2vec的一种训练方法)相似,CBOW看的不长,模型简单。BERT更复杂有多层transformation,理论上给多长就能看多长的sequence
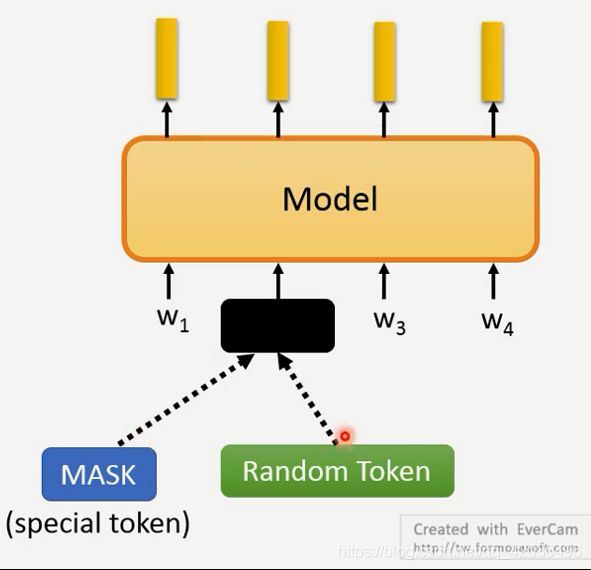
- 原始论文中的mask是随机的,模型可能不用看上下文就可以预测出答案,所以学不到东西。后来提出了复杂的遮盖方法:1、遮住整个单词 2、遮盖短语或者实体(ERNIE)3、spanbert 一次盖一排token,其中的一个训练方法:SBO,用在coreference上比较好
- XLNet:就是Transformer-XL,可以跨segment读取信息,可以有relative positional embedding。
1、XLNet认为BERT的遮盖有问题,但是BERT是随机mask的所以问题不大。
2、从LM角度看:XLNet把输入顺序随机打乱,教模型使用不同的信息去预测,可以学到比较多的依赖;
3、从BERT角度看:不根据整个句子来看,而是只根据一部分来预测遮盖部分。BERT给模型看到了mask token的标记,但是XLNet不给模型看到遮盖的mask,它认为后面的预测是没有mask标记的,但是就要给出位置信息,让模型知道预测的是哪一个
- 在自回归模型状况下,bert不擅长做生成任务,要解决seq2seq的NLP任务需要BERT有生成句子的能力
1、LM本身就可以做到,输入部分句子输出下一个token
2、自回归模型自左而右生成token,要解决s2s任务,那么BERT只能用作encoder,这个为了s2s加入的decoder就没有训练到。
3、能不能直接预训练一个s2s模型?可以的,自监督的方法训练一个预训练模型:输入一排token到encoder,用attention读取一些信息到decoder,输出一排sequence。注意输入的token必须做扰动(MASS:随机遮盖,BART:直接删掉预测内容、颠倒句子位置、改变token顺序、text infilling:随机插入mask+用一个mask盖多个token,这个方法比较好),否则就学不到东西(attention直接复制过来了)
3.2.3 ELECTRA 不做预测,二元分类问题,判断token是否被置换
先用一个小BERT遮盖并预测,替换后让模型识别是否替换
结果是比较好的,GLUE任务上表现是比较好的,同样等级运算量表现更好
注:与GAN(先生成,再识别)不同,GAN的生成器要去骗过识别器,但是这里是各做各的

3.2.4 Sentence Level 句子层面的embedding,代表整个sequence,学习句子之间的信息

NSP:预测下一个句子
SOP:预测句子顺序
(1)如今流行趋势就是模型越来越大

(2)穷人在做的BERT,小模型

怎么把模型变小

参考资料:各种模型及其压缩技术
http://mitchgordon.me/machine/learning/2019/11/18/all-the-ways-to-compress-BERT.html
(3) 另外一个方向:让模型能读很长的sequence
让模型甚至能读一整本书的长度,这些模型的出现就是为了能处理非常长的sequence
