N-gram模型详解
语言模型(Language Model)
基本概念
什么是语言模型?简言之,语言模型可以理解为是一种用于判度一个句子是否通顺的模型。举例来说,假设我们有一个训练好的语言模型 m o d e l model model,给定两个句子:我喜欢AI、喜欢我AI。显然第一个句子更通顺,或者说出现的可能性更大,所以 m o d e l model model,给出的结果就是 P ( 我 喜 欢 A I ) > P ( 喜 欢 我 A I ) P(我喜欢AI)>P(喜欢我AI) P(我喜欢AI)>P(喜欢我AI)。
于是,我们得到了语言模型的目标:计算一个句子或者一列词的概率,即
c o m p u t e : p ( s ) = p ( w 1 , w 2 . . . w n ) compute: p(s)=p(w_1, w_2...w_n) compute:p(s)=p(w1,w2...wn)
Chain Rule
计算上面式子的一个方法是基于概率论中的链式法则,即
p ( w 1 , w 2 , . . . , w n ) = p ( w 1 ) p ( w 2 ∣ w 1 ) p ( w 3 ∣ w 1 , w 2 ) . . . p ( w n ∣ w 1 , w 2 . . . w n − 1 ) p(w_1, w_2, ..., w_n) = p(w_1)p(w2|w1)p(w3|w1, w2)...p(w_n|w_1,w_2...w_{n-1}) p(w1,w2,...,wn)=p(w1)p(w2∣w1)p(w3∣w1,w2)...p(wn∣w1,w2...wn−1)
等式中的条件概率可以基于对语料库的统计来计算。但是不难发现,假设我们的句子比较长,那么我们要找的短语也会很长,而事实上大多数短语在语料库中是不存在的,这就会造成严重的稀疏性。
Markov Assumption
使用链式法则会出现稀疏性问题,因此我们采用马尔科夫假设,即当前事件只依赖于它前一个或者前几个事件。根据依赖事件数量的不同,上述式子有以下几种计算方式:
p ( s ) = p ( w 1 ) p ( w 2 ∣ w 1 ) p ( w 3 ∣ w 2 ) . . . p ( w n ∣ w n − 1 ) = p ( w 1 ) ∏ i = 2 n p ( w i ∣ w i − 1 ) p(s)=p(w_1)p(w_2|w_1)p(w_3|w_2)...p(w_n|w_{n-1}) \\ =p(w_1)\prod_{i=2}^{n}p(w_i|w_{i-1}) p(s)=p(w1)p(w2∣w1)p(w3∣w2)...p(wn∣wn−1)=p(w1)i=2∏np(wi∣wi−1)
p ( s ) = p ( w 1 ) p ( w 2 ∣ w 1 ) p ( w 3 ∣ w 1 , w 2 ) . . . p ( w n ∣ w n − 1 ) = p ( w 1 ) p ( w 2 ∣ w 1 ) ∏ i = 3 n p ( w i ∣ w i − 2 , w i − 1 ) p(s)=p(w_1)p(w_2|w_1)p(w_3|w_1, w_2)...p(w_n|w_n-1) \\ =p(w_1)p(w_2|w_1)\prod_{i=3}^{n}p(w_i|w_{i-2},w_{i-1}) p(s)=p(w1)p(w2∣w1)p(w3∣w1,w2)...p(wn∣wn−1)=p(w1)p(w2∣w1)i=3∏np(wi∣wi−2,wi−1)
当然,还可以依赖于三个词、四个词……但是依赖的词越多,计算出的概率精度可能就越低。
N-gram模型
N-gram模型是基于马尔科夫假设的一系列基础的语言模型。具体可以分为unigram, bigram, trigram, n-gram。
分类
Unigram
如果我们考虑词语都是独立的,或者说每个词只依赖于其本身,那么目标函数可以改写为
p ( s ) = p ( w 1 ) p ( w 2 ) . . . p ( w n ) = ∏ i = 1 n p ( w i ) p(s)=p(w_1)p(w_2)...p(w_n) \\ =\prod_{i=1}^{n}p(w_i) p(s)=p(w1)p(w2)...p(wn)=i=1∏np(wi)
Bigram
根据first order的马尔科夫假设,即每个词依赖于它的前一个词
p ( s ) = p ( w 1 ) p ( w 2 ∣ w 1 ) p ( w 3 ∣ w 2 ) . . . p ( w n ∣ w n − 1 ) = p ( w 1 ) ∏ i = 2 n p ( w i ∣ w i − 1 ) p(s)=p(w_1)p(w_2|w_1)p(w_3|w_2)...p(w_n|w_{n-1}) \\ =p(w_1)\prod_{i=2}^{n}p(w_{i}|w_{i-1}) p(s)=p(w1)p(w2∣w1)p(w3∣w2)...p(wn∣wn−1)=p(w1)i=2∏np(wi∣wi−1)
Trigram
根据second order的马尔科夫假设,即每个词依赖于它的前两个词
p ( s ) = p ( w 1 ) p ( w 2 ∣ w 1 ) p ( w 3 ∣ w 1 , w 2 ) . . . p ( w n ∣ w n − 2 , w n − 1 ) = p ( w 1 ) p ( w 2 ∣ w 1 ) ∏ i = 3 n p ( w i ∣ w i − 2 , w i − 1 ) p(s)=p(w_1)p(w_2|w_1)p(w_3|w_1,w_2)...p(w_n|w_{n-2},w_{n-1})\\ =p(w_1)p(w_2|w_1)\prod_{i=3}^{n}p(w_i|w_{i-2},w_{i-1}) p(s)=p(w1)p(w2∣w1)p(w3∣w1,w2)...p(wn∣wn−2,wn−1)=p(w1)p(w2∣w1)i=3∏np(wi∣wi−2,wi−1)
N-gram
事实上, N > 2 N\gt2 N>2的模型都被称为N-gram模型,常用的 N N N一般为1,2,3
模型的训练
N-gram模型是基于对语料库的统计来进行训练的,举例来说,对于Bigram模型,我们要计算 p ( c a t ∣ t h e ) p(cat|the) p(cat∣the),那么公式为
p ( c a t ∣ t h e ) = C ( t h e , c a t ) C ( t h e ) p(cat|the) = \frac{C(the, cat)}{C(the)} p(cat∣the)=C(the)C(the,cat)
其中 C ( w i ) C(w_i) C(wi)表示语料库中单词 w i w_i wi出现的次数。
仍然以Bigram模型为例,我们的目标函数是
J = p ( w 1 ) ∏ i = 2 n p ( w i ∣ w i − 1 ) J=p(w_1)\prod_{i=2}^np(w_i|w_{i-1}) J=p(w1)i=2∏np(wi∣wi−1)
由于又涉及到多个概率连乘问题,所以我们映射到对数空间,即
J , = l o g ( J ) = l o g [ p ( w 1 ) ] + ∑ i = 2 n l o g [ p ( w i ∣ w i − 1 ) ] J^, = log(J) = log[p(w_1)]+\sum_{i=2}^nlog[p(w_i|w_{i-1})] J,=log(J)=log[p(w1)]+i=2∑nlog[p(wi∣wi−1)]
我们的任务是最大化这个对数似然,因此这种参数估计的方式就叫做MLE(Maximum Log Likelihood)
模型的平滑
在实际预测过程中,我们往往会遇到没有出现过的组合形式,举例来说:
我们的语料库是:“我 非常 喜欢 AI”,“我 喜欢 你”, “AI 是 全民 趋势”,而给定的任务是计算 p ( 你 喜 欢 A I ) p(你喜欢AI) p(你喜欢AI)。假设我们的模型是Bigram,那么这个概率就是:
p ( 你 喜 欢 我 ) = p ( 你 ) p ( 喜 欢 ∣ 你 ) p ( A I ∣ 喜 欢 ) p(你 喜欢 我)=p(你)p(喜欢|你)p(AI|喜欢) p(你喜欢我)=p(你)p(喜欢∣你)p(AI∣喜欢)
而我们在语料库没有找到“你 喜欢”这种组合,即 C ( 你 , 喜 欢 ) = 0 C(你, 喜欢)=0 C(你,喜欢)=0。那么这样一来整个概率值就是0,这显然是不合适的。为了解决这种问题,我们引入语言模型的平滑,下面介绍三种方法
Add-One Smoothing
Add One Smoothing又被称为拉普拉斯平滑,它的计算公式是(以Bigram为例)
p a d d − 1 ( w i ∣ w i − 1 ) = C ( w i − 1 , w i ) + 1 C ( w i − 1 ) + V p_{add-1}(w_i|w_{i-1})=\frac{C(w_{i-1},w_i)+1}{C(w_{i-1})+V} padd−1(wi∣wi−1)=C(wi−1)+VC(wi−1,wi)+1
即给每个Bigram分子加1,分母加词库大小V。分母加V的目的是保证概率和为1。下面这四张图(两组)清晰地说明了这种方法
Original


After add-one smoothing

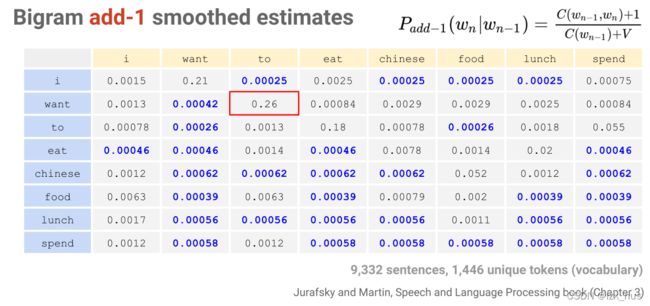
但是,这种方法的一个潜在问题就是,它会降低一些原有组合的置信度,详见红框标出的位置。
Add-K Smoothing
在add-one smoothing的基础之上,又提出了add-k smoothing,这种方法与add-one smoothing原理相同,只是扩大了K倍,即
p a d d − k ( w i − 1 ∣ w i ) = C ( w i − 1 , w i ) + k C ( w i − 1 ) + k ∗ V p_{add-k}(w_{i-1}|w_i)=\frac{C(w_{i-1},w_i)+k}{C(w_{i-1})+k*V} padd−k(wi−1∣wi)=C(wi−1)+k∗VC(wi−1,wi)+k
Interpolation
Interpolation利用的是一种融合的思想,它所解决的是这样的问题:
加入我们的语料库中有“in the”,“kitchen”,而我们要预测的是“in the kitchen”和“in the hell”。显然,如果利用Trigram模型,这两个结果都是0。
所以Interpolation考虑的就是综合利用Unigram、Bigram、Trigram信息以避免出现zero term。具体的计算公式为(以Trigram为例):
p ( w i ∣ w i − 2 , w i − 1 ) = λ 1 p ( w i ∣ w i − 2 , w i − 1 ) + λ 2 p ( w i ∣ w i − 1 ) + λ 3 p ( w i ) p(w_{i}|w_{i-2},w_{i-1})=\lambda_1p(w_i|w_{i-2},w_{i-1})+\lambda_2p(w_i|w_{i-1})+\lambda_3p(w_i) p(wi∣wi−2,wi−1)=λ1p(wi∣wi−2,wi−1)+λ2p(wi∣wi−1)+λ3p(wi)
其中, λ 1 + λ 2 + λ 3 = 1 \lambda_1+\lambda_2+\lambda_3=1 λ1+λ2+λ3=1。其实Interpolation做的是对多种N-gram模型的结果的加权平均
模型的评估
对于语言模型,我们的评估指标叫做困惑度perplexity。ppl的计算有两种公式,以Bigram为例:
1 、 P P L ( M ) = p ( w 1 , w 2 , . . . , w n ) − 1 n = 1 p ( w 1 ) ∏ i = 2 n p ( w i ∣ w i − 1 ) n 1、PPL(M)=p(w_1, w_2, ..., w_n)^{-\frac{1}{n}}=\sqrt[n]{\frac{1}{p(w_1)\prod_{i=2}^n{p(w_i|w_{i-1})}}} 1、PPL(M)=p(w1,w2,...,wn)−n1=np(w1)∏i=2np(wi∣wi−1)1
2 、 P P L ( M ) = 2 − x , x = 1 / n ∑ i = 2 n p ( w i ∣ w i − 1 ) 2、PPL(M)=2^{-x},x=1/n\sum_{i=2}^np(w_i|w_{i-1}) 2、PPL(M)=2−x,x=1/ni=2∑np(wi∣wi−1)
第二种公式中, x x x为average log likelihood