【深入浅出PyTorch】4-基础实战-FashionMINIST
4-基础实战
文章目录
- 4-基础实战
-
- 2.1-神经网络学习机制
- 2.2-深度学习在实现上的特殊性
- 2.3-PyTorch的深度学习模块
-
-
- 2.3.1-基本配置
- 2.3.2-数据读入
- 2.3.3-模型构建
- 2.3.4-损失函数
- 2.3.4-优化器
- 2.3.5-训练与评估
-
2.1-神经网络学习机制
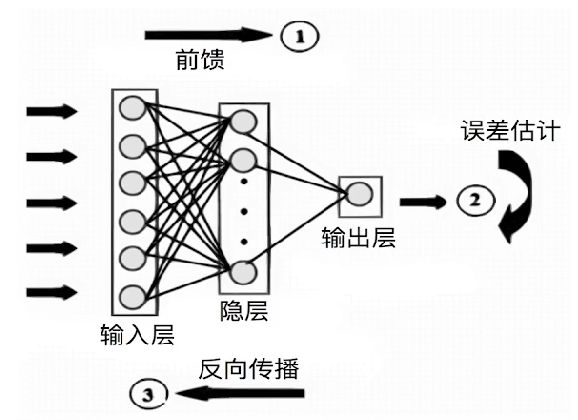
2.2-深度学习在实现上的特殊性
- 样本量大,需要分批(Batch)加载
- 逐层、模块化搭建网络(卷积层、全连接层、LSTM层)
- 多样化的损失函数和优化器设计*
- GPU使用
- 以上各个模块的配合
2.3-PyTorch的深度学习模块
- 边学边练,通过实战案例巩固模块知识学习
- 任务:FashionMINIST时装分类
- 数据简介
- 10类图片
- 32*32px

代码:2.3-FashionMINIST实战
2.3.1-基本配置
- 导入基本包
os,numpy,pandas,torch.nn,torch.optim,torch.utils.data
- 超参数
batch size,learning rate,max_epochs,num_workers
- 硬件
import os
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
# 配置GPU,这里有两种方式
## 方案一:使用os.environ
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
# 方案二:使用“device”,后续对要使用GPU的变量用.to(device)即可
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
## 配置其他超参数,如batch_size, num_workers, learning rate, 以及总的epochs
batch_size = 256
num_workers = 4 # 对于Windows用户,这里应设置为0,否则会出现多线程错误
lr = 1e-4
epochs = 20
设置数字变换
# 首先设置数据变换
from torchvision import transforms
# 图片大小为32,手写数字为28,当然多少没关系
image_size = 28
data_transform = transforms.Compose([
# 使用 PIL 库图像
# 取决于内置数据集
transforms.ToPILImage(),
# 这一步取决于后续的数据读取方式,如果使用内置数据集读取方式则不需要
transforms.Resize(image_size),
transforms.ToTensor() # 以tensor形式输入到表格中
])
2.3.2-数据读入
通过Dataset类读取数据
函数:__init__,__getitem__,__len__
通过DataLoader加载数据以供模型输入
用自带方法读取数据
from torchvision import datasets
train_data = datasets.FashionMNIST(root='./', train=True, download=True, transform=data_transform)
test_data = datasets.FashionMNIST(root='./', train=False, download=True, transform=data_transform)
自定义读取
# csv数据下载链接:https://www.kaggle.com/zalando-research/fashionmnist
class FMDataset(Dataset):
def __init__(self, df, transform=None):
# dataframe
self.df = df
# 施加的变化
self.transform = transform
self.images = df.iloc[:,1:].values.astype(np.uint8)
self.labels = df.iloc[:, 0].values
def __len__(self):
return len(self.images)
# idx = index
def __getitem__(self, idx):
# 强行转换为28*28大小,带一通道的图片
image = self.images[idx].reshape(28,28,1)
# 预测的目标
label = int(self.labels[idx])
# 必须变成tensor格式
if self.transform is not None:
image = self.transform(image)
else:
image = torch.tensor(image/255., dtype=torch.float)
label = torch.tensor(label, dtype=torch.long)
return image, label
train_df = pd.read_csv("./FashionMNIST/fashion-mnist_train.csv")
test_df = pd.read_csv("./FashionMNIST/fashion-mnist_test.csv")
train_data = FMDataset(train_df, data_transform)
test_data = FMDataset(test_df, data_transform)
装载数据
# 训练集,批次个数,是否打乱,读取的线程数,是否需要最后一个数据(最后一个batch)不够数量
# pin_memory 拿空间换时间的一个操作
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False, num_workers=num_workers)
2.3.3-模型构建
基于nn.Module的CNN
定义网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 卷积,Sequential顺序模型,顺序在参数中
self.conv = nn.Sequential(
nn.Conv2d(1, 32, 5),
nn.ReLU(),
nn.MaxPool2d(2, stride=2),
nn.Dropout(0.3),
nn.Conv2d(32, 64, 5),
nn.ReLU(),
nn.MaxPool2d(2, stride=2),
nn.Dropout(0.3)
)
# 全连接层
self.fc = nn.Sequential(
# 改变大小到512
nn.Linear(64*4*4, 512),
nn.ReLU(),
# 改变大小到10, 对应10类
nn.Linear(512, 10)
)
# 前馈,x:输入
def forward(self, x):
x = self.conv(x)
x = x.view(-1, 64*4*4)
x = self.fc(x)
# x = nn.functional.normalize(x)
return x
model = Net()
# 所有放到GPU的模型都需要执行 XXX.cuda()
model = model.cuda()
# model = nn.DataParallel(model).cuda() # 多卡训练时的写法,之后的课程中会进一步讲解
2.3.4-损失函数
criterion = nn.CrossEntropyLoss()
# 可以给不同类设定权重
# criterion = nn.CrossEntropyLoss(weight=[1,1,1,1,3,1,1,1,1,1])
2.3.4-优化器
这里我们使用Adam优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
2.3.5-训练与评估
定义训练函数
def train(epoch):
model.train()
train_loss = 0
for data, label in train_loader:
data, label = data.cuda(), label.cuda()
# 将梯度置为0,否则会一直累计
optimizer.zero_grad()
output = model(data)
loss = criterion(output, label)
loss.backward()
optimizer.step()
train_loss += loss.item()*data.size(0)
train_loss = train_loss/len(train_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, train_loss))
定义验证函数
def val(epoch):
model.eval()
val_loss = 0
gt_labels = []
pred_labels = []
with torch.no_grad():
for data, label in test_loader:
data, label = data.cuda(), label.cuda()
output = model(data)
preds = torch.argmax(output, 1)
gt_labels.append(label.cpu().data.numpy())
pred_labels.append(preds.cpu().data.numpy())
loss = criterion(output, label)
val_loss += loss.item()*data.size(0)
val_loss = val_loss/len(test_loader.dataset)
gt_labels, pred_labels = np.concatenate(gt_labels), np.concatenate(pred_labels)
acc = np.sum(gt_labels==pred_labels)/len(pred_labels)
print('Epoch: {} \tValidation Loss: {:.6f}, Accuracy: {:6f}'.format(epoch, val_loss, acc))
训练并保存模型
for epoch in range(1, epochs+1):
train(epoch)
val(epoch)
save_path = "./FahionModel.pkl"
torch.save(model, save_path)