Matlab中的深度学习——CNN图像分类实例
我测试了一下,matlab2022a 可以运行。matlab2018之后的应该都可以。因为CNN是比较简单,比较经典的网络。matlab很早就支持了
一起来学习一个Matlab环境下运用卷积神经神经网络(CNN)实现图像分类的小栗子,力争用最通俗的语言进行解释,闲话不多说,咱直接上干货。
环境要求:Matlab2018a及以上版本(18a版本开始提供Deep Learning Toolbox的工具箱,正式拉开了Matlab进军深度学习领域的序幕);
数据集:大多图像分类的Benchmark数据集都会使用到MNIST,但是由于使用的实在太多了,以及分类的难度确实不大,所以我们今天分享一个相似的但是难度稍大的数据集,名字叫notMNIST,附上数据集的链接:
http://yaroslavvb.blogspot.com


代码部分:
为了尽可能的把demo写的浅显易懂,也为了其他小伙伴可以直接套用此模型来跑自己的数据,我们尽可能地不使用复杂晦涩的函数,努力做到步子小一点,注释多一点。
demo中使用的数据集(下载后和程序放在一个文件夹下,不用改路径,直接运行程序即可):
链接:https://pan.baidu.com/s/1JnS6yfnoxTNg1d0_atpGHg
提取码:hw89
% 数据集来源:
% http://yaroslavvb.blogspot.com/2011/09/notmnist-dataset.html
% matlab deep learning toolbox 官方使用说明:
% https://www.mathworks.com/help/deeplearning/ref/trainnetwork.html#d120e82918
% 知乎:夏明朗 2020-05-29
clc
clear
close all
% 读取数据
load('notMNIST_small.mat')
% 选取部分数据可视化
for i=1:1:32
subplot(4,8,i);
imshow(images(:,:,555*i)/255)
end
%
X = reshape(images, [28,28,1,length(images)]); % 灰度图片的作为输入的要求为h*w**c*s,
% 其中h为图片的长度,w为宽度,c为通道数,s就是数据的个数
size(X) % 可以看到我们的数据集尺寸为:28*28*1*18724
Y = categorical(labels); % 标签的数据类型为categorical
idx = randperm(length(images)); % 产生一个和数据个数一致的随机数序列
num_train = round(0.5*length(X)); % 训练集个数,0.5表示全部数据中随机选取50%作为训练集
num_val = round(0.3*length(X)); % 验证集个数,0.3表示全部数据中随机选取30%作为验证集,故测试集自动变为剩下的20%
% 训练集,验证集和测试集数据
X_train = X(:,:,:,idx(1:num_train));
X_val = X(:,:,:,idx(num_train+1:num_train+num_val));
X_test = X(:,:,:,idx(num_train+num_val+1:end)); %这里假设,全部数据中除了
% 训练集,验证集和测试集标签
Y_train = Y(idx(1:num_train),:);
Y_val = Y(idx(num_train+1:num_train+num_val),:);
Y_test = Y(idx(num_train+num_val+1:end),:);以上代码主要实现了数据的导入以及数据集的随机划分,未使用一步到位的函数,这样大家就可以在工作区清楚的看到每一步是怎样实现的。这里解释randperm( )函数,其可随机产生一个和样本个数相同数目的序列,例如共有10个样本,那么randperm(10)的结果可能为
8 3 10 5 2 4 1 7 9 6因此我们使用这个随机序列就可以实现数据集的随机划分,本程序设置训练集数据占50%,验证集数据占30%,测试集数据就占剩余的20%。数据集准备完成后,我们就开始搭建CNN网络
%% 定义网络层
layers = [...
imageInputLayer([28,28,1]); % 输入层,要正确输入图片的height, width 和 number of channels of the images
batchNormalizationLayer(); % 批量归一化
convolution2dLayer(5,20); % 卷积层
batchNormalizationLayer();
reluLayer() % Relu激活函数
maxPooling2dLayer(2,'Stride',2); % 池化层
fullyConnectedLayer(10); % 全连接层
softmaxLayer(); % softmax层
classificationLayer(),...
];
这里定义的CNN网络又1个卷积层、1个池化层和1个全连接层组成,其中还使用了批量归一化操作,当然也可以加入dropout来防止过拟合。至于网络结构的设计就属于“炼丹”的范畴了,没有一个统一的标准,因人而异,需要大家自己慢慢体会了。
下面我们简单介绍没有验证集和有验证集的区别:
没有验证集情况
% 参数
options = trainingOptions('sgdm',... % 也可以用adam、rmsprop等方法
'MaxEpochs',50,... % 最大迭代次数
'Plots','training-progress');
net_cnn = trainNetwork(X_train,Y_train,layers,options); 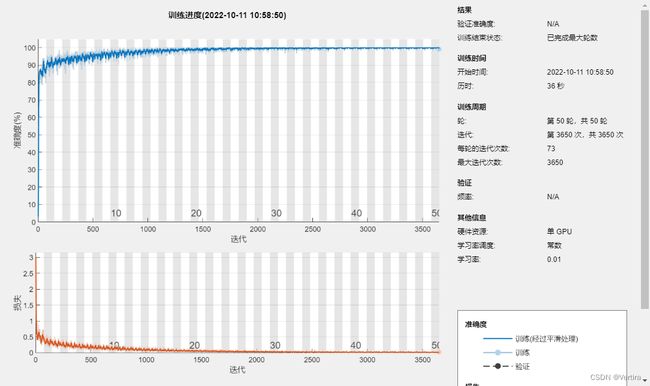
没有验证集曲线,我的电脑就一个GPU。训练非常快。Matlab2022非常强大,自动调用GPU,不需要配置。
没有验证集合训练过程会迭代到最大迭代步数,并且左侧图像中没有验证集的曲线。这里有一个问题,如果我们遇到复杂的问题,模型中又缺少防止过拟合的操作(批量归一化,dropout,正则化或大数据集都可以防止过拟合),那么最终结果极有可能会出现过拟合,这当然是我们不想出现的情况。因此,如何判断模型训练是否“恰到好处”,我们应该引入验证集帮助我们进行判断。
有验证集的情况
% 参数
options = trainingOptions('sgdm',... % 也可以用adam、rmsprop等方法
'MiniBatchSize',128, ...
'MaxEpochs',50,... % 最大迭代次数
'ValidationData',{X_val,Y_val},... % 显示验证集误差
'Verbose',true, ... % 命令窗口显示训练过程的各种指标
'Shuffle','every-epoch', ...
'InitialLearnRate',1e-2,...
'Plots','training-progress');
net_cnn = trainNetwork(X_train,Y_train,layers,options); 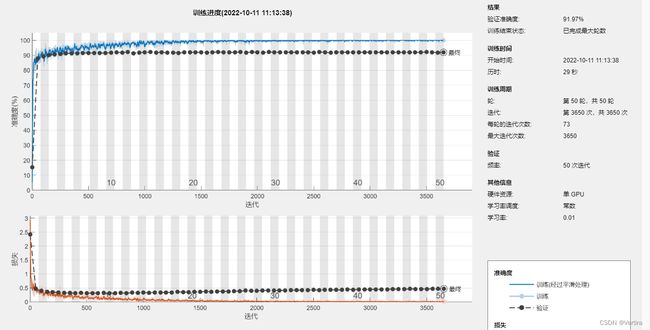
options 中我们加入了更多的人为设置的参数,这样稍微高级的定义会使得模型训练的更符合你的要求。加入验证集后,我们可以看到训练过程“早停”了,Epoch只迭代了8次模型就训练过程就结束了,原因如绿框内容所示,Patience为5表示:如果5步迭代中验证集的loss都没有减小的话,训练就终止了。在绝大数情况下,这种早停的机制会防止模型过度训练从而出现过拟合的现象。
最终我们使用测试集验证模型的泛化能力即可,相应代码与结果如下
% 测试
testLabel = classify(net_cnn,X_test);
precision = sum(testLabel==Y_test)/numel(testLabel);
disp(['测试集分类准确率为',num2str(precision*100),'%'])在单 GPU 上训练。
正在初始化输入数据归一化。
|=============================================================================|
| 轮 | 迭代 | 经过的时间 | 小批量准确度 | 验证准确度 | 小批量损失 | 验证损失 | 基础学习率 |
| | | (hh:mm:ss) | | | | | |
|=============================================================================|
| 1 | 1 | 00:00:01 | 5.47% | 15.19% | 2.9331 | 2.4121 | 0.0100 |
| 1 | 50 | 00:00:02 | 87.50% | 87.80% | 0.4813 | 0.4667 | 0.0100 |
| 2 | 100 | 00:00:02 | 86.72% | 89.18% | 0.4289 | 0.3996 | 0.0100 |
| 3 | 150 | 00:00:03 | 91.41% | 90.24% | 0.2862 | 0.3596 | 0.0100 |
| 3 | 200 | 00:00:03 | 96.09% | 90.64% | 0.1928 | 0.3462 | 0.0100 |
| 4 | 250 | 00:00:03 | 92.19% | 90.88% | 0.3221 | 0.3343 | 0.0100 |
| 5 | 300 | 00:00:04 | 96.09% | 91.22% | 0.1528 | 0.3249 | 0.0100 |
| 5 | 350 | 00:00:04 | 95.31% | 91.42% | 0.1762 | 0.3231 | 0.0100 |
| 6 | 400 | 00:00:04 | 94.53% | 91.42% | 0.1887 | 0.3138 | 0.0100 |
| 7 | 450 | 00:00:05 | 95.31% | 91.56% | 0.1311 | 0.3226 | 0.0100 |
| 7 | 500 | 00:00:05 | 94.53% | 91.60% | 0.2010 | 0.3162 | 0.0100 |
| 8 | 550 | 00:00:06 | 97.66% | 91.51% | 0.1032 | 0.3149 | 0.0100 |
| 9 | 600 | 00:00:06 | 96.88% | 91.63% | 0.1052 | 0.3155 | 0.0100 |
| 9 | 650 | 00:00:07 | 95.31% | 91.47% | 0.1810 | 0.3241 | 0.0100 |
| 10 | 700 | 00:00:07 | 95.31% | 91.86% | 0.1714 | 0.3145 | 0.0100 |
| 11 | 750 | 00:00:07 | 99.22% | 92.01% | 0.0449 | 0.3117 | 0.0100 |
| 11 | 800 | 00:00:08 | 92.19% | 91.85% | 0.1895 | 0.3241 | 0.0100 |
| 12 | 850 | 00:00:08 | 98.44% | 92.18% | 0.0882 | 0.3132 | 0.0100 |
| 13 | 900 | 00:00:08 | 98.44% | 91.42% | 0.0625 | 0.3320 | 0.0100 |
| 14 | 950 | 00:00:09 | 98.44% | 91.86% | 0.0657 | 0.3219 | 0.0100 |
| 14 | 1000 | 00:00:09 | 95.31% | 91.95% | 0.1356 | 0.3357 | 0.0100 |
| 15 | 1050 | 00:00:10 | 98.44% | 92.15% | 0.1065 | 0.3287 | 0.0100 |
| 16 | 1100 | 00:00:10 | 99.22% | 91.83% | 0.0362 | 0.3364 | 0.0100 |
| 16 | 1150 | 00:00:10 | 97.66% | 92.02% | 0.0595 | 0.3329 | 0.0100 |
| 17 | 1200 | 00:00:11 | 100.00% | 91.67% | 0.0278 | 0.3416 | 0.0100 |
| 18 | 1250 | 00:00:11 | 99.22% | 91.85% | 0.0447 | 0.3399 | 0.0100 |
| 18 | 1300 | 00:00:12 | 97.66% | 91.51% | 0.0715 | 0.3603 | 0.0100 |
| 19 | 1350 | 00:00:12 | 97.66% | 92.01% | 0.0748 | 0.3492 | 0.0100 |
| 20 | 1400 | 00:00:12 | 100.00% | 92.01% | 0.0423 | 0.3480 | 0.0100 |
| 20 | 1450 | 00:00:13 | 98.44% | 91.95% | 0.0614 | 0.3597 | 0.0100 |
| 21 | 1500 | 00:00:13 | 98.44% | 92.01% | 0.0278 | 0.3610 | 0.0100 |
| 22 | 1550 | 00:00:13 | 100.00% | 91.81% | 0.0236 | 0.3707 | 0.0100 |
| 22 | 1600 | 00:00:14 | 100.00% | 92.02% | 0.0307 | 0.3661 | 0.0100 |
| 23 | 1650 | 00:00:14 | 100.00% | 92.17% | 0.0213 | 0.3791 | 0.0100 |
| 24 | 1700 | 00:00:14 | 100.00% | 92.04% | 0.0163 | 0.3731 | 0.0100 |
| 24 | 1750 | 00:00:15 | 100.00% | 91.94% | 0.0230 | 0.3790 | 0.0100 |
| 25 | 1800 | 00:00:15 | 98.44% | 91.90% | 0.0842 | 0.3912 | 0.0100 |
| 26 | 1850 | 00:00:16 | 99.22% | 92.22% | 0.0257 | 0.3819 | 0.0100 |
| 27 | 1900 | 00:00:16 | 100.00% | 91.81% | 0.0135 | 0.4069 | 0.0100 |
| 27 | 1950 | 00:00:16 | 100.00% | 92.11% | 0.0110 | 0.3969 | 0.0100 |
| 28 | 2000 | 00:00:17 | 100.00% | 92.06% | 0.0131 | 0.3956 | 0.0100 |
| 29 | 2050 | 00:00:17 | 100.00% | 91.76% | 0.0183 | 0.4135 | 0.0100 |
| 29 | 2100 | 00:00:17 | 100.00% | 92.22% | 0.0146 | 0.4071 | 0.0100 |
| 30 | 2150 | 00:00:18 | 100.00% | 92.01% | 0.0093 | 0.4090 | 0.0100 |
| 31 | 2200 | 00:00:18 | 100.00% | 92.04% | 0.0128 | 0.4105 | 0.0100 |
| 31 | 2250 | 00:00:18 | 99.22% | 92.10% | 0.0370 | 0.4144 | 0.0100 |
| 32 | 2300 | 00:00:19 | 100.00% | 91.94% | 0.0106 | 0.4172 | 0.0100 |
| 33 | 2350 | 00:00:19 | 99.22% | 91.97% | 0.0360 | 0.4186 | 0.0100 |
| 33 | 2400 | 00:00:20 | 100.00% | 91.95% | 0.0049 | 0.4258 | 0.0100 |
| 34 | 2450 | 00:00:20 | 100.00% | 92.08% | 0.0124 | 0.4201 | 0.0100 |
| 35 | 2500 | 00:00:20 | 100.00% | 91.85% | 0.0109 | 0.4297 | 0.0100 |
| 35 | 2550 | 00:00:21 | 99.22% | 92.22% | 0.0298 | 0.4228 | 0.0100 |
| 36 | 2600 | 00:00:21 | 100.00% | 91.97% | 0.0055 | 0.4364 | 0.0100 |
| 37 | 2650 | 00:00:21 | 100.00% | 91.72% | 0.0104 | 0.4379 | 0.0100 |
| 37 | 2700 | 00:00:22 | 100.00% | 92.06% | 0.0157 | 0.4318 | 0.0100 |
| 38 | 2750 | 00:00:22 | 100.00% | 92.06% | 0.0102 | 0.4319 | 0.0100 |
| 39 | 2800 | 00:00:22 | 100.00% | 91.97% | 0.0042 | 0.4479 | 0.0100 |
| 40 | 2850 | 00:00:23 | 100.00% | 91.95% | 0.0085 | 0.4389 | 0.0100 |
| 40 | 2900 | 00:00:23 | 100.00% | 91.88% | 0.0076 | 0.4460 | 0.0100 |
| 41 | 2950 | 00:00:24 | 100.00% | 92.08% | 0.0077 | 0.4442 | 0.0100 |
| 42 | 3000 | 00:00:24 | 100.00% | 91.94% | 0.0111 | 0.4472 | 0.0100 |
| 42 | 3050 | 00:00:24 | 99.22% | 91.95% | 0.0189 | 0.4486 | 0.0100 |
| 43 | 3100 | 00:00:25 | 100.00% | 91.95% | 0.0076 | 0.4513 | 0.0100 |
| 44 | 3150 | 00:00:25 | 100.00% | 91.97% | 0.0027 | 0.4502 | 0.0100 |
| 44 | 3200 | 00:00:25 | 100.00% | 92.02% | 0.0093 | 0.4604 | 0.0100 |
| 45 | 3250 | 00:00:26 | 100.00% | 91.88% | 0.0069 | 0.4561 | 0.0100 |
| 46 | 3300 | 00:00:26 | 100.00% | 91.92% | 0.0043 | 0.4533 | 0.0100 |
| 46 | 3350 | 00:00:26 | 100.00% | 91.92% | 0.0064 | 0.4670 | 0.0100 |
| 47 | 3400 | 00:00:27 | 100.00% | 91.94% | 0.0073 | 0.4642 | 0.0100 |
| 48 | 3450 | 00:00:27 | 100.00% | 91.92% | 0.0050 | 0.4624 | 0.0100 |
| 48 | 3500 | 00:00:28 | 100.00% | 92.24% | 0.0074 | 0.4618 | 0.0100 |
| 49 | 3550 | 00:00:28 | 99.22% | 91.97% | 0.0167 | 0.4710 | 0.0100 |
| 50 | 3600 | 00:00:28 | 100.00% | 91.86% | 0.0035 | 0.4692 | 0.0100 |
| 50 | 3650 | 00:00:29 | 100.00% | 92.06% | 0.0147 | 0.4677 | 0.0100 |
|=============================================================================|
训练结束: 已完成最大轮数。
测试集分类准确率为92.3364%测试集分类准确为92.0961%,效果还可以接受。如果你有兴趣,更换模型拓扑结构、优化算法、激活函数等等,可能会得到更好的分类结果。
今天分享的例子大家按照流程一步一步操作,肯定都能跑通,使用Matlab做深度学习适应于于以下人群:
1.熟悉Matlab但不熟悉Python语言的小伙伴;
2.刚刚接触深度学习,想要将理论迅速实现的小伙伴;
3.不需要state-of-art模型的,只需要将经典深度学习模型应用到自己研究领域的小伙伴
其中以上分享的Matlab中深度学习的代码,与Keras很像,都是“搭积木”的形式将模型拼凑起来而已,但是如果真的想进一步深入研究深度学习,或者是对现有模型进行改进创新,那么Matlab中提供的工具包集成度就显得太高了,pytorch或tensorflow或许更合适。但是不过怎么说,Matlab至少在深度学习领域迈出了一大步,可喜可贺。
如果对你有用,欢迎点赞,收藏,加关注,后面会持续免费更新新内容
参考:
Matlab中的深度学习——CNN图像分类实例 - 知乎 (zhihu.com)