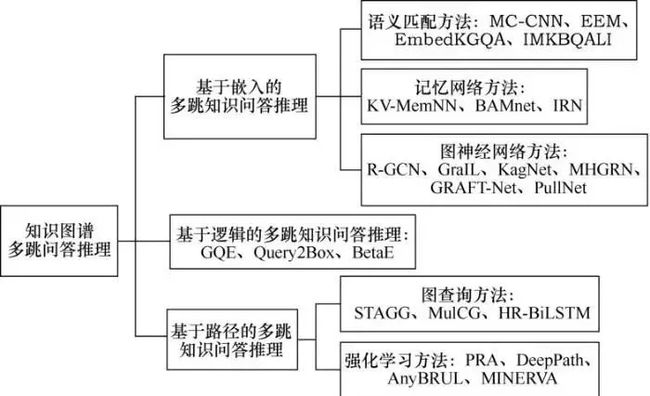
知识图谱-多跳推理问答-模型-2020:EmbedKGQA【第一个将KGE用于多跳推理问答任务的方法】【直接通过score=φ(q,e_h,e_a‘)从KG中选择答案实体】
一、概述
1、动机
在多跳KGQA中,系统需要对KG的多个边缘执行推理以推断出正确的答案。 KG通常不完整,这给KGQA系统带来了额外的挑战,尤其是在多跳KGQA的情况下。最近的方法已使用外部文本语料库来处理KG稀疏性。而本文期望通过利用KG embedding的链接预测属性,不依赖外部数据解决KG不完整问题。
2、贡献
提出了EmbedKGQA,一种用于多跳KGQA任务的新方法。EmbedKGQA是第一个将KG嵌入用于此任务的方法。EmbedKGQA在执行稀疏KG上的多跳KGQA方面特别有效。
EmbedKGQA放宽了从预先指定的本地邻居选择答案的要求,这是先前方法中不受欢迎的一个约束。
通过在多个现实世界数据集上进行的广泛实验,证明了EmbedKGQA取得了STOA的效果。
二、数据集:MetaQA数据
实验数据集是MetaQA数据集,该数据集是基于电影知识图谱的电影问答。MetaQA数据集下载
数据集MetaQA:一个是电影领域中包含超过40万个问题的大规模多跳KGQA。
1、数据01:知识图谱
预训练知识图谱中实体、关系的Embedding
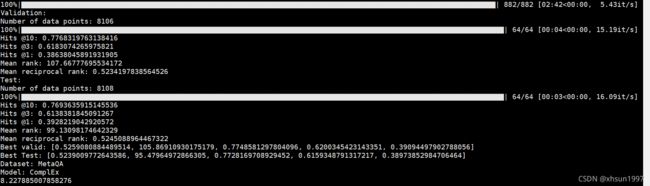
我们需要提供的KG,因为我们要预先训练KG中每一个实体的embedding。KG如下:

比如,用ComplEx这个KGE模型训练MetaQA知识图谱得到的结果:
2、数据02:QA问答对

提供的QA数据就是由(q,a) pairs组成的数据集,每一个(q,a)对中,问题q包含一个实体,由中括号标出。
每一个答案a就是KG中的一个实体。
三、EmbedKGQA模型
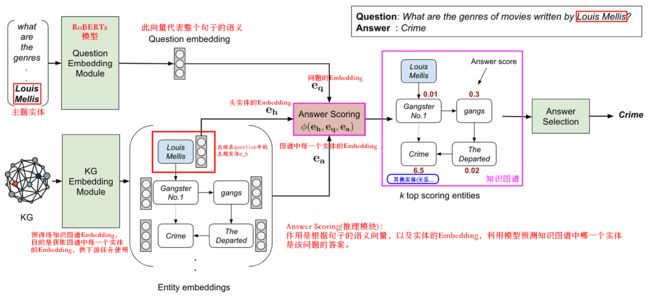
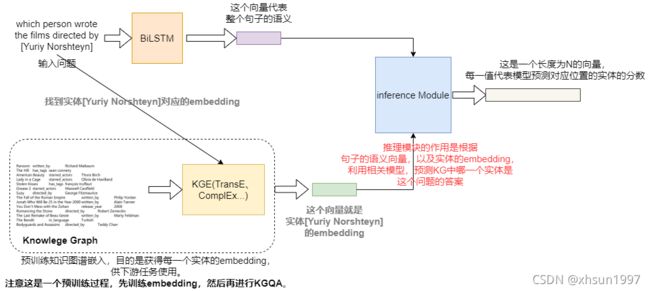
模型流程:
- 首先利用相关的KGE模型预训练,获得每一个实体的embedding,记为entity_embed_matrix
- 对于QA数据集中的每一个样本,取出question中的实体名词,从entity_embed_matrix中找到这个实体名词对应的embedding,记为head_embed
- 将question中的实体名词用统一字符NE替代,然后将question输入到BiLSTM中,取前向的最后一个时刻与反向的第一个时刻的hidden state的结合作为整个句子语义的embedding,记为question_embed
- 然后将head_embed与question_embed输入到ComplEx模型中(目的是推理),得到一个长度为N的向量,记为predict,这个N代表所有实体的数量,比如实验提供的KG数据集中数量是43234
- predict中每一个数值代表模型预测对应实体的分数,比如predict中第二个数字是0.0045,那么代表模型预测当前question对应的答案是KG中第二个实体的分数是0.0045
测试指标可以用准确率衡量,也就是模型预测的predict中,分数最高的那个位置对应的实体是否是真正的answer。
1、KG Embedding模块(为KG中的所有实体、关系创建Embedding)
为知识图谱中所有的实体和关系训练ComplEx Embedding,根据QA训练集中KG实体的覆盖范围,此处学习的实体Embedding将保持frozen状态或可以在后续步骤中进行fine-tune。
2、问题Embedding模块(得到问题的Embedding)
该模块使用RoBERTa将自然语言问题q嵌入到768维向量。
给定:
- 一个问题 q q q;
- 主题实体 h ∈ E h∈E h∈E;
- 答案实体 a ⊆ E a⊆E a⊆E;
它以以下方式学习问题嵌入:
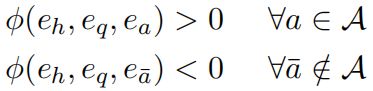
其中:
- ϕ \phi ϕ 是ComplEx模型的scoring function;
- e a e_a ea、 e a ˉ e_{\bar{a}} eaˉ 是ComplEx模型学习到的知识图谱中实体的Embedding;
对于每个问题,将使用所有候选答案实体 a ′ ∈ E a'∈E a′∈E 计算分数 ϕ ( . ) \phi(.) ϕ(.)。通过最小化分数sigmoid与目标标签之间的二进制交叉熵loss来学习模型,其中正确答案标签为1,否则为0。
当实体总数很大时,将进行标签平滑。
3、答案选择模块(减少候选答案实体的集合并选择最终的答案)
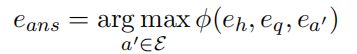
在推断阶段,本模型针对所有可能的答案 a ′ ∈ E a'∈E a′∈E 上进行(head,question)对的评分。对于相对较小的KG(例如MetaQA),我们只需选择得分最高的实体。如果KG很大,则修剪候选实体可以显着改善EmbedKGQA的性能。
如何修剪候选实体的具体方法就是关系匹配。学习得分函数 $S(r,q),对给定问题 q q q 的每个关系 r ∈ R r∈R r∈R 进行排名,如公式3所示:
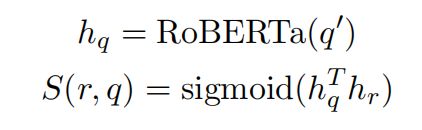
其中 h q h_q hq, h r h_r hr 是问题和关系的embedding,在所有关系中,选择得分大于0.5的那些关系,将其表示为集合 R a R_a Ra。对于到目前为止我们已经获得的每个候选实体 a ′ a' a′,我们在头实体h和 a ′ a' a′ 之间的最短路径中找到关系。将每个候选答案实体的关系得分定义为它们的交集大小。
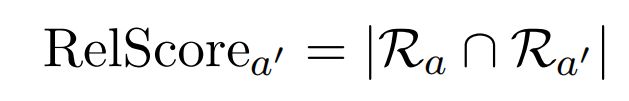
最终模型使用关系得分和ComplEx得分的线性组合来找到答案实体。
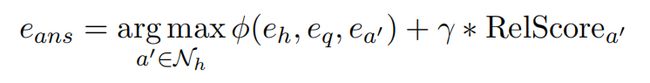
四、实验
本工作在两个数据集上面进行了实验,一个是电影领域中包含超过40万个问题的大规模多跳KGQA数据集MetaQA, 另一个是基于Freebase的多条问答数据集WebQuestionsSP。
下面两个表展示了本工作在这两个数据集上的效果,完整的KG是测试QA模型最简单的设置,因为创建数据集的方式是答案始终存在于KG中,并且路径中没有丢失的链接。但是,这不是一个现实的设置,因此QA模型应该也可以在不完整的KG上工作。因此,本工作通过随机删除KB中的三元组的一半来模拟不完整的KB,表中KG-50表示删除了一半三元组后的KG。
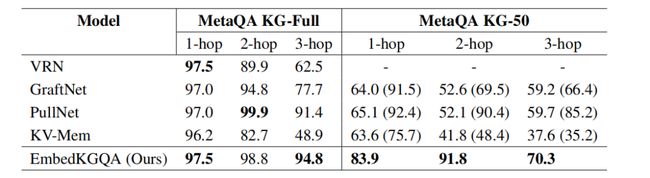
1、MetaQA
如表1所示(MetaQA上多条问答的hits@1结果),EmbedKGQA在多跳情况下以及在缺失KG的情况下可以超过STOA。
2.WebQuestionsSP
WebQuestionsSP使用了更少的训练样本和更大的KG,这使得多跳KGQA要困难得多。如表2所示,在50%KG的情况下,WebQSP可以超过STOA,包括使用了额外的文本信息的PullNet。这可以归因于这样的事实,即通过KG Embedding隐式捕获了相关且必要的信息。
五、总结
本工作通过在KG Embedding的链接预测属性来缓解KG不完整性问题,可以在KG缺失的情况下很好的完成多跳的问答而无需使用任何其他数据。它训练KG实体embedding并使用它来学习问题embedding,并在评估过程中,对所有实体(head实体,问题)再次进行评分,并选择得分最高的实体作为答案。最终在MetaQA和WebQuestionsSP数据集上获得了优秀的表现,特别是的在KG缺失的时候可以非常好的回答问题。
参考资料:
EmbedKGQA论文简要解读
论文浅尝 - ACL2020 | 利用知识库嵌入改进多跳 KGQA
中科大王杰教授:基于表示学习的知识图谱推理技术
小样本场景下的多跳推理及其可解释性(MetaKGR、DacKGR、BIMR)
论文学习笔记:使用知识库嵌入改进知识图谱上的多跳问答