PyTorch深度学习中卷积神经网络(CNN)的讲解及图像处理实战(超详细 附源码)
需要源码和图片集请点赞关注收藏后评论区留言私信~~~
一、卷积神经网络简介
卷积神经网络是深度学习中最常用的一种网络结构,它作为一种深度神经网络结构,擅长处理图像相关的问题,能够将目标图像降维并提取特征,以进行分类识别等运算
二、卷积神经网络核心思想
1:局部感知
图像的局部像素之间往往存在着较强的相关性,局部感知正是利用了这一特性,每次只针对图像的局部信息进行感知,得到特征图,而后在更深层次的网络中继续对所得特征图的局部信息进行高维感知,以此从局部到整体来获取图像信息,使用局部感知时,神经元只和下一层的部分神经元进行连接,每一个局部感知区域都对应着一个卷积核,此外剧本感知大大降低了网络的参数。
2:权值共享
类似于局部感知,同样从像素相关性和参数缩减方面进行考虑。它实现的是多层像素共享一个卷积核的功能,之所以可以这样处理图像,是因为像素相关性高的局部区域往往具有相同的纹理特征,可以用同一个卷积核来学习这部分特征
3:下采样
在实际工作中,通常需要下采样技术对各层特征图进行压缩处理,减少后续网络的权重参数,减少过拟合问题,便于提起图像的高维特征
三、卷积神经网络结构
1:输入层
2:卷积层
基于图像的空间局部相关性分别抽取图像局部特征,通过将这些局部特征进行连接,形成整体特征
单通道与多通道卷积层示意图如下
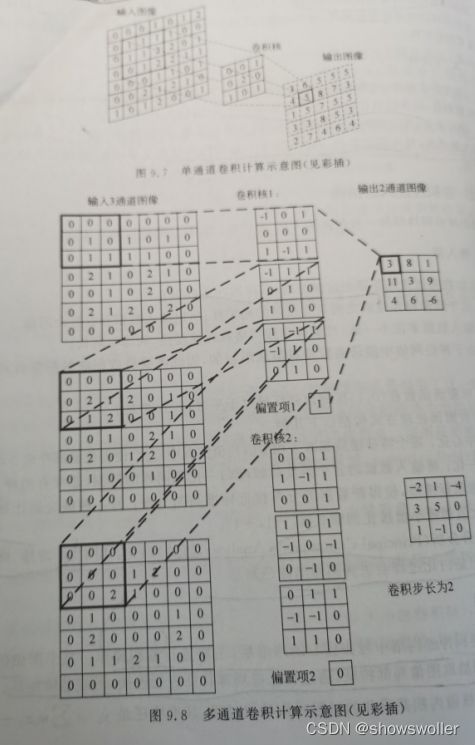
3:激励层
用于将卷积层的输出结果进行非线性映射
4:池化层
其功能在于降低数据量,减少参数数量,从而预防网络过拟合。分为最大池化与平均池化
5:全连接层
与传统神经网络相同,使用一个或多个神经元来输出预测数据
四、CNN处理图像实战
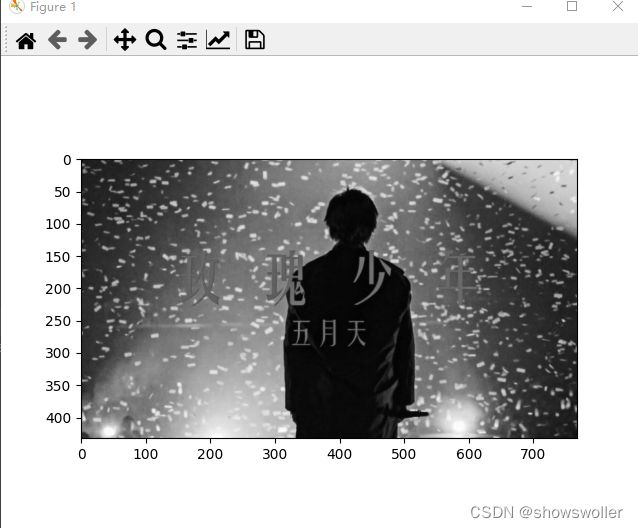
原图片如下

转换为灰度图效果如下 转换时只需要在imshow中指定输出的颜色格式即可变换
将图像背景转换为蓝色

转换为黄色

BrBG颜色效果如下

五、代码
部分源码如下
import numpy as np
import torch
from torch import nn
from torch.autograd import Variable
import torch.nn.functional as F
from PIL import Image
import matplotlib.pyplot as plt
import pylab
############################################get_ipython().run_line_magic('matplotlib', 'inline')
im = Image.open(r'C:\Users.jpg').convert('L') # 读入一张灰度图的图片
im = np.array(im, dtype='float32') # 将其转换为一个矩阵
am = np.array([[1,2,3],[4,5,6],[7,8,9]])
print(im)
print(am)
# 可视化图片
plt.imshow(im.astype('uint8'), cmap='gray')
pylab.show()
# 将图片矩阵转化为 pytorch tensor,并适配卷积输入的要求
print(am.shape)
im = torch.from_numpy(im.reshape((1, 1, im.shape[0], im.shape[1])))
am = torch.from_numpy(am.reshape((1, 1, am.shape[0], am.shape[1])))
print(im)
print(am)
# 使用 nn.Conv2d
conv1 = nn.Conv2d(1, 1, 3, bias=False) # 输入通道数,输出通道数,核大小,定义卷积
sobel_kernel = np.array([[-1, -1, -1], [-1, 8, -1], [-1, -1, -1]], dtype='float32') # 定义轮廓检测算子
sobel_kernel = sobel_kernel.reshape((1, 1, 3, 3)) # 适配卷积的输入输出
conv1.weight.data = torch.from_numpy(sobel_kernel) # 给卷积的 kernel 赋值
edge1 = conv1(Variable(im)) # 作用在图片上
#edge2 = conv1(Variable(am))
edge1 = edge1.data.squeeze().numpy() # 将输出转换为图片的格式
#edge2 = edge2.data.squeeze().numpy()
plt.imsh
# 使用 F.conv2d
sobel_kernel = np.array([[-1, -1, -1], [-1, 8, -1], [-1, -1, -1]], dtype='float32') # 定义轮廓检测算子
sobel_kernel = sobel_kernel.reshape((1, 1, 3, 3)) # 适配卷积的输入输出
weight = Variable(torch.from_numpy(sobel_kernel))
edge2 = F.conv2d(Variable(im), weight) # 作用在图片上
edge2 = edge2.data.squeeze().numpy() # 将输出转换为图片的格式
pw()
# 使用 nn.MaxPool2d
pool1 = nn.MaxPool2d(2, 2)
print('before max pool, image shape: {} x {}'.format(im.shape[2], im.shape[3]))
small_im1 = pool1(Variable(im))
small_im1 = small_im1.data.squeeze().numpy()
print('after max pool, image shape: {} x {} '.format(small_im1.shape[0], small_im1.shape[1]))
pl)
# F.max_pool2d
print('before max pool, image shape: {} x {}'.format(im.shape[2], im.shape[3]))
small_im2 = F.max_pool2d(Variable(im), 2, 2)
small_im2 = small_im2.data.squeeze().numpy()
print('after max pool, image shape: {} x {} '.format(small_im1.shape[0], small_im1.shape[1]))
ow()
#输入数据
cs = np.array([[0,0,0,1,0,1,2],[0,1,1,1,1,0,0],[0,1,1,2,2,0,1],[0,0,1,2,2,1,1],[0,0,0,1,1,0,1],[0,0,2,1,2,1,0],[1,0,1,2,0,0,1]],dtype='float32')
cs = torch.from_numpy(cs.reshape((1, 1, cs.shape[0], cs.shape[1])))
conv1 = nn.Conv2d(1, 1, 3, bias=False)
# 定义卷积核
0,0,0,0]],[[0,0,0,0,0,0,0],[0,2,1,2,0,1,0],[0,1,2,0,0,1,0],[0,0,1,0,2,1,0],[0,2,0,1,2,0,0],[0,1,0,0,1,0,0],[0,0,0,0,0,0,0]],[[0,0,0,0,0,0,0],[0,0,0,1,2,0,0],[0,0,2,1,0,0,0],[0,1,0,0,0,1,0],[0,2,0,0,0,2,0],[0,1,1,2,1,0,0],[0,0,0,0,0,0,0]]],dtype='float32')
cs = torch.from_numpy(cs.reshape(1,cs.shape[0],cs.shape[1],cs.shape[2]))
conv2 = nn.Conv2d( in_channels=3, out_channels=2, kernel_size=3, stride=2, padding=0,bias=True)
# 定义卷积核
conv2_kernel = np.array([[[[-1, 0, 1], [0, 0, 0], [1, -1, 1]],[[-1,1,1],[0,1,0],[1,0,0]],[[1,-1,1],[-1,1,0],[0,1,0]]],[[[0, 0, 1], [1, -1, 1], [0, 0, 1]],[[1,0,1],[-1,0,-1],[0,-1,0]],[[0,1,1],[-1,-1,0],[1,1,0]]]], dtype='float32')
# 适配卷积的输入输出
conv2_kernel = conv2_kernel.reshape((2, 3, 3, 3))
pylab.show()
# 定义偏置项
'''
conv2_bias = np.array([1,0])
conv2.weight.data = torch.from_numpy(conv2_kernel)
conv2.bias.data = torch.from_numpy(conv2_bias)
final2 = conv2(Variable(cs))
print(final2)
'''
创作不易 觉得有帮助请点赞关注收藏~~~