DeepLab V2 论文笔记
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
Deeplab v2
论文链接: https://arxiv.org/abs/1606.00915
一、 Problem Statement
图像语义分割有三个挑战:
- 下降的分辨率
- 目标的多尺度
- localization的精度
对Deeplab V1 进行改进。
- 把VGG-16改为ResNet。
- 添加了ASPP。
二、 Direction
- 空洞卷积, atrous convolution
- ASPP, atrous spatial pyramid pooling
- 全连接条件随机场,Fully-Connected Conditional Random Field(CRF)
三、 Method
1. 空洞卷积
重复堆叠max-pooling和striding会减少feature map的分辨率,位置信息难以恢复。作者使用atrous convolution来解决这个问题。空洞卷积可以在任何一层计算我们想要得到的分辨率大小。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gQ7bTSea-1628837840666)(image6.png)]
可以看到,上图的输入一个一维信号 x [ i ] x[i] x[i],输入一个一维信号 y [ i ] y[i] y[i],filter为 w [ k ] w[k] w[k],得出:
y [ i ] = ∑ k = 1 K x [ i + r ⋅ k ] w [ k ] y[i] = \sum_{k=1}^Kx[i+r\cdot k]w[k] y[i]=k=1∑Kx[i+r⋅k]w[k]
这里的 r r r就是rate,对应于stirde,标准的卷积就是 r = 1 r=1 r=1。
假设是个二维输入信号,输入一张图片

atrous 卷积有两种实现方式:
- 上采样卷积核,参数之间插入 r − 1 r-1 r−1个0。例如 K K K大小的卷积核上采样之后大小为: k + ( k − 1 ) ( r − 1 ) k+(k-1)(r-1) k+(k−1)(r−1)
- 下采样输入特征图,隔行去采样产生 r 2 r^2 r2个子特征图,然后正常卷积,最后插值返回输入大小的分辨率。
2. Atrous Spatial Pyramid Pooling(ASPP)
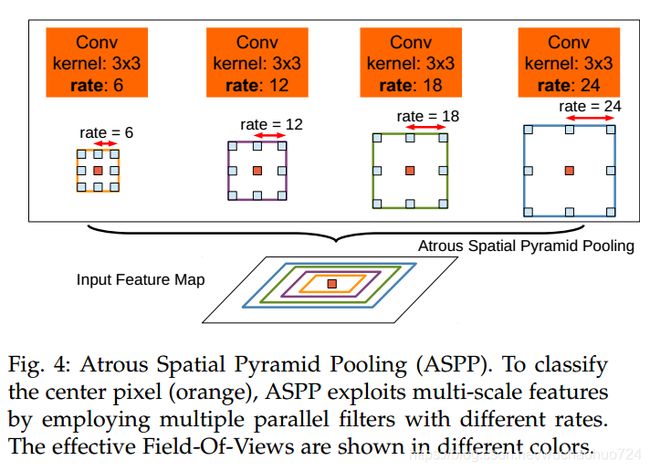
受到SPP的启发,作者使用了不同sampling rates的atrous convolution。具体结构如上。
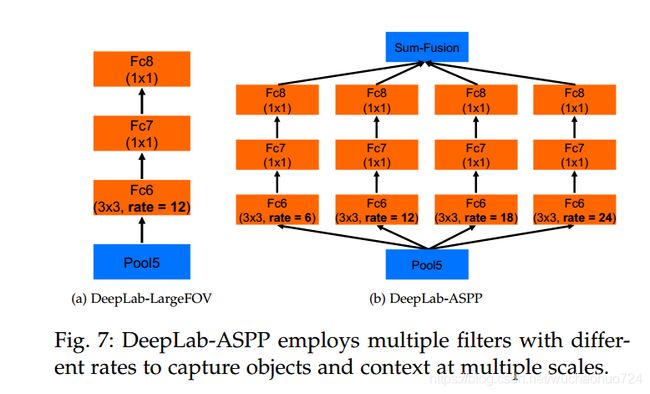
结合到网络中的具体操作如上图所示。
3. Boundary Recovery: Fully-Connected CRF
和deeplab v1是一样的。
传统的条件随机场是用来对segmentation maps进行噪声平滑处理的。比如short-range CRF, 它只考虑到目标像素点的附近点。我们的目标是恢复局部的细节而不是进一步平滑处理。因此,提出了Fully-Connected CRF。
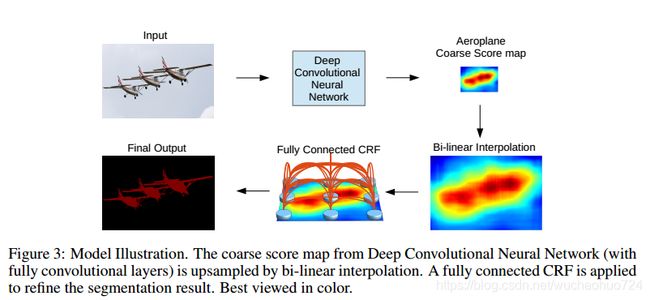
它的energy function是:
E ( x ) = ∑ i θ i ( x i ) + ∑ i j θ i j ( x i , x j ) E(x) = \sum_{i} \theta_i(x_i) + \sum_{ij}\theta_{ij}(x_i, x_j) E(x)=i∑θi(xi)+ij∑θij(xi,xj)
其中 x x x是pixel的label。先看第一项,unary potential:
θ i ( x i ) = − l o g P ( x i ) \theta_i(x_i) = -logP(x_i) θi(xi)=−logP(xi)
也就是说, P ( x i ) P(x_i) P(xi)越大,这个值越小。保证了分类的准确率。
再看第二项, pairwise potential:
θ i j ( x i , x j ) = μ ( x i , x j ) ∑ m = 1 K w m ⋅ k m ( f i , f j ) \theta_{ij}(x_i, x_j) = \mu(x_i, x_j)\sum_{m=1}^K w_m \cdot k^m(f_i, f_j) θij(xi,xj)=μ(xi,xj)m=1∑Kwm⋅km(fi,fj)
其中,
μ ( x i , x j ) = { 1 , if x i ≠ x j 0 , otherwise \mu(x_i, x_j) = \biggl \{ \begin{aligned} &1, \text{if} \quad x_i \neq x_j \\ &0, \text{otherwise} \end{aligned} μ(xi,xj)={1,ifxi=xj0,otherwise
也就是说,只考虑标签不同的两个像素点,且因为是全连接,所以这两个点是模型中的任意两点。 w m w_m wm是权重, k m ( f i , f j ) k^m(f_i,f_j) km(fi,fj)是高斯核函数:
w 1 exp ( − ∣ ∣ p i − p j ∣ ∣ 2 2 σ α 2 − ∣ ∣ I i − I j ∣ ∣ 2 2 σ β 2 ) + w 2 exp ( − ∣ ∣ p i − p j ∣ ∣ 2 2 σ γ 2 ) w_1 \exp(-\frac{||p_i-p_j||^2}{2\sigma^2_{\alpha}}-\frac{||I_i-I_j||^2}{2\sigma^2_{\beta}}) + w_2\exp(-\frac{||p_i-p_j||^2}{2\sigma^2_{\gamma}}) w1exp(−2σα2∣∣pi−pj∣∣2−2σβ2∣∣Ii−Ij∣∣2)+w2exp(−2σγ2∣∣pi−pj∣∣2)
第一个核取决于pixel的positions和color intensities,第二个核只取决于position。
四、 Conclusion
我们提出的模型无法捕捉物体的微妙边界,例如自行车和椅子。由于unary term不够可靠,CRF后处理甚至无法恢复细节。我们假设encoder-decoder结构可以通过利用解码器路径中的高分辨率特征映射来缓解该问题。如何有效地结合该方法是一项未来的工作。
Reference
- https://www.jianshu.com/p/2391704f0f81