DeepLab V3 论文笔记
Rethinking Atrous Convolution for Semantic Image Segmentation
Deeplab v3
论文链接: https://arxiv.org/abs/1706.05587
一、 Problem Statement
图像语义分割有三个挑战:
- 下降的分辨率
- 目标的多尺度
- localization的精度
对Deeplab V2进行改进。
- 提出了cascade和paralle的多尺度特征提取方法
- 消除了条件随机场CRF
二、 Direction
- Cascade multi-scale feature extraction
- Paralle multi-scale feature extraction
三、 Method
作者认为,有以下几种结构来提取多尺度的特征:
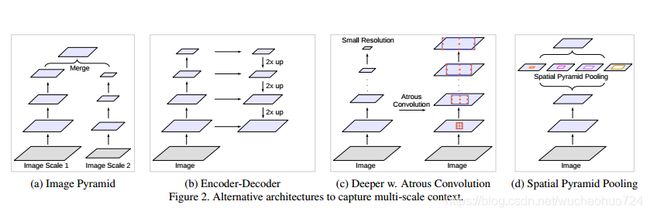
第三种是DeepLab v1的结构,第四种是DeepLab v2的结构。作者分别对这两种结构进行改进。
1. Cascade: Going Deeper with Atrous Convolution
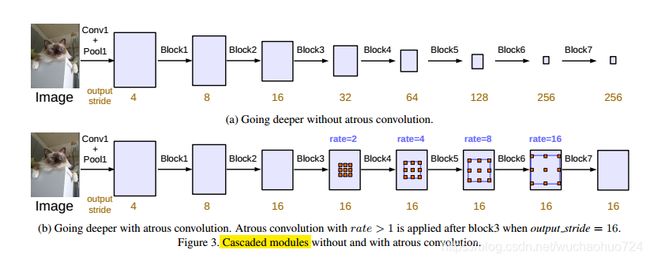
上图的第一排是ResNet为基础,其本身含有四个block。作者简单地把最后一个ResNet block复制,且它们每个block的striding都是2,除了最后一个。也因此,整个图像特征最后汇聚成最后那个很小分辨率的特征图。但是,这样逐步降低分辨率是有害于语义分割的。所以作者提出了使用atrous convolution来达到想要的分辨率,如上图的(b)所示。
具体的方法就是从block 4开始,使用不同比例的空洞卷积。采用Multi-grid方法来控制rate的大小。例如,对每个block里面的三个卷积层定义各自的rate,
Multi-grid = ( r 1 , r 2 , r 3 ) \text{Multi-grid} = (r_1, r_2, r_3) Multi-grid=(r1,r2,r3)
最后空洞卷积的rate就是unit rate和相对应rate的乘积。举个例子,对于 block 4:
output-stride = 16 , Multi-grid = ( 1 , 2 , 4 ) \text{output-stride} = 16, \quad \text{Multi-grid} = (1, 2, 4) output-stride=16,Multi-grid=(1,2,4)
则block 4中的三个空洞卷积层所使用的膨胀rate分别为:
rates = 2 ⋅ ( 1 , 2 , 4 ) = ( 2 , 4 , 8 ) \text{rates} = 2 \cdot (1, 2, 4)= (2, 4, 8) rates=2⋅(1,2,4)=(2,4,8)
经过实验,作者得出 Multi-grid = ( 1 , 2 , 1 ) \text{Multi-grid} =(1, 2, 1) Multi-grid=(1,2,1)是最优参数。
2. Paralle: Atrous Spatial Pyramid Pooling(ASPP)
作者通过实验发现,膨胀率越大,卷积核中的有效权重越少,当膨胀率足够大时,只有卷积核最中间的权重有效,即退化成了1x1卷积核,并不能获取到全局的context信息。

为了解决这个问题,作者在最后一个特征上使用了全局平均池化(global everage pooling),然后输入到256个通道的1x1卷积(with batch normalization),最后通过bilinear上采样还原到对应尺度。
如上图所示,改进的ASPP包含两个部分:
- Image Pooling
- Atrous Spatial Pyramid Pooling
最后所有的branch都会输出一个256通道的结果,进行concate之后,使用一个1x1的卷积进行平滑融合。
3. 经验tricks
这一部分的总结来自于这篇博客:
- 如何在MS COCO上预训练?
从trainval_minus_minival挑选包含PASCAL分类并且目标区域像素个数大于1000的图片,大概有60k的图片用于训练,除了PASCAL分类区域,其它都看成背景。从上述实验结果中发现提升了3个百分点。 - 对于有些类准确率比较低,怎么办?
针对包含namely bicycle、chair、table、potted- plant、and sofa分类的图片,在训练集中增加它们比列。通过BN策略和这里的策略,达到85.7%IOU,再次提升3个百分点。 - Cityscapes上的小策略:
cropsize 769 iters 90k
output stride = 16时:77.23%
output stride = 8时:77.82%
多尺度输入(0.75,1,1.25):79.30%
事先在trainval coarse上预训练,scales = {0.75, 1, 1.25, 1.5, 1.75, 2} ,output stride = 4,output stride = 8,最终结果:81.3%
四、 Conclusion
Cascade 和 Paralle的性能很接近,前者最优达到了79.35%的mIOU,后者达到了79.77%的mIOU,都超过了DeepLab v2,且这一版本没有使用CRF。
Reference
- https://www.jianshu.com/p/edbaa56d250d