时间序列预测的七种方法-python复现
前提:数据集为JetRail高铁的乘客数量,网上搜一下可以找到。数据集共18288行有效数据,第一列对应 ID ;第二列为Datatime,格式为日-月-年+时间,时间间隔为一小时;第三列为Count,表示该时段内乘客数量。
目录
-
-
-
- 测试数据是否正确读入
- 数据可视化
- (一)朴素法
- (二)简单平均法
- (三)移动平均法
- (四)简单指数平滑法(SES)
- (五)霍尔特(Holt)线性趋势法
- (六)Holt-Winters季节性预测模型
- (七)自回归移动平均模型(ARIMA)
- 总结
-
-
测试数据是否正确读入
import pandas as pd #pands别名pd
df = pd.read_csv('train.csv') #读取csv文件
print(df.head(5)) #读取前5行数据
数据可视化
x x x轴表示时间, y y y轴表示乘客数量。

将数据拆分成两部分,[1,14]作为训练集,[15,16]作为测试集,测试集将与预测集进行均方根误差计算,检查预测的准确率。误差值越小,说明预测越准确。
df['Timestamp']=pd.to_datetime(df['Datetime'],format="%d-%m-%Y %H:%M")
代码解释:
arg–df['Datetime'],表示要转换为日期时间的对象
format,str,改变格式,解析时间的strftime
其它参数未用到,想了解可以查看pd.to_datetime()官方文档
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df=pd.read_csv('train.csv',nrows=11856)
train=df[0:10392]#训练集
test=df[10392:]#测试集
df['Timestamp']=pd.to_datetime(df['Datetime'],format="%d-%m-%Y %H:%M")
df.index=df['Timestamp'] #在train文档中新增加一列Timestamp
df=df.resample('D').mean() #按天采样,计算均值
train['Timestamp']=pd.to_datetime(train['Datetime'],format="%d-%m-%Y %H:%M")
train.index=train['Timestamp']
train=train.resample('D').mean()
test['Timestamp']=pd.to_datetime(test['Datetime'],format="%d-%m-%Y %H:%M")
test.index=test['Timestamp']
test=test.resample('D').mean()
#数据可视化
train.Count.plot(figsize=(15,7),title='Daily xxx',fontsize=14)
test.Count.plot(figsize=(15,7),title='Daily xxx',fontsize=14)
plt.show()
(一)朴素法
应用情境:稳定性高的数据集。
应用方法:以最后一个训练点为预测值的一条水平直线。
该数据集的均方根误差RMS为43.91640614391676。

plt.plot()函数说明
plt.plot(x, y, 'bs', label='xxx')
横轴为 x x x轴,纵轴为 y y y轴。 b s bs bs表示蓝色方块点。 l a b e l label label表示标题。
公式为: y t + 1 ^ = y t \hat{y_{t+1}} = y_t yt+1^=yt
该代码需要连接上方数据预处理(拆分,改变格式)代码才能正常运行。
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
from math import sqrt
#
dd=np.asarray(train['Count']) #将train中的Count列转化为array(数组)形式
y_hat=test.copy()
y_hat['naive']=dd[len(dd)-1] #预测数据均为test的最后一个数值
plt.figure(figsize=(12,8))
plt.plot(train.index,train['Count'],label='Train')
plt.plot(test.index,test['Count'],label='Test')
plt.plot(y_hat.index,y_hat['naive'],label='Naive Forecast')
plt.legend(loc='best')
plt.title("Naive Forecast")
plt.show()
#均方根误差计算
rms = sqrt(mean_squared_error(test['Count'], y_hat['naive']))
print(rms)
(二)简单平均法
应用情境:每个时间段内的平均值基本保持不变的数据集。
应用方法:预测的价格和过去天(已知数据的)平均值的价格一致。
该数据集的均方根误差RMS为109.88526527082863。

公式为: y ^ x + 1 = 1 x ∑ i = 1 x y i \hat{y}_{x+1} = \frac{1}{x}\sum_{i=1}^{x}y_{i} y^x+1=x1i=1∑xyi
该代码需要连接上方数据预处理(拆分,改变格式)代码才能正常运行。
y_hat_avg=test.copy()
y_hat_avg['avg_forecast']=train['Count'].mean() #取train中Count列的平均值
plt.figure(figsize=(12,8))
plt.plot(train['Count'],label='Train')
plt.plot(test['Count'],label='Test')
plt.plot(y_hat_avg['avg_forecast'],label='Average Forecast')
plt.legend(loc='best') #对性能图做出一些补充说明的问题
plt.show()
rms = sqrt(mean_squared_error(test['Count'], y_hat_avg['avg_forecast']))
print(rms)
(三)移动平均法
应用情境:最后一个时间段内的平均值基本保持不变(平稳)的数据集。
应用方法:预测的价格和最近时期的平均值的价格一致。
该数据集的均方根误差RMS为46.72840725106963。

因为取最近时期的平均值,我们必须知道最近的时期是多少天(多长),引入滑动窗口的概念,我们规定最近时期长度为 p p p ,对于所有的 i > p i>p i>p: y ^ l = 1 p ( y i − 1 + y i − 2 + y i − 3 + … + y i − p ) \hat{y}_{l} = \frac{1}{p}(y_{i-1}+y_{i-2}+y_{i-3}+…+y_{i-p}) y^l=p1(yi−1+yi−2+yi−3+…+yi−p)
图示滑动窗口概念理解:

该代码需要连接上方数据预处理(拆分,改变格式)代码才能正常运行。
y_hat_avg = test.copy()
y_hat_avg['moving_avg_forecast']=train['Count'].rolling(60).mean().iloc[-1] #以p=60计算滚动平均值
plt.figure(figsize=(16,8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['moving_avg_forecast'], label='Moving Average Forecast')
plt.legend(loc='best')
plt.show()
rms = sqrt(mean_squared_error(test['Count'], y_hat_avg['moving_avg_forecast']))
print(rms)
(四)简单指数平滑法(SES)
应用情境:没有明显趋势或季节规律的预测数据。简单平均法和加权移动平均法的折中方法。
应用方法:预测的价值为每个时间段乘以该时间段的权重和,越接近当下(预测)的时间段赋予的权重越大。
该数据集的均方根误差RMS为43.357625225228155,α=0.6。(最终均方根误差可根据α的调节而降低)
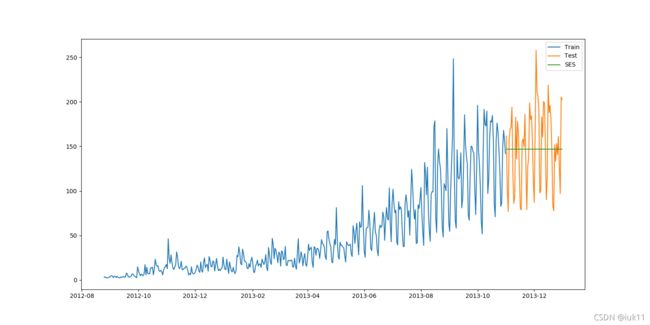
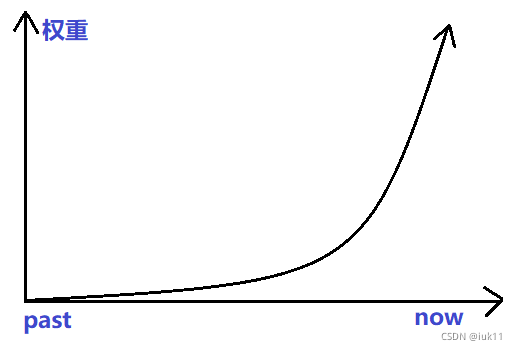
权重的赋予方式:从早到晚的每个时间段值的权重参数呈指数级下降。 y ^ T + 1 ∣ T = α y T + α ( 1 − α ) y T − 1 + α ( 1 − α ) 2 y T − 2 + … \hat{y}_{T+1|T}=\alpha y_T+\alpha(1-\alpha)y_{T-1}+\alpha(1-\alpha)^{2}y_{T-2}+… y^T+1∣T=αyT+α(1−α)yT−1+α(1−α)2yT−2+…其中 0≤α≤1 为平滑参数; y T + 1 y_{T+1} yT+1是 y 1 y_1 y1~ y t y_t yt的值的加权平均值;预测值 y ^ x \hat{y}_x y^x为 α ⋅ y t \alpha \cdot y_t α⋅yt与 ( 1 − α ) ⋅ y ^ x (1-\alpha) \cdot \hat{y}_x (1−α)⋅y^x的和。即上述公式也可以写成: y ^ t + 1 ∣ t = α y t + ( 1 − α ) y ^ t − 1 ∣ t \hat{y}_{t+1|t}=\alpha y_t+(1-\alpha)\hat{y}_{t-1|t} y^t+1∣t=αyt+(1−α)y^t−1∣t
Statsmodel模型介绍
SimpleExpSmoothing(data).fit(smoothing_level=0.2,optimized=False)
smoothing_level为平滑参数 α∈[0,1]
optimized为是(默认)否(False)开启自动优化,为我们找到优化值
该代码需要连接上方数据预处理(拆分,改变格式)代码才能正常运行。
from statsmodels.tsa.api import SimpleExpSmoothing
y_hat_avg=test.copy()
fit=SimpleExpSmoothing(np.asarray(train['Count'])).fit(smoothing_level=0.6,optimized=False)
y_hat_avg['SES']=fit.forecast(len(test)) #根据平滑参数预测fit中的值
plt.figure(figsize=(16,8))
plt.plot(train['Count'],label='Train')
plt.plot(test['Count'],label='Test')
plt.plot(y_hat_avg['SES'],label='SES')
plt.legend(loc='best')
plt.show()
rms = sqrt(mean_squared_error(test['Count'], y_hat_avg['SES']))
print(rms)
(五)霍尔特(Holt)线性趋势法
又称二次指数平滑。
应用情境:任何呈现某种趋势的数据集。
应用方法:Holt扩展了简单指数平滑,Holt包括两个平滑方程(一个用于水平,一个用于趋势)和一个预测方程(由两个平滑方程相加得到)。
该数据集的均方根误差RMS为43.056259611507286,α=0.3,β=0.1。
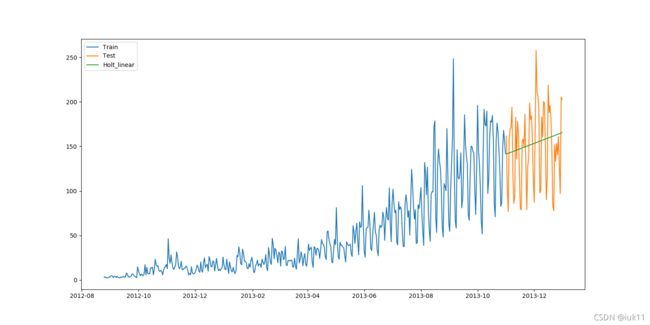
ι t = α y t + ( 1 − α ) ( ι t − 1 + b t − 1 ) \iota _{t}=\alpha y_t+(1-\alpha )(\iota _{t-1}+b_{t-1}) ιt=αyt+(1−α)(ιt−1+bt−1) b t = β ∗ ( ι t − ι t − 1 ) + ( 1 − β ) b t − 1 b_t=\beta *(\iota _t-\iota _{t-1})+(1-\beta )b_{t-1} bt=β∗(ιt−ιt−1)+(1−β)bt−1 [ 线 性 ] y ^ t + h ∣ t = ι t + h b t [线性] \hat{y}_{t+h|t}=\iota _{t} + hb_{t} [线性]y^t+h∣t=ιt+hbt [ 指 数 ] y ^ t + h ∣ t = ι t ∗ h b t [指数]\hat{y}_{t+h|t}=\iota _{t} * hb_{t} [指数]y^t+h∣t=ιt∗hbt
上述方程1为用于水平的平滑方程,与简单指数平滑方程相似,方程显示它是观测值和样本内单步预测值的加权平均数。
上述方程2为用于趋势的平滑方程,方程显示它是根据 l t − l t − 1 l_t-l_{t-1} lt−lt−1 和之前的预测趋势 b t − 1 b_{t-1} bt−1 在时间 t t t 处的预测趋势的加权平均值。
- 趋势成线性上升或下降,采用相加;
- 趋势成指数上升或下降,采用相乘,预测更稳定。
smoothing_slope趋势参数β
该代码需要连接上方数据预处理(拆分,改变格式)代码才能正常运行。
from statsmodels.tsa.api import Holt
y_hat_avg = test.copy()
fit = Holt(np.asarray(train['Count'])).fit(smoothing_level=0.3, smoothing_slope=0.1)
y_hat_avg['Holt_linear'] = fit.forecast(len(test))
plt.figure(figsize=(16, 8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['Holt_linear'], label='Holt_linear')
plt.legend(loc='best')
plt.show()
rms = sqrt(mean_squared_error(test['Count'], y_hat_avg['Holt_linear']))
print(rms)
(六)Holt-Winters季节性预测模型
又称三次指数平滑。
名词解释[季节性]:在一定时间段内的固定区间内呈现相似的模式,周期性。
应用情境:任何呈现某种趋势的具有季节性的数据集。
应用方法:Holt包括两个平滑方程(一个用于水平,一个用于趋势)和一个预测方程(由两个平滑方程相加得到),在Holt的基础上加入一个平滑方程(用于季节)。
该数据集的均方根误差RMS为23.961492566159794,γ=7。

H o l t − W i n t e r s Holt-Winters Holt−Winters 季节性预测模型,水平函数 l t l_t lt,趋势函数 b t b_t bt,季节分量 s t s_t st,平滑参数α,β和γ。 L t = α ( y t − S t − s ) + ( 1 − α ) ( L t − 1 + b t − 1 ) L_t = \alpha (y_t-S_{t-s})+(1-\alpha )(L_{t-1}+b_{t-1}) Lt=α(yt−St−s)+(1−α)(Lt−1+bt−1) b t = β ( L t − L t − 1 ) + ( 1 − β ) b t − 1 b_t = \beta (L_t-L_{t-1})+(1-\beta )b_{t-1} bt=β(Lt−Lt−1)+(1−β)bt−1 S t = γ ( y t − L t ) + ( 1 − γ ) S t − s S_t = \gamma (y_t-L_t)+(1-\gamma )S_{t-s} St=γ(yt−Lt)+(1−γ)St−s F t + k = L t + k b t + S t + k − s F_{t+k} = L_t +kb_t +S_{t+k-s} Ft+k=Lt+kbt+St+k−s季节函数为当前季节指数和去年同一季节的季节性指数之间的加权平均值。
- 当季节变化保持稳定,优先采用相加的方法。
- 当季节性变化幅度与各时间段的水平值成正比,可以优先采用相乘的方法。
seasonal_periods周期(季节)
trend='add'加法趋势
seasonal='mul'乘法季节
该代码需要连接上方数据预处理(拆分,改变格式)代码才能正常运行。
from statsmodels.tsa.api import ExponentialSmoothing
y_hat_avg=test.copy()
fit=ExponentialSmoothing(np.asarray(train['Count']),seasonal_periods=7,trend='add',seasonal='add').fit()
y_hat_avg['Holt_Winter']=fit.forecast(len(test))
plt.figure(figsize=(16,8))
plt.plot(train['Count'],label='Train')
plt.plot(test['Count'],label='Test')
plt.plot(y_hat_avg['Holt_Winter'],label='Holt_Winter')
plt.legend(loc='best')
plt.show()
rms = sqrt(mean_squared_error(test['Count'], y_hat_avg['Holt_Winter']))
print(rms)
(七)自回归移动平均模型(ARIMA)
应用情境:想要描绘数据与数据之间的关系。
该数据集的均方根误差RMS为26.052705330843708。

sm.tsa.statespace.SARIMAX()模型-包含季节性的自回归移动平均模型
order=(p,d,q)
seasonal_order=(p,d,q,s)
order参数指定(p, d, q)参数,而seasonal_order参数指定(P, D, Q, S)季节性 ARIMA 模型的季节性组件。拟合每个SARIMAX()模型后,代码会打印出其各自的AIC分数。
warnings.filterwarnings("ignore") # specify to ignore warning messages
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(y,
order=param,
seasonal_order=param_seasonal,
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit()
print('ARIMA{}x{}12 - AIC:{}'.format(param, param_seasonal, results.aic))
except:
continue
我们代码的输出表明SARIMAX(2, 1, 4)x(0, 1, 1, 7)产生的最小值AIC为 xxx。因此,我们应该认为这是我们考虑过的所有模型中的最佳选择。7表示序列以7天为周期。
dynamic=False该参数确保我们生成提前一步预测,这意味着每个点的预测都是使用到该点的完整历史生成的。(验证预测)
该代码需要连接上方数据预处理(拆分,改变格式)代码才能正常运行。
import statsmodels.api as sm
y_hat_avg=test.copy()
fit=sm.tsa.statespace.SARIMAX(train.Count,order=(2,1,4),seasonal_order=(0,1,1,7)).fit()
y_hat_avg['SARIMA']=fit.predict(start="2013-11-1",end="2013-12-31",dynamic=True)
plt.figure(figsize=(16,8))
plt.plot(train['Count'],label='Train')
plt.plot(test['Count'],label='Test')
plt.plot(y_hat_avg['SARIMA'],label='SARIMA')
plt.legend(loc='best')
plt.show()
rms = sqrt(mean_squared_error(test['Count'], y_hat_avg['SARIMA']))
print(rms)
总结
在解决问题时,可以面向数据集选择合适的模型,在当前数据集中采用 Holt-Winters模型 预测效果最好,但每个数据集都有适合自己的模型,观察Train文档数据走向,判断水平,趋势,季节性,从而选择最适合的模型。若拿不准,也可以将模型均尝试一下,通过均方根误差值(越趋近0准确度越高)来选择最合适的模型。
参考文献1
参考文献2
ARIMA文档