深度学习推荐系统之“输入”特征工程
1. 前言
从计算机视觉转换赛道到推荐系统,最令我迷惑的不是具体的网络模型,而是大多数论文中往往一笔带过的“输入层”。就像一个厨师,知道菜谱,但是不会处理食材。最近一段时间通过查阅资料文献,加上个人一些小小见解,撰成此文,希望借此加深自己的理解,同时也希望给有着像我一样困惑的同学带来帮助。
图像作为一种低阶信息,其RGB矩阵(或其他形式的数字化表达)即可直接输入到神经网络之中,而文本信息(推荐系统的ID类特征也可看作一类文本信息)与图像不同,往往具备深层的含义,而且以字符串的形式进行存储,无法直接输入神经网络。因此如何将信息从字符串转换为神经网络可以处理的实数向量(Tensor),是至关重要的一步。
2. 推荐算法的输入与输出
推荐算法的输入往往包括用户特征、物品特征以及上下文特征,根据输入信息,模型得到推荐结果,具体的输出一般是模型预测得到的某一用户对某一物品的“偏好程度”,比如点击率、转化率等。
用户特征一般包括用户性别、年龄、地域、手机型号等基础信息,用户浏览序列、点击序列、浏览时长等行为信息等;物品特征一般包括物品名称、所属类别等信息;上下文特征一般指当前时间、节假日信息、广告位信息等。分析输入的信息可以发现,大多数特征可分为两类,即类别型(也称ID型)和连续型。类别型指的是离散的,某类特征的不同特征值之间不存在数值上的大小关系的特征,比如性别就是典型的类别型特征,其特征值男、女之间不存在数值上的大小关系,再比如用户浏览序列,也是由用户浏览的物品这一类别型特征构成的。连续型特征的特征值往往是可以用实数表示的,比如年龄,30岁和31岁之间存在简单的数值上的关系,再比如浏览时长,同样是该类特征,浏览时长1h和1min,特征数值具有明确的含义。
类别型特征对于推荐算法的效果起着更关键的作用,一方面是因为数量上类别型特征更多,另一方面更是因为像用户行为序列等关键特征往往都是类别型的。值得注意的是,对于连续型特征,往往也可以直接当做类别型特征来处理,即一个取值就作为一个类别来看待,当取值较多时,涉及到的类别可能会很多,处理时需要注意。或者通过分桶等方式进行离散化,例如对于年龄这个特征,可以根据年龄大小,分成老、中、青等几类,而不直接使用具体的年龄数值。
我们重点介绍类别型特征的处理方式,类别型特征在处理前,往往是字符串形式的,如下所示。
“用户名 xxxx|用户ID A0001|性别 男|年龄 35|手机型号 APPLE6S|浏览记录 0001 00123 18930|商品名称 B牌笔记本电脑|商品ID 4567890|商品价格 5000RMB|...”
参照文献[2]的划分,我们可以将特征从字符串转换为实数向量的过程拆分为编码和解码两个阶段。编码阶段指的是将字符串编码为各自对应的向量,该向量往往是稀疏的,并且不随着神经网络优化进行更新。抛开深度推荐算法,不考虑Embedding的话,该阶段产生的稀疏向量已经可以直接输入经典的推荐模型或者一些机器学习模型之中。然而上述稀疏向量存在很多缺点,尤其不适合深度学习模型,因此还需要解码阶段,解码阶段指的是将稀疏向量转换为低维稠密向量(该向量也称为Embedding)的过程,相比于稀疏向量,Embedding具有诸多优点,将在下面进行重点介绍。
3. 编码:One-Hot编码与哈希编码
One-Hot(独热)编码是最基本的编码方式之一,一般某一特征的特征值取值有多少种,就需要多少维的向量来进行编码,例如“性别”可取值“男”或“女”,则需要至少两维。独热编码存在两个明显的缺点,首先,对于用户ID等特征值极多的特征,采用独热编码会产生维度极高的特征向量,由多种特征拼接产生的样本维度就会更大。其次,某一特征的编码维度往往是根据训练数据中该类特征的取值数量确定好的,并记录好了One-Hot对照表,在实际场景中,往往存在新增用户、商品等情况,以及ID化的连续型特征也会不可避免地存在“新值”,固定的One-Hot对照表可能会出现对这些新项目无码可编的问题。
由于One-Hot编码存在上述缺陷,在实际工业界中一般是采用哈希方法对特征进行编码,即固定哈希函数,直接将字符串形式的特征值哈希为一个固定维度的向量。采用这种方式,一方面能够将维度限制在固定大小,另一方面产生任意一个新的特征值时,哈希函数总能够得到其一个对应的编码,同时不需要存储额外的One-Hot对照表,只需存储哈希函数即可。当然哈希方法存在碰撞的问题,因此目标维度也应根据特征值的大致数量进行合理设置,尽量减少碰撞的产生,即使有研究表明,少数的碰撞并不会导致模型性能明显的下降。另外,哈希编码不论是从哈希函数的选择还是哈希结果的选择(One-Hot还是Multi-Hot)均需要考虑和设计,相比于One-Hot直接编码,存在一定的设计难度。
文献[2]中总结指出,一个好的编码方法应尽量满足唯一性(U)、相似性(E-S)、高维性(H-D)、高熵性(H-D)这四点,如下表所示。

编码阶段的产物大多是稀疏向量,稀疏向量无法直接输入神经网络(效果不佳),因为每个特征只能在少数数据点上被激活,无法进行有效的学习。而且即使编码为稠密向量,编码阶段本质上还是对原来特征的一种直接转换,编码后的特征不能体现特征值之间深层的关系,例如“领带”和“西装”,虽然从字面上来看两者没有很强的关系,但是它们之间存在一定的实际关联,即买完西装很可能也会考虑领带,为了实现类似的效果,从特征表达层面就使得特征具备这样的深层关联关系,仅仅依靠不含有任何学习过程的编码阶段是不够的,还需要解码阶段的Embedding技术。而且,随着Embedding技术的发展,编码阶段目前主要是充当为每个特征值标记ID的作用,依靠ID更容易的找到其对应的Embedding向量。
4. 解码:从Word2Vec到万物Embedding
解码阶段肩负的主要任务是通过学习的方式,将编码阶段的向量解码为具备深层联系的向量,除此之外,解码阶段还会完成特征的稠密化和降维,对后续送入深度学习模型更加友好。解码阶段采用的主要是Embedding技术,该技术从Word2Vec发展而来,但是并不局限于Word2Vec的设计范式,结合图神经网络等其他技术方法可以有很多延伸和拓展。
明确解码阶段的目的以及输入输出形式,可以从更高的层次来看待和理解一些具体的算法。
Word2Vec结构如下图所示,可以分别从自监督学习和监督学习角度进行理解。
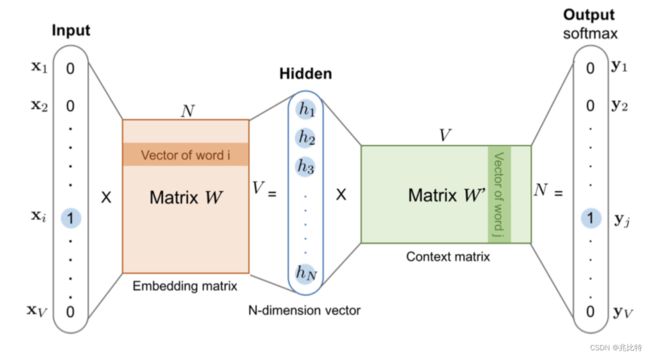
首先从自监督学习的角度来看,本身Word2Vec可以看作是一种通过自监督来生成Embedding的方式,采用的网络结构可以看成是一种Encoder-Decoder结构(这里的Encoder与Decoder不同于本文章全篇的编码和解码)。Word2Vec模型根据训练方式的不同,可以分成CBOW模型和Skip-gram模型,以后者为例,输入模型的为一句话中的一个词的One-Hot向量x,经过Encoder,也就是简单的线性变换W,得到隐层向量h,隐层向量再经过同样是线性变换的Decoder,得到输入词在句子中的相邻词的One-Hot向量y。向量x对应的隐层向量h就是它的Embedding,由于x为One-Hot向量,因此h其实也就是W矩阵中的一个行向量,行号就是x中非零元素的位置序号i。之所以称之为自监督,是因为训练模型的监督信号来自于句子本身,输入一个句子,即可通过滑动窗口的方式构建诸多训练样本对。
如果从监督学习的角度来看训练Embedding的过程,可以总结为两步,一是查表(lookup-table)得到对应特征值的Embedding向量,二是根据一定的监督信息更新Embedding的值。One-Hot加特征线性变换,本质上就是一个查表的过程,即根据特征值得到其对应的Embedding。Embedding未经学习时,是按照随机或者固定值等设定的方式初始化的,为了学习每个特征值的Embedding向量的每个值,需要设计合理的监督信号,朴素的Word2Vec采用的是“一个单词的相邻单词可以由中心单词决定”的先验,其实很多时候采用其他的监督信号或者直接将Embedding输入推荐模型,学习模型参数的同时端到端学习Embedding向量参数也未尝不可。
Embedding技术思想其实与计算机视觉中应用在再识别、人脸识别中的度量学习或者小样本学习中的原型(Prototype)思想异曲同工。Embedding技术本质就是一种将输入信号转换为具备深层信息的稠密(低维)向量的一类方法。因此Embedding不仅仅可以通过简单的查表与原始输入构建一对一联系,也可以像计算机视觉中的图像Embedding一样,通过神经网络生成,这也是KDD2021中的DHE[2]的思路,见下图。

当然查表和通过神经网络生成是各有利弊的,比较突出的就是,查表的方式需要得到和存储具体的Embedding表,从而导致参数量过大(推荐模型参数量大,很多时候是Embedding表导致的,模型逻辑本身参数量并不是特别大),但是牺牲空间,带来的确是时间效率的提升,通过查表的方式直接得到输入向量的Embedding是很快的。而另一种方式,通过神经网络逐层计算,得到输入向量的Embedding向量,虽然仅需存储少量的神经网络参数,但是计算效率却大大下降。而在最终性能上两种方法目前没有显著区别,所以并无绝对的优劣之分。
5. 小结
深度学习推荐算法虽然不像以往的经典方法需要复杂的手工特征工程(只能说在一定程度上,深度学习推荐算法需要的特征工程变少了,或者形式变了,但是其依旧是推荐算法设计的重中之重),但是如何处理字符串形式的输入信息,将其转换为有效的神经网络友好的输入Tensor却是一个重要的课题,解决这一问题目前主要采用的是如火如荼的Embedding技术。Embedding技术本质上与NLP、计算机视觉等领域有很多关联之处,推荐算法中的Embedding技术也有其特点和难点,同时还需要兼具效率等诸多工业实践上的考量。
参考
1. 推荐系统精排之锋(11):再论特征与embedding生成 - 知乎 (zhihu.com):https://zhuanlan.zhihu.com/p/432118382
2. DHE:Learning to Embed Categorical Features without Embedding Tables for Recommendation,KDD,2021:https://arxiv.org/pdf/2010.10784.pdf
3. 无中生有:论推荐算法中的Embedding思想 - 知乎 (zhihu.com):https://zhuanlan.zhihu.com/p/320196402
4. hash trick在机器学习中的使用_juary_的专栏-CSDN博客:https://blog.csdn.net/wm_1991/article/details/50463237
5. 推荐系统的特征工程 - 小小小的程序猿 - 博客园 (cnblogs.com):https://www.cnblogs.com/x739400043/p/12394135.html
6. 求通俗讲解下tensorflow的embedding_lookup接口的意思?- qiao的回答 - 知乎:https://www.zhihu.com/question/48107602/answer/715028211
作者:兆比特,公众号:每日AI,欢迎关注~