Pandas-数据结构-DataFrame(二):设置索引【①创建DataFrame时添加行、列索引;②修改行/列索引值;③重设新下标索引;④以某列值设置为新的索引】
DataFrame索引
- 修改的时候,需要进行全局修改
- 对象.reset_index()
- 对象.set_index(keys)
创建学生成绩表
# 生成10名同学,5门功课的数据
score = np.random.randint(40, 100, (10, 5))
# 结果
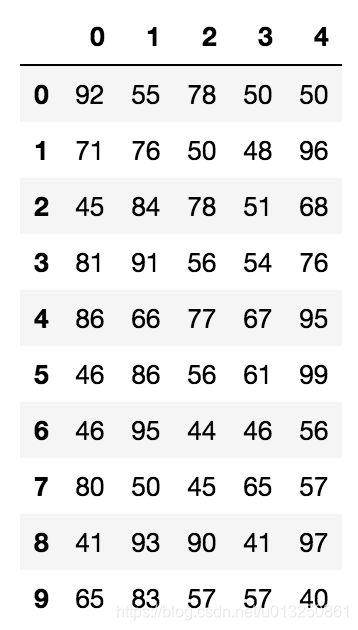
array([[92, 55, 78, 50, 50],
[71, 76, 50, 48, 96],
[45, 84, 78, 51, 68],
[81, 91, 56, 54, 76],
[86, 66, 77, 67, 95],
[46, 86, 56, 61, 99],
[46, 95, 44, 46, 56],
[80, 50, 45, 65, 57],
[41, 93, 90, 41, 97],
[65, 83, 57, 57, 40]])
但是这样的数据形式很难看到存储的是什么的样的数据,可读性比较差!!
问题:如何让数据更有意义的显示?
# 使用Pandas中的数据结构
score_df = pd.DataFrame(score)
给分数数据增加行列索引,显示效果更佳
效果:
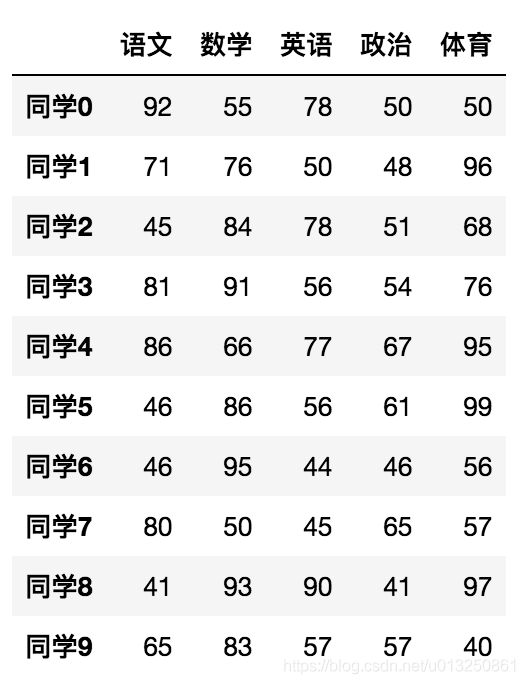
一、创建DataFrame时添加行、列索引
import numpy as np
import pandas as pd
# 生成10名同学,5门功课的数据
score = np.random.randint(40, 100, (10, 5))
print("score = \n", score)
print("-" * 100)
# 构造行索引序列
subjects = ["语文", "数学", "英语", "政治", "体育"]
# 构造列索引序列
stu = ['同学' + str(i) for i in range(score.shape[0])]
# 添加行索引
data = pd.DataFrame(score, columns=subjects, index=stu)
print("data = \n", data)
打印结果:
score =
[[56 73 50 49 77]
[52 61 71 90 67]
[78 90 63 70 50]
[83 42 74 77 71]
[86 63 97 77 72]
[80 40 42 62 75]
[86 95 62 74 89]
[55 97 49 61 78]
[68 45 71 74 66]
[59 49 47 95 68]]
----------------------------------------------------------------------------------------------------
data =
语文 数学 英语 政治 体育
同学0 56 73 50 49 77
同学1 52 61 71 90 67
同学2 78 90 63 70 50
同学3 83 42 74 77 71
同学4 86 63 97 77 72
同学5 80 40 42 62 75
同学6 86 95 62 74 89
同学7 55 97 49 61 78
同学8 68 45 71 74 66
同学9 59 49 47 95 68
Process finished with exit code 0
二、修改行/列索引值
import numpy as np
import pandas as pd
# 生成10名同学,5门功课的数据
score = np.random.randint(40, 100, (10, 5))
print("score = \n", score)
print("-" * 100)
# 构造行索引序列
subjects = ["语文", "数学", "英语", "政治", "体育"]
# 构造列索引序列
student_index = ['同学' + str(i) for i in range(score.shape[0])]
# 添加行索引
data = pd.DataFrame(score, columns=subjects, index=student_index)
print("data = \n", data)
print("-" * 100)
# 修改行/列索引值
subjects_new = ["美术", "数学", "英语", "政治", "体育"]
teacher_index = ["老师_" + str(i) for i in range(score.shape[0])]
data.columns = subjects_new
data.index = teacher_index
print("data = \n", data)
打印结果:
score =
[[74 90 98 59 98]
[88 67 57 42 55]
[98 90 84 47 96]
[62 71 66 42 59]
[92 40 46 84 53]
[66 46 86 79 80]
[93 76 91 66 49]
[93 99 82 88 63]
[45 58 85 49 50]
[60 72 53 76 62]]
----------------------------------------------------------------------------------------------------
data =
语文 数学 英语 政治 体育
同学0 74 90 98 59 98
同学1 88 67 57 42 55
同学2 98 90 84 47 96
同学3 62 71 66 42 59
同学4 92 40 46 84 53
同学5 66 46 86 79 80
同学6 93 76 91 66 49
同学7 93 99 82 88 63
同学8 45 58 85 49 50
同学9 60 72 53 76 62
----------------------------------------------------------------------------------------------------
data =
美术 数学 英语 政治 体育
老师_0 74 90 98 59 98
老师_1 88 67 57 42 55
老师_2 98 90 84 47 96
老师_3 62 71 66 42 59
老师_4 92 40 46 84 53
老师_5 66 46 86 79 80
老师_6 93 76 91 66 49
老师_7 93 99 82 88 63
老师_8 45 58 85 49 50
老师_9 60 72 53 76 62
Process finished with exit code 0
三、重设索引列:reset_index()
设置新的下标索引
- drop:默认为False,不删除原来索引,如果为True,删除原来的索引值
- inplace:默认为False,返回一个新的DataFrame
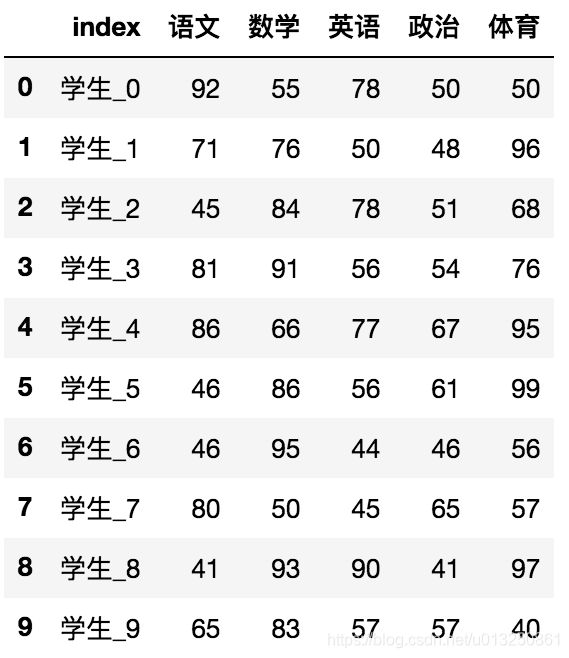
import numpy as np
import pandas as pd
# 生成10名同学,5门功课的数据
score = np.random.randint(40, 100, (10, 5))
print("score = \n", score)
print("-" * 100)
# 构造行索引序列
subjects = ["语文", "数学", "英语", "政治", "体育"]
# 构造列索引序列
stu = ['同学' + str(i) for i in range(score.shape[0])]
# 添加行索引
data = pd.DataFrame(score, columns=subjects, index=stu)
print("data = \n", data)
print("-" * 100)
# 重置索引,drop=False,inplace=False
data = data.reset_index(drop=False)
print("data = \n", data)
打印结果:
score =
[[47 53 73 81 42]
[82 98 77 95 51]
[55 59 64 76 65]
[51 67 77 61 71]
[83 53 50 97 69]
[67 69 92 69 55]
[55 81 87 68 43]
[74 45 51 43 53]
[54 51 71 63 82]
[52 88 57 64 69]]
----------------------------------------------------------------------------------------------------
data =
语文 数学 英语 政治 体育
同学0 47 53 73 81 42
同学1 82 98 77 95 51
同学2 55 59 64 76 65
同学3 51 67 77 61 71
同学4 83 53 50 97 69
同学5 67 69 92 69 55
同学6 55 81 87 68 43
同学7 74 45 51 43 53
同学8 54 51 71 63 82
同学9 52 88 57 64 69
----------------------------------------------------------------------------------------------------
data =
index 语文 数学 英语 政治 体育
0 同学0 47 53 73 81 42
1 同学1 82 98 77 95 51
2 同学2 55 59 64 76 65
3 同学3 51 67 77 61 71
4 同学4 83 53 50 97 69
5 同学5 67 69 92 69 55
6 同学6 55 81 87 68 43
7 同学7 74 45 51 43 53
8 同学8 54 51 71 63 82
9 同学9 52 88 57 64 69
Process finished with exit code 0
四、以某列值设置为新的索引:set_index()
set_index(keys, drop=True)
- keys : 列索引名成或者列索引名称的列表
- drop : boolean, default True.当做新的索引,删除原来的列
import numpy as np
import pandas as pd
df = pd.DataFrame({'month': [1, 4, 7, 10],
'year': [2012, 2014, 2013, 2014],
'sale': [55, 40, 84, 31]})
print("df = \n", df)
print("-" * 100)
# 以月份设置新的索引
df1 = df.set_index(keys='month')
print("df1 = \n", df1)
print("-" * 100)
# 设置多个索引,以年和月份
df2 = df.set_index(['year', 'month'])
print("df2 = \n", df2)
print("-" * 100)
打印结果:
df =
month year sale
0 1 2012 55
1 4 2014 40
2 7 2013 84
3 10 2014 31
----------------------------------------------------------------------------------------------------
df1 =
year sale
month
1 2012 55
4 2014 40
7 2013 84
10 2014 31
----------------------------------------------------------------------------------------------------
df2 =
sale
year month
2012 1 55
2014 4 40
2013 7 84
2014 10 31
----------------------------------------------------------------------------------------------------
Process finished with exit code 0
设置多个索引,以年和月份
注:通过刚才的设置,这样DataFrame就变成了一个具有MultiIndex的DataFrame。