吴恩达深度神经网络笔记—YOLO
目标
学习如何(1)在汽车检测数据集上使用对象检测;(2)处理边界框
导包
import argparse
import os
import matplotlib.pyplot as plt
from matplotlib.pyplot import imshow
import scipy.io
import scipy.misc
import numpy as np
import pandas as pd
import PIL
import tensorflow as tf
from keras import backend as K
from keras.layers import Input, Lambda, Conv2D
from keras.models import load_model, Model
from yolo_utils import read_classes, read_anchors, generate_colors, preprocess_image, draw_boxes, scale_boxes
from yad2k.models.keras_yolo import yolo_head, yolo_boxes_to_corners, preprocess_true_boxes, yolo_loss, yolo_body
%matplotlib inline
具体问题
数据集来自 drive.ai
将所有这些图像收集到一个文件夹中,并通过在找到的每辆车周围绘制边界框来标记它们。下面是一个边界框的示例。
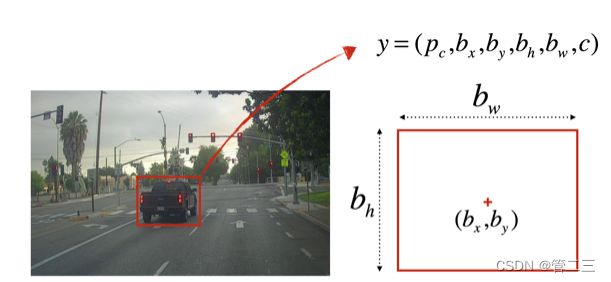
pc:置信度
bx,by:中心点坐标
bh,bw:矩形框长宽
c:框内类别
假如你想让YOLO识别80个分类,你可以把分类标签c从1到80进行标记,或者把它变为80维的向量(80个数字),在对应位置填写上0或1。视频中我们使用的是后面的方案。因为YOLO的模型训练起来是比较久的,我们将使用预先训练好的权重来进行使用。
YOLO(you only look once):在算法中“只看一次(only looks once)”的机制使得它在预测时只需要进行一次前向传播,在使用非最大值抑制后,它与边界框一起输出识别对象。
模型细节
输入的批量图片的维度为(m,608,608,3)
输出是一个识别分类与边界框的列表。每个边界框由6个数字组成:(px,bx,by,bh,bw,c)。如果你将c放到80维的向量中,那么每个边界框就由85个数字组成
使用5个锚框(anchor boxes),所以算法大致流程是这样的:图像输入(m,608,608,3)
⇒DEEP CNN⇒ 编码(m,19,19,5,85)。具体如下图:

如果对象的中心/中点在单元格内,那么该单元格就负责识别该对象
我们也使用了5个锚框,19x19的单元格,所以每个单元格内有5个锚框的编码信息,锚框的组成是pc+px+py+ph+pw
为了方便,我们将把最后的两个维度的数据进行展开,所以最后一步的编码由(m,19,19,5,85)变为了(m,19,19,425)。

对于每个单元格的每个锚框而言,我们将计算下列元素的乘积,并提取该框包含某一类的概率。如下图:
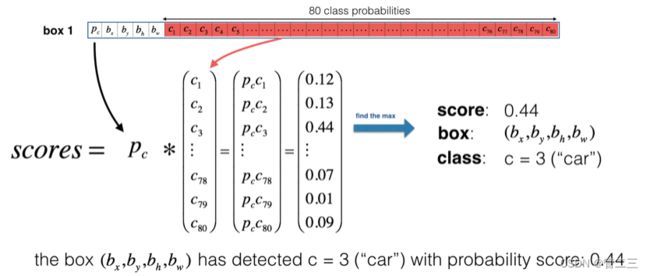
这里有张YOLO预测图的可视化预测:
- 对于每个19x19的单元格,找寻最大的可能性值,在5个锚框和不同的类之间取最大值
- 根据单元格预测的最可能的对象来使用添加颜色的方式来标记单元格。

需要注意的就是该可视化不是YOLO算法本身进行预测的核心部分,这只是一种可视化算法中间结果的比较d好的方法。另一种可视化YOLO输出的方法是绘制它输出的边界框,这样做会导致可视化是这样的:

在上图中们只绘制了模型所猜测的高概率的锚框,但锚框依旧是太多了。我们希望将算法的输出过滤为检测到的对象数量更少,要做到这一点,我们将使用非最大抑制。具体来说,我们将执行以下步骤:
- 舍弃掉低概率的锚框(意思是格子算出来的概率比较低我们就不要)
- 当几个锚框相互重叠并检测同一个物体时,只选择一个锚框。
分类阈值过滤
为了解决上面的问题,现在我们要为阈值进行过滤,我们要去掉一些预测值低于预设值的锚框。模型共计会有19×19×5×85个数字,每一个锚框由85个数字组成(80个分类+pc+px+py+ph+pw),将维度为(19,19,5,85)或者(19,19,425)转换为下面的维度将会有利于我们的下一步操作:
- box_confidence:tensor类型,维度为(19x19,5,1),包含19x19单元格中每个单元格预测的5个锚框中的所有的锚框的pc(一些对象的置信概率)
- boxes:tensor类型,维度为(19x19,5,4),包含了所有的锚框的(px,py,ph,pw)
- box_class_probs:tensor类型,维度为(19x19,5,80),包含了所有单元格中所有锚框的所有对象(c1,c2,c3,⋅⋅⋅,c80)检测的概率。
概率+框+种类
实现函数yolo_filter_boxes(),步骤如下:
-
计算对象的可能性:

-
对于每个锚框,需要找到:
对分类的预测的概率拥有最大值的锚框的索引(查看中文文档),需要注意的是我们需要选择的轴,我们可以试着使用axis=-1。
对应的最大值的锚框(查看中文文档),需要注意的是我们需要选择的轴,我们可以试着使用axis=-1 -
根据阈值来创建掩码,比如执行下列操作:[0.9, 0.3, 0.4, 0.5, 0.1] < 0.4,返回的是[False, True, False, False, True],对于我们要保留的锚框,对应的掩码应该为True或者1.
-
使用TensorFlow来对box_class_scores、boxes、box_classes进行掩码操作以过滤出我们想要的锚框
def yolo_filter_boxes(box_confidence, boxes, box_class_probs, threshold = .6):
box_scores = box_confidence * box_class_probs
box_classes = K.argmax(box_scores, axis=-1)
box_classes_scores = K.max(box_scores, axis=-1)
mask = (box_classes_scores>=threshold)
scores = tf.boolean_mask(box_classes_scores,mask)
boxes = tf.boolean_mask(boxes,mask)
classes = tf.boolean_mask(box_classes,mask)
return scores, boxes, classes
测试:
with tf.compat.v1.Session() as test_a:
box_confidence = tf.compat.v1.random_normal([19, 19, 5, 1], mean=1, stddev=4, seed = 1)
boxes = tf.compat.v1.random_normal([19, 19, 5, 4], mean=1, stddev=4, seed = 1)
box_class_probs = tf.compat.v1.random_normal([19, 19, 5, 80], mean=1, stddev=4, seed = 1)
scores, boxes, classes = yolo_filter_boxes(box_confidence, boxes, box_class_probs, threshold = 0.5)
print("scores[2] = " + str(scores[2].eval()))
print("boxes[2] = " + str(boxes[2].eval()))
print("classes[2] = " + str(classes[2].eval()))
print("scores.shape = " + str(scores.shape))
print("boxes.shape = " + str(boxes.shape))
print("classes.shape = " + str(classes.shape))
结果:
scores[2] = 10.750582
boxes[2] = [ 8.426533 3.2713668 -0.5313436 -4.9413733]
classes[2] = 7
scores.shape = (None,)
boxes.shape = (None, 4)
classes.shape = (None,)
非最大值抑制
第二个过滤器就是让下图左边变为右边,我们叫它非最大值抑制( non-maximum suppression (NMS))。

了解交并比:

在这里,我们要使用左上和右下角来定义方框(x1,y1,x2,y2)而不是使用中点+宽高的方式定义。
计算矩形的面积(y2−y1)乘以 (x2−x1)
找到两个锚框的交点的坐标(x1i,y1i,x2i,y2i)
- x1i =max{x1i }
- y1i =max{y1i }
- x2i =min{x2i }
- y2i =min{y2i }
def iou(box1, box2):
xi1 = np.maximum(box1[0],box2[0])
yi1 = np.maximum(box1[1],box2[1])
xi2 = np.minimum(box1[2],box2[2])
yi2 = np.minimum(box1[3],box2[3])
Inter = (yi2-yi1)*(xi2-xi1)
A = (box1[2]-box1[0])*(box1[3]-box1[1])
B = (box2[2]-box2[0])*(box2[3]-box2[1])
Union = A + B - Inter
iou = Inter / Union
return iou
测试:
box1 = (2, 1, 4, 3)
box2 = (1, 2, 3, 4)
print("iou = " + str(iou(box1, box2)))
结果:
iou = 0.14285714285714285
完成上述功能,就可以实现非最大值抑制函数,关键步骤如下:
- 选择分值高的锚框
- 计算与其他框的重叠部分,并删除与iou_threshold相比重叠的框。
- 返回第一步,直到不再有比当前选中的框得分更低的框。
使用TensorFlow实现,TensorFlow有两个内置函数用于实现非最大抑制(所以你实际上不需要使用你的iou()实现)
def yolo_non_max_suppression(scores, boxes, classes, max_boxes = 10, iou_threshold = 0.5):
max_boxes_tensor = K.variable(max_boxes, dtype='int32')
init = tf.compat.v1.variables_initializer([max_boxes_tensor])
K.get_session().run(init) # initialize variable max_boxes_tensor
NMS = tf.image.non_max_suppression(boxes,scores,max_boxes,iou_threshold)
scores = K.gather(scores,NMS)
boxes = K.gather(boxes,NMS)
classes = K.gather(classes,NMS)
return scores, boxes, classes
测试:
with tf.compat.v1.Session() as test_b:
scores = tf.compat.v1.random_normal([54,], mean=1, stddev=4, seed = 1)
boxes = tf.compat.v1.random_normal([54, 4], mean=1, stddev=4, seed = 1)
classes = tf.compat.v1.random_normal([54,], mean=1, stddev=4, seed = 1)
scores, boxes, classes = yolo_non_max_suppression(scores, boxes, classes)
print("scores[2] = " + str(scores[2].eval()))
print("boxes[2] = " + str(boxes[2].eval()))
print("classes[2] = " + str(classes[2].eval()))
print("scores.shape = " + str(scores.eval().shape))
print("boxes.shape = " + str(boxes.eval().shape))
print("classes.shape = " + str(classes.eval().shape))
结果:
scores[2] = 6.938395
boxes[2] = [-5.299932 3.1379814 4.450367 0.95942086]
classes[2] = -2.2452729
scores.shape = (10,)
boxes.shape = (10, 4)
classes.shape = (10,)
对所有框进行过滤
现在我们要实现一个CNN(19x19x5x85)输出的函数,并使用刚刚实现的函数对所有框进行过滤。
我们要实现的函数名为yolo_eval(),它采用YOLO编码的输出,并使用分数阈值和NMS来过滤这些框。你必须知道最后一个实现的细节。有几种表示锚框的方式,例如通过它们的角或通过它们的中点和高度/宽度。YOLO使用以下功能(我们提供)在不同时间在几种这样的格式之间进行转换:
boxes = yolo_boxes_to_corners(box_xy, box_wh)
它将yolo锚框坐标(x,y,w,h)转换为角的坐标(x1,y1,x2,y2)以适应yolo_filter_boxes()的输入。
boxes = yolo_utils.scale_boxes(boxes, image_shape)
YOLO的网络经过训练可以在608x608图像上运行。如果你要在不同大小的图像上测试此数据(例如,汽车检测数据集具有720x1280图像),则此步骤会重新缩放这些框,以便在原始的720x1280图像上绘制它们。
def yolo_eval(yolo_outputs, image_shape = (720., 1280.), max_boxes=10, score_threshold=.6, iou_threshold=.5):
box_confidence,box_xy,box_wh,box_class_probs = yolo_outputs
boxes = yolo_boxes_to_corners(box_xy, box_wh)
scores, boxes, classes = yolo_filter_boxes(box_confidence, boxes, box_class_probs, score_threshold)
boxes = scale_boxes(boxes, image_shape)
scores, boxes, classes = yolo_non_max_suppression(scores, boxes, classes,max_boxes,iou_threshold)
return scores, boxes, classes
测试:
with tf.compat.v1.Session() as test_b:
yolo_outputs = (tf.compat.v1.random_normal([19, 19, 5, 1], mean=1, stddev=4, seed = 1),
tf.compat.v1.random_normal([19, 19, 5, 2], mean=1, stddev=4, seed = 1),
tf.compat.v1.random_normal([19, 19, 5, 2], mean=1, stddev=4, seed = 1),
tf.compat.v1.random_normal([19, 19, 5, 80], mean=1, stddev=4, seed = 1))
scores, boxes, classes = yolo_eval(yolo_outputs)
print("scores[2] = " + str(scores[2].eval()))
print("boxes[2] = " + str(boxes[2].eval()))
print("classes[2] = " + str(classes[2].eval()))
print("scores.shape = " + str(scores.eval().shape))
print("boxes.shape = " + str(boxes.eval().shape))
print("classes.shape = " + str(classes.eval().shape))
def predict(sess, image_file):
image, image_data = preprocess_image("images/" + image_file, model_image_size = (608, 608))
out_scores, out_boxes, out_classes = sess.run([scores, boxes, classes], feed_dict = {yolo_model.input:image_data, K.learning_phase(): 0})
print('Found {} boxes for {}'.format(len(out_boxes), image_file))
colors = generate_colors(class_names)
draw_boxes(image, out_scores, out_boxes, out_classes, class_names, colors)
image.save(os.path.join("out", image_file), quality=90)
output_image = scipy.misc.imread(os.path.join("out", image_file))
imshow(output_image)
return out_scores, out_boxes, out_classes
结果:
(19, 19, 5, 1)
(19, 19, 5, 2)
(19, 19, 5, 2)
(19, 19, 5, 80)
scores[2] = 138.79124
boxes[2] = [1292.3297 -278.52167 3876.9893 -835.56494]
classes[2] = 54
scores.shape = (10,)
boxes.shape = (10, 4)
classes.shape = (10,)
总结步骤
- 输入图像为(608,608,3)
- 输入的图像先要通过一个CNN模型,返回一个(19,19,5,85)的数据。
- 在对最后两维降维之后,输出的维度变为了(19,19,425)
- 根据以下规则选择锚框:
预测分数阈值:丢弃分数低于阈值的分类的锚框。
非最大值抑制:计算交并比,并避免选择重叠框。 - 最后给出YOLO的最终输出。
测试已经训练好了的YOLO模型
with tf.compat.v1.Session() as sess:
class_names = read_classes("model_data/coco_classes.txt")
anchors = read_anchors("model_data/yolo_anchors.txt")
image_shape = (720., 1280.)
yolo_model = load_model("model_data/yolo.h5")
yolo_outputs = yolo_head(yolo_model.output, anchors, len(class_names))
scores, boxes, classes = yolo_eval(yolo_outputs, image_shape)
out_scores, out_boxes, out_classes = predict(sess, "test.jpg")
结果:
(None, None, None, 5, 1)
(None, None, None, 5, 2)
(None, None, None, 5, 2)
(None, None, None, 5, 80)
Found 7 boxes for test.jpg
car 0.60 (925, 285) (1045, 374)
car 0.66 (706, 279) (786, 350)
bus 0.67 (5, 266) (220, 407)
car 0.70 (947, 324) (1280, 705)
car 0.74 (159, 303) (346, 440)
car 0.80 (761, 282) (942, 412)
car 0.89 (367, 300) (745, 648)