【Python实战】海量表情包炫酷来袭,快来pick斗图新姿势吧~(超好玩儿)
前言
有温度 有深度 有广度 就等你来关注哦~
所有文章完整的素材+源码都在
粉丝白嫖源码福利,请移步至CSDN社区或文末公众hao即可免费。

你有在聊天中遇到不知道该如何表达,如何回复的情况吗?
或许,使用表情包,可以帮你解决这个问题啦~
——开启话题
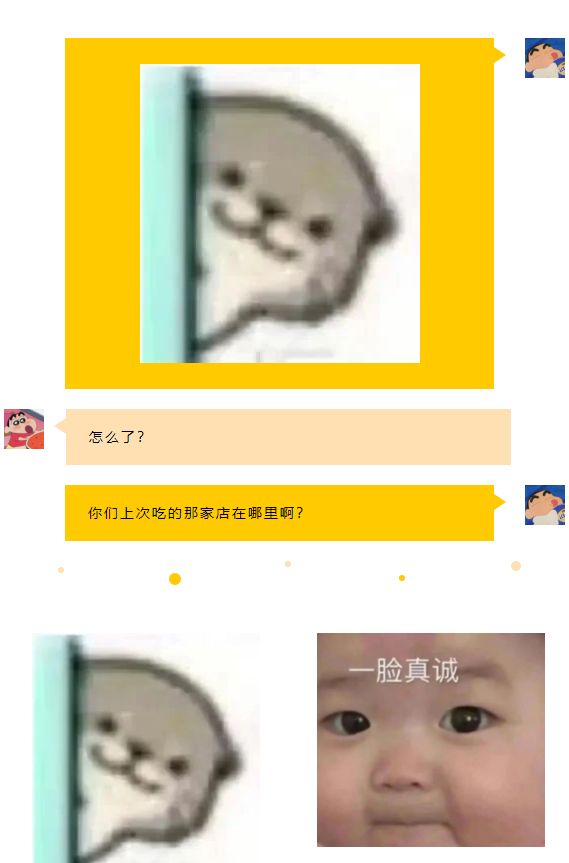
图一:探出脑袋张望,仿佛在寻找着什么。简单的一个动作就能让对方理解你的意思。
图二:“一脸真诚”地凝视着对方,想找对方聊天之意不言而喻。
哈哈哈~今天就带大家来探索表情包的奥秘吧

正文
一大波表情包来袭,请接收

一、运行环境
1)Python环境
环境: Python 3 、Pycharm、requests、 parsel 。其他内置模块,安装 好
python环境就可以了。 (win + R 输入cmd 输入安装命令 pip install 模块名 (如果你觉得安
装速度比较慢, 你可 以切换国内镜像源))
第三方库的安装:
pip install + 模块名 或者 带镜像源 pip install -i pypi.douban.com/simple/ +模块名
2)爬虫思路
1. 我们确定一下自己需求(我们要爬什么东西)? 我们爬取表情包网站所有表情包 图片
2. 我们要对这个网站 进行分析,找到这些图片来源
3. 代码实现 用python对浏览器发送请求 解析数据 提取想要数据内容 保存数据
二、代码展示
1)单线程
"""
import requests # 第三方模块 是需要我们安装 pip instlal requests read time out
import parsel # 第三方模块 pip install parsel
import re
import time
def change_title(title):
mode = re.compile(r'[\\\/\:\*\?\"\<\>\|]')
new_title = re.sub(mode, "_", title)
return new_title
time_1 = time.time()
# 请求网址
for page in range(1, 11):
url = f'https://www.fabiaoqing.com/biaoqing/lists/page/{page}.html'
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
# 返回网页源代码
response = requests.get(url=url, headers=headers)
# print(response.text)
# 解析数据 re css xpath
selector = parsel.Selector(response.text) # 把respons.text 转换成 selector 对象
# 第一次提取 提取所有的div标签内容
divs = selector.css('#container div.tagbqppdiv') # css 根据标签提取内容
for div in divs:
# 通过标签内容提取他的图片url地址
img_url = div.css('img::attr(data-original)').get()
# 提取标题
title = div.css('img::attr(title)').get()
# 获取图片的后缀名
name = img_url.split('.')[-1]
# 保存数据
# 因为文件命名不明还有 特殊字符 所以我们需要通过正则表达式 替换掉特殊字符
new_title = change_title(title)
# 对表情包图片发送请求 获取它二进制数据
img_content = requests.get(url=img_url, headers=headers).content
# 保存数据
try:
with open('img\\' + new_title + '.' + name, mode='wb') as f:
# 写入图片二进制数据
f.write(img_content)
print('正在保存:', title)
except:
pass
time_2 = time.time()
use_time = int(time_2) - int(time_1)
print(f'总共耗时:{use_time}秒')
2)多线程
import requests # 第三方模块 是需要我们安装 pip instlal requests read time out
import parsel # 第三方模块 pip install parsel
import re
import time
import concurrent.futures # 线程池
def change_title(title):
"""替换标题中的特殊字符"""
mode = re.compile(r'[\\\/\:\*\?\"\<\>\|]')
new_title = re.sub(mode, "_", title)
return new_title
def get_response(html_url):
"""对网站发送请求"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
repsonse = requests.get(url=html_url, headers=headers)
return repsonse
def save(title, img_url, name):
"""保存数据"""
img_content = get_response(img_url).content
try:
with open('img\\' + title + '.' + name, mode='wb') as f:
# 写入图片二进制数据
f.write(img_content)
print('正在保存:', title)
except:
pass
def main(html_url):
"""主函数"""
html_data = get_response(html_url).text
selector = parsel.Selector(html_data) # 把respons.text 转换成 selector 对象
# 第一次提取 提取所有的div标签内容
divs = selector.css('#container div.tagbqppdiv') # css 根据标签提取内容
for div in divs:
# 通过标签内容提取他的图片url地址
img_url = div.css('img::attr(data-original)').get()
# 提取标题
title = div.css('img::attr(title)').get()
# 获取图片的后缀名
name = img_url.split('.')[-1]
# 保存数据
# 因为文件命名不明还有 特殊字符 所以我们需要通过正则表达式 替换掉特殊字符
new_title = change_title(title)
save(new_title, img_url, name)
if __name__ == '__main__':
time_1 = time.time()
exe = concurrent.futures.ThreadPoolExecutor(max_workers=10)
for page in range(1, 201):
url = f'https://www.fabiaoqing.com/biaoqing/lists/page/{page}.html'
exe.submit(main, url)
exe.shutdown()
time_2 = time.time()
use_time = int(time_2) - int(time_1)
print(f'总共耗时:{use_time}秒')三、效果展示
1)单线程

2)多线程
看图就可以看出来的哈!单线程跟多线程的区别就留给大家思考啦~
总结
身处表情包时代,谁的手机里能没点藏货?正所谓,没有表情包的聊天是没有灵魂的
想要成为斗图界的天花板,会点儿代码技术必不可少。想要多少自己取就是了。
好啦文章结束,大家记得点点关注哦~
✨完整的素材源码等:可以滴滴我吖!或者点击文末hao自取免费拿的哈~
推荐往期文章——
项目0.2 【Python实战】WIFI密码小工具,甩万能钥匙十条街,WIFI任意连哦~(附源码)
项目0.3 【Python实战】再分享一款商品秒杀小工具,我已经把压箱底的宝贝拿出来啦~
项目0.1 【Python抢票神器】火车票枪票软件到底靠谱吗?实测—终极攻略。
项目0.4 【Python实战】年底找工作,年后不用愁,多个工作岗位随你挑哦~
文章汇总——
Python文章合集 | (入门到实战、游戏、Turtle、案例等)
(文章汇总还有更多你案例等你来学习啦~源码找我即可免费!)
