UEA数据集和UCR数据集的处理
摘要:本文主要内容为针对tsv格式的UCR数据集和arff格式的UEA数据集进行处理,将其中的标签和数据分离出来,并转换为csv文件
目录
前言
数据集
UCR数据集处理
UEA数据集处理
总结
前言
UEA数据集和UCR数据集,目前是时间序列挖掘领域重要的开源数据集资源,每个数据集样本都带有样本类别标签,为了方便处理,这里将其中的标签和数据分离出来,并转换为csv文件
数据集
UCR数据集
注:下载数据集后,解压缩密码为 someone
UEA数据集
点击链接,下载如图所示的arff格式的UEA数据集:
下载后的数据集如图所示:
UCR数据集:
UEA数据集

UCR数据集处理
代码如下:
import os
import pandas as pd
datapath="E:/桌面/代码/数据集/UCRArchive_2018/UCRArchive_2018"
save_data_path="E:/桌面/代码/数据集/UCRArchive_2018_csv"
def cope_UCR(datapath,save_data_path):
'''
:param datapath: tsv格式的UCR数据集路径,type:string
该数据集结构为:
-E:/桌面/代码/数据集/UCRArchive_2018/UCRArchive_2018
-ACSF1
-ACSF1_TEST.tsv
-ACSF1_TRAIN.tsv
-README.md
-Adiac
-Adiac_TEST.tsv
-Adiac_TRAIN.tsv
-README.md
-AllGestureWiimoteX
-AllGestureWiimoteX_TEST.tsv
-AllGestureWiimoteX_TRAIN.tsv
-README.me
-......
:param save_data_path: 保存转换为csv格式的UCR数据集的路径 type:string
该数据集结构为:
-E:/桌面/代码/数据集/UCRArchive_2018_csv
-ACSF1
-TEST.csv
-TEST_label.csv
-TRAIN.csv
-TRAIN_label.csv
-Adiac
-TEST.csv
-TEST_label.csv
-TRAIN.csv
-TRAIN_label.csv
-AllGestureWiimoteX
-TEST.csv
-TEST_label.csv
-TRAIN.csv
-TRAIN_label.csv
-......
每个数据集下包含测试集数据、测试集标签、训练集数据、训练集标签
:return:None
'''
data_list=os.listdir(datapath)
for data_name in data_list:
#读取每个数据集下的train test readme文件
new_data_path=datapath+"/"+data_name
train_test_readme=os.listdir(new_data_path)
for data_file in train_test_readme:
if data_file.endswith('.tsv'):#如果文件以tsv结尾
data_label = pd.read_csv(new_data_path+"/"+data_file, sep='\t',header=None)
label = data_label.iloc[:, 0]
data = data_label.iloc[:, 1:]
data_csv_dir=save_data_path+"/"+data_name
#如果数据目录不存在,则创建
if not os.path.exists(data_csv_dir):
os.mkdir(data_csv_dir)
# 将标签和数据分别存到csv文件中
file_name=data_file.split('_')[1].split('.')[0]
prefix_path=data_csv_dir+"/"+file_name
#用savetxt精度会出问题
# label=data_label.iloc[:,0].values
# data=data_label.iloc[:,1:].values
# np.savetxt(prefix_path+"_label.csv", label, delimiter=",",encoding='utf-8',fmt='%f')
# np.savetxt(prefix_path+".csv", data, delimiter=",",encoding='utf-8',fmt='%f')
label.to_csv(prefix_path+"_label.csv",mode='w',index=False,header=None,encoding='utf-8')
data.to_csv(prefix_path+".csv",mode='w',index=False,header=None,encoding='utf-8')
print(data_name)
cope_UCR(datapath,save_data_path)
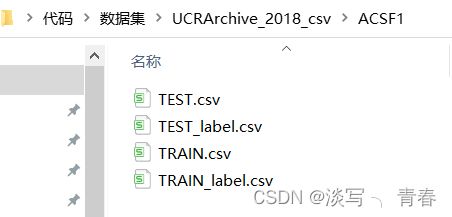
效果如图:
UEA数据集处理
代码如下:
import pandas as pd
import os
import natsort
data_set_dir='E:/桌面/代码/数据集/Multivariate2018_arff/Multivariate_arff'
data_save_dir='E:/桌面/代码/数据集/Multivariate2018_arff_csv'
def arff_to_csv(data_set_dir,data_save_dir):
'''
:param data_set_dir: 下载的数据集路径
:param data_save_dir: 保存csv数据集的保存路径
:return: None
'''
# 读取数据包下的所有数据名
data_set_list=os.listdir(data_set_dir)
for dataset_name in data_set_list:
# dataset_name为[ArticularyWordRecognition,AtrialFibrillation,BasicMotions,CharacterTrajectories,...]
dataset_name_path=data_set_dir+"/"+dataset_name
if os.path.isdir(dataset_name_path):#如果为路径,遍历该路径下的所有文件
# dataset_name_path_list=os.listdir(dataset_name_path)
#路径列表按照系统排序方式进行排序
dataset_name_path_list = natsort.natsorted(os.listdir(dataset_name_path), alg=natsort.ns.PATH)
# 数据集标签是否已写入的标志
train_label_tag = False
test_label_tag = False
for data_file in dataset_name_path_list:
#数据格式
data_format=data_file.split('.')[1]
#文件名
data_name=data_file.split('.')[0]
#只转换arff文件和包含Dimension文件
if data_format=='arff' and 'Dimension' in data_name:
# 训练集还是测试集
train_or_test = data_name.split('_')[1].lower()
file_name=dataset_name_path+"/"+data_file
with open(file_name,encoding="utf-8") as f:
header = []
for line in f:
if line.startswith("@attribute"):
header.append(line.split()[1])
elif line.startswith("@data"):
break
if os.path.getsize(file_name) > 0:
data_label = pd.read_csv(f, header=None)
else:
print("---发现一个空数据文件---"+data_file)
continue
#标签
label = data_label.iloc[:, -1]
#数据
data = data_label.iloc[:, :data_label.shape[1]-1]
data_csv_dir = data_save_dir + "/" + dataset_name
# 如果数据目录不存在,则创建
if not os.path.exists(data_csv_dir):
os.mkdir(data_csv_dir)
file_name_data=data_save_dir+"/"+dataset_name+"/"+data_name
file_name_label = data_save_dir + "/" + dataset_name + "/" + train_or_test + "_label.csv"
if not train_label_tag and train_or_test == 'train':#如果数据集的标签未写入且为训练集,则写入训练集的标签
label.to_csv(file_name_label , mode='w', index=False, header=None, encoding='utf-8')
train_label_tag=True
if not test_label_tag and train_or_test == 'test':#如果数据集的标签未写入且为测试集,则写入测试集的标签
label.to_csv(file_name_label , mode='w', index=False, header=None, encoding='utf-8')
test_label_tag = True
data.to_csv(file_name_data + ".csv", mode='w', index=False, header=None, encoding='utf-8')
print(data_file)
print(dataset_name)
arff_to_csv(data_set_dir,data_save_dir)
效果如图:

总结
arff格式的UEA数据集的处理当然可以使用Weka软件进行处理,具体参考:
Weka使用
但是一个一个转换起来太麻烦了,还不如自己写个python程序。