吴恩达机器学习作业Python实现(六):支持向量机
目录
1 支持向量机SVM
1.1 示例数据集1
1.2 高斯核函数支持向量机
1.2.1 高斯核
1.2.2 示例数据集2
1.2.3 示例数据集3
2 垃圾邮件分类
2.1 预处理邮件
2.1.1 词汇表
2.2 从邮件提取特征
2.3 训练SVM
参考文章
1 支持向量机SVM
在本练习前半部分,将对各种2D数据集使用支持向量机,通过这些数据集可以更加直观了解支持向量机的工作方式,以及如何在支持向量机中使用高斯核。后半部分,使用支持向量机搭建一个垃圾邮件分类器
1.1 示例数据集1
这是一个可以由线性边界分隔的数据集,首先我们先对数据进行可视化,可看到大约在左上角有一个异常的正样例,通过这个异常值,我们可以观察SVM决策边界是如何变化
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
from scipy.io import loadmat
from sklearn import svm
from jupyterthemes import jtplot # 用于解决坐标无法显示问题
jtplot.style(theme='chesterish') #选择一个绘图主题
path1 = r'E:/Code/ML/ml_learning/ex6-SVM/data/ex6data1.mat'
data1 = loadmat(path1)
X, y = data1['X'],data1['y']
# X是坐标点,y标签
def plotData(X, y):
"""数据可视化"""
plt.figure(figsize=(8,5))
# 将y展开,并用其值区分正负样本,cmap是设置颜色效果
plt.scatter(X[:,0], X[:,1], c=y.flatten(), cmap='rainbow')
plt.xlabel('X1')
plt.ylabel('X2')
plotData(X,y)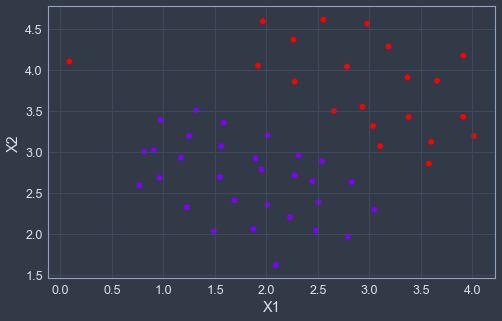
接下来我们调用就不自己写SVM模型代码,而是直接调用sklearn包,需要注意y得展平再传入模型中,训练好模型后就是将决策边界可视化,需要注意的是在这里我们不需要自己额外添加x0=1,模型中会自动添加。
# 调用模型,训练模型
# 这里使用列表推导式减少代码行数
models = [svm.SVC(C, kernel='linear') for C in [1, 100]]
clfs = [model.fit(X, y.ravel()) for model in models]def plotBoundary(clf, X):
'''画决策边界'''
x_min, x_max = X[:,0].min()*1, X[:,0].max()*1
y_min, y_max = X[:,1].min()*1,X[:,1].max()*1
# 画等高线
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 500),
np.linspace(y_min, y_max, 500))# (500,500)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) #(250000,)
Z = Z.reshape(xx.shape)
plt.contour(xx, yy, Z)
title = ['SVM Decision Boundary with C = {} (Example Dataset 1'.format(C) for C in [1, 100]]
for model,title in zip(clfs,title):
plt.figure(figsize=(8,5))
plotData(X, y)
plotBoundary(model, X)
plt.title(title)C是控制错误分类训练示例的惩罚,类似于1 / λ ,λ是前面逻辑回归时使用的正则化参数。可以看得出来C = 1时,SVM将决策边界放在了正负样本的中间,但是却将异常值做出了误分类,而当C = 100时对异常值做出了正确分类,但是其决策边界与数据并不自然匹配。
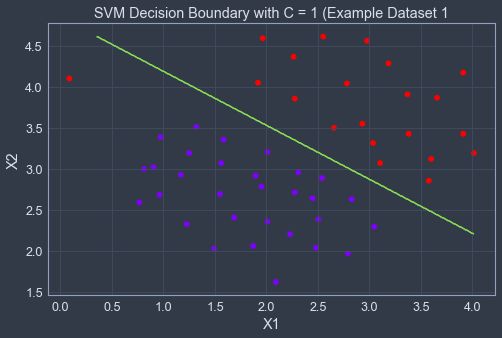
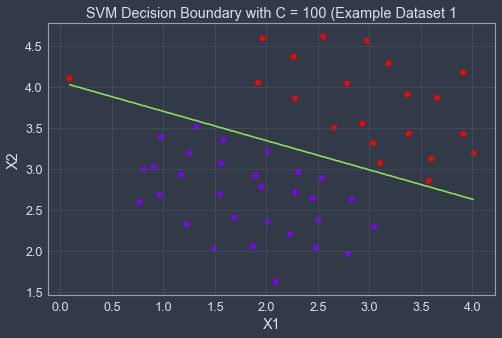
1.2 高斯核函数支持向量机
在这部分练习中,将使用支持向量机进行非线性分类。特别地,您将在不可线性分离的数据集上使用带有高斯核的支持向量机。
1.2.1 高斯核
在实现SVM之前,我们需要先实现一个高斯核函数,高斯核函数可看成相似函数,用于衡量两个例子之间的距离。它的公式如下。
![]()
def gaussKernel(x1,x2,sigma):
return np.exp(-((x1-x2) ** 2).sum() / (2 * sigma ** 2))
gaussKernel(np.array([1, 2, 1]), np.array([0, 4, -1]), 2.) 写好函数后,我们使用两个测试样例测试内核函数,可以得到0.32465
1.2.2 示例数据集2
首先我们将数据可视化,直接调用前面写的plotData函数即可
path2 = r'E:/Code/ML/ml_learning/ex6-SVM/data/ex6data2.mat'
data2 = loadmat(path2)
X2 = data2['X']
y2 = data2['y']
plotData(X2,y2)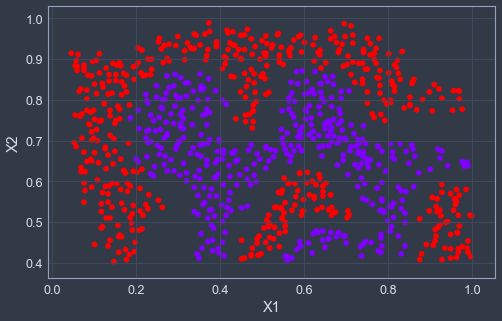
可以看得出决策边界并非线性的,但是我们可以通过在SVM中使用高斯核来学习到一个非线性的决策边界,注意一下这里svc函数的kernel = 'rbf',其中rbf函数的表达式为exp(-gamma|u-v|^2),所以gamma需要根据上面我们写的公式构造。
sigma = 0.1
gamma = np.power(sigma, -2) / 2
clf2 = svm.SVC(C=1, kernel='rbf', gamma=gamma)
model2 = clf2.fit(X2, y2.flatten())
plt.figure(figsize=(8,5))
plotData(X2,y2)
plotBoundary(model2, X2)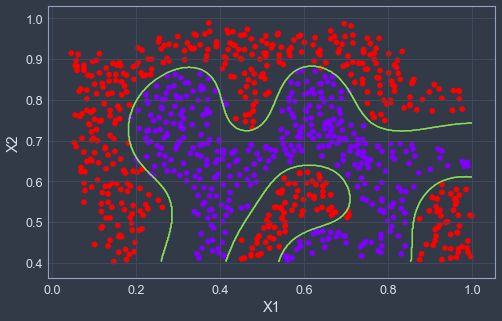
1.2.3 示例数据集3
在这一部分,继续使用高斯核SVM来找出非线性决策边界,并且通过交叉验证集来找出最优的参数,首先先进行数据可视化。
path3 = r'E:/Code/ML/ml_learning/ex6-SVM/data/ex6data3.mat'
data3 = loadmat(path3)
X3, y3 = data3['X'], data3['y']
Xval, yval = data3['Xval'], data3['yval']
plotData(X3, y3)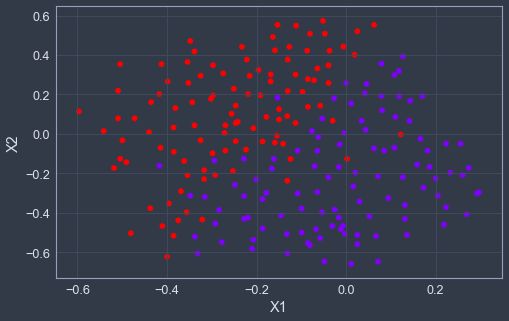
Cvalues = [0.01, 0.03, 0.1, 0.3, 1., 3., 10., 30.]
sigmavalues = Cvalues
best_parameter, best_score = [0, 0], 0
for C in Cvalues:
for sigma in sigmavalues:
gamma = np.power(sigma,-2.)/2
model = svm.SVC(C=C,kernel='rbf',gamma=gamma)
model.fit(X3, y3.flatten())
this_score = model.score(Xval, yval)
if this_score > best_score:
best_score = this_score
best_parameter = [C, sigma]
print('best_parameter={}, best_score={}'.format(best_parameter, best_score))
# best_parameter=[1.0, 0.1], best_score=0.965然后使用最优参数来学习决策曲线。
model = svm.SVC(C=1., kernel='rbf', gamma = np.power(0.1, -2.)/2)
model.fit(X3, y3.flatten())
plotData(X3, y3)
plotBoundary(model, X3)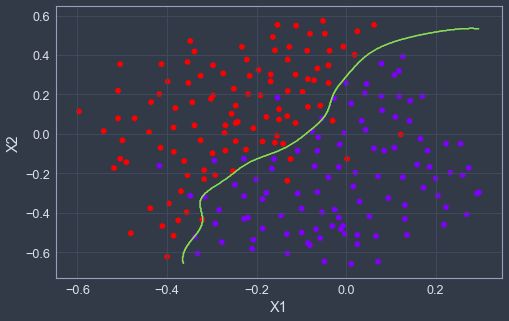
2 垃圾邮件分类
在这一部分练习,我们将使用SVM构建自己的垃圾邮件过滤器。其中我们的电子邮件,如果是是垃圾邮件则y=1,非垃圾邮件y=0,除此之外我们还需要将每一封电子邮件转化成特征向量。需要注明的是,本练习所包含的数据集是基于SpamAssassin公共语料库的一个子集。为了达到练习目的,我们将只使用电子邮件正文(不包括电子邮件标题)。
2.1 预处理邮件
首先我们先对一个例子进行可视化。
path4 = r'E:/Code/ML/ml_learning/ex6-SVM/data/emailSample1.txt'
with open(path4) as f:
email = f.read()
print(email)> Anyone knows how much it costs to host a web portal ?
>
Well, it depends on how many visitors you're expecting.
This can be anywhere from less than 10 bucks a month to a couple of $100.
You should checkout http://www.rackspace.com/ or perhaps Amazon EC2
if youre running something big..
To unsubscribe yourself from this mailing list, send an email to:
[email protected]通过上面的内容可以看出其中包含一个URL、一个邮件地址、数字和金额。虽然许多邮件都会包括这些内容,但是不同的邮件是不同的,因此在处理电子邮件前先需要“规范化”这些值,使得所有内容被同等对待,比如我们可以使用唯一字符串httpaddr代替电子邮件里面每一个URL,以表示存在一个URL。这样做的目的是让垃圾分类器根据是否存在URL而不是特定URL是否存在来做出分类决策。下面是一些邮件预处理和规范步骤。
- 大小写字母转换:将整个电子邮件被转换为小写,因此大小写被忽略
- 删除HTML:许多电子邮件通常带有html格式,删除全部html标记,只剩下邮件内容
- 规范化URL:将全部URL都替换为字符串httpaddr
- 规范化邮箱地址:将全部电子邮件地址替换为字符串emailaddr
- 规范化数字:将全部数字替换成字符串number
- 规范化美元符号:将全部美元符号$替换成字符串dollar
- 词干提取:将单词简化成词干形式,如discount,discounts,discounted都替换成discount
- 删除非单词:删除非单词和标点符号,所有空白(制表符、换行符、空格)等都被剪裁为一个空格字符
import re # 正则表达式
from stemming.porter2 import stem # 英文分词算法
import nltk, nltk.stem.porter
def processEmail(email):
"""做前六项处理"""
email = email.lower() # 大写转小写
# 匹配<开头,然后所有不是< ,> 的内容,知道>结尾,相当于匹配<...>
email = re.sub('<[^<>]>', ' ', email)
# 匹配//后面不是空白字符的内容,遇到空白字符则停止
email = re.sub('(http|https)://[^\s]*', 'httpaddr', email )
email = re.sub('[^\s]+@[^\s]', 'emailaddr', email) # 匹配地址替换成emailaddr
email = re.sub('[\$]+', 'dollar', email) # 匹配金钱符号替换成dollar
email = re.sub('[\d]+', 'number', email) # 匹配数字替换成number
return email
print(processEmail(email))下面是提取词干,以及去除非字符内容
def email2TokenList(email):
"""返回一个干净的单词列表"""
# 实例化提取器
stemmer = nltk.stem.porter.PorterStemmer()
# 预处理邮件
email = processEmail(email)
# 分割单词
tokens = re.split('[ \@\$\/\#\.\-\:\&\*\+\=\[\]\?\!\(\)\{\}\,\'\"\>\_\<\;\%]', email)
token_list = []
for token in tokens:
# 删除非字母数字的字符
token = re.sub('[^a-zA-Z0-9]', '', token)
# 丢进提取器提取词根
stemmed_word = stemmer.stem(token)
# 去除空字符串, 非零为真
if not len(token): continue
token_list.append(stemmed_word)
return token_list2.1.1 词汇表
预处理之后,我们得到了电子邮件的单词列表,下一步是选择我们希望在分类器中使用哪些次,哪些词希望被去掉。
在这练习中,我们只考虑出现频率最高的单词作为我们的词汇表,我们有个词汇表vocab.txt,里面存储了实际中经常使用的单词,共1899个,最后我们计算出处理后的email中含有多少该词汇表中的单词,并返回该单词对应的索引,这便是我们想要的训练单词的索引。
def email2VocabIndices(email, vocab):
"""提取单词索引"""
token = email2TokenList(email)
# for i in range(len(vacab)):
# if vacab[i] in token
# index = i
index = [i for i in range(len(vocab)) if vocab[i] in token]
return index2.2 从邮件提取特征
def email2FeatureVector(email):
"""
email转为词向量 ,n是vocab的长度,存在单词的相应位置为1,其余0
"""
# 给单词那一列添加列名
df = pd.read_table(r'E:/Code/ML/ml_learning/ex6-SVM/data/vocab.txt', names=['words'])
# dataframe转array
vocab= df.values
# 长度与单词表长度相同
vector = np.zeros(len(vocab))
# 返回邮件单词索引
vocab_indices = email2VocabIndices(email, vocab)
# 将有单词的索引置1
for i in vocab_indices:
vector[i] = 1
return vectorvector = email2FeatureVector(email)
print('length of vector = {}\nnum of non-zero = {}'.format(len(vector), int(vector.sum())))length of vector = 1899
num of non-zero = 452.3 训练SVM
data1 = loadmat(r'E:/Code/ML/ml_learning/ex6-SVM/data/spamTrain.mat')
X, y = data1['X'], data1['y']
data2 = loadmat(r'E:/Code/ML/ml_learning/ex6-SVM/data/spamTest.mat')
Xtest, ytest = data2['Xtest'], data2['ytest']
clf = svm.SVC(C=0.1, kernel='linear')
clf.fit(X, y)
predTrain = clf.score(X, y)
predTest = clf.score(Xtest, ytest)
predTrain, predTest(0.99825, 0.989)参考文章
吴恩达机器学习与深度学习作业目录 [图片已修复]