半监督目标检测(四)
目录
Dense Learning based Semi-Supervised Object Detection
动机
1. Overview
2. Adaptive Filtering Strategy
3. MetaNet
4. Aggregated Teacher
5. Uncertainty Consistency
Dense Teacher
动机
1. Overview
2. Disadvantages of Pseudo-box Labels
1) Dilemma in Thresholding
2) Dilemma in Non-Maximum Suppression (NMS)
3) Inconsistent Label Assignment
3. Dense Pseudo-Label
4. Region Selection
Dense Learning based Semi-Supervised Object Detection
动机
此前的半监督目标检测(SSOD)模型基本都属于 anchor-based 检测器,作者认为在实际应用中对于 anchor-free 检测器的需求更大。包括 FCOS 在内的 anchor-free 检测器,是在像素层面上进行高密度的特征预测,因此在 SSOD 场景下,需要更加细粒度的伪标签。作者根据 anchor-free 检测器所具备的特点,针对性地提出了一种 DenSe Learning(DSL)based 半监督目标检测算法。
1. Overview
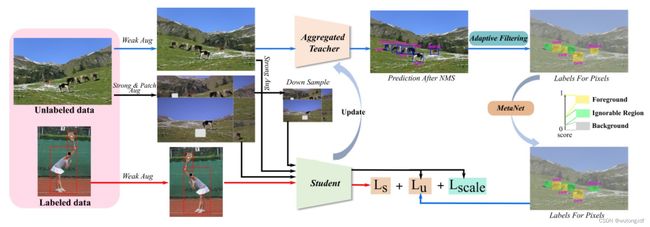
作者使用 FCOS (ResNet50 backbone + FPN neck+ dense head)作为 baseline,采用 教师-学生 模型,及强-弱数据增广方式进行训练。针对 anchor-free 检测器对 noisy pseudo-label 更加敏感这一问题,作者先采取 Adaptive Filtering(AF)策略,将生成的伪标签划分为 foreground,background,ignorable regions 三类(区别于过去前景、背景的单一划分);针对存在的高置信度错误预测,作者利用 MetaNet 进一步筛选伪标签;为了提高模型的泛化能力,作者引入了 ![]() 损失,对无标签图像在不同尺度上采取 patch shuffle 和 Uncertainty-Consistency regularization;最后,为了获取更加稳定和高质量的伪标签,作者使用 Aggregated Teacher(AF)方法,在学生模型的基础上更新教师模型。
损失,对无标签图像在不同尺度上采取 patch shuffle 和 Uncertainty-Consistency regularization;最后,为了获取更加稳定和高质量的伪标签,作者使用 Aggregated Teacher(AF)方法,在学生模型的基础上更新教师模型。


2. Adaptive Filtering Strategy
作者指出, 如果只使用一个阈值来划分前景和背景,那么很多实例有可能会被错误分类,会降低检测器的学习性能。因此,作者建议使用多阈值 ![]() ,将实例分为前景、背景、可忽略区域三部分,只计算前景和背景的损失:
,将实例分为前景、背景、可忽略区域三部分,只计算前景和背景的损失:


式(4)中,作者将筛选背景的阈值 ![]() = 0.1 设置为固定值;而筛选前景的
= 0.1 设置为固定值;而筛选前景的 ![]() 则设置为类别自适应的
则设置为类别自适应的 ![]() :
:

3. MetaNet
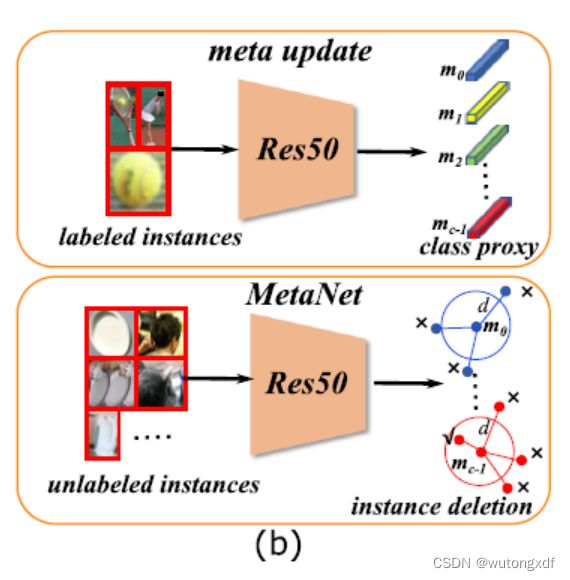
作者提出 MetaNet,主要是为了过滤掉一批高置信度的错误分类实例。作者使用 ResNet50 实现 MetaNet,在 DSL 训练之前,作者将所有带标签的实例输入 MetaNet,计算各个类别的 proxy vector ![]() :
:

之后,作者计算无标签实例的特征向量与对应类别 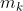 之间的余弦距离。若距离小于阈值 d = 0.6,则将该实例的“前景”标签更换为“可忽略区域”。
之间的余弦距离。若距离小于阈值 d = 0.6,则将该实例的“前景”标签更换为“可忽略区域”。
【补充】余弦距离: 用向量空间中两个向量夹角的余弦值,作为衡量两个个体间差异的大小的度量。

来源:机器学习:余弦距离(Cosine Dsitance)_电光闪烁的博客-CSDN博客
4. Aggregated Teacher
作者认为,使用 EMA Teacher 的方法集成学生模型参数,更新教师模型,仅仅针对单独的某一层聚合了训练迭代产生的参数信息,而没有考虑各层之间的关联性。因此,作者不仅使用 EMA Teacher 方法更新参数,同时也引入 Recurrent Layer Aggregation(RLA,出自论文 Recurrence along Depth: Deep Convolutional Neural Networks with Recurrent Layer Aggregation),将卷积同 RNN 结构相结合,聚合各层信息。
【注】作者只对 backbone 做层间聚合(循环结构)。


上式中,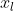 为第 l 层的张量,
为第 l 层的张量,![]() 为对应的卷积参数,
为对应的卷积参数,![]() 为第 l 层的 hidden state tensor,
为第 l 层的 hidden state tensor,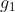 、
、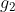 为1×1、3×3卷积层。
为1×1、3×3卷积层。
设 ![]() ,则上式可化为:
,则上式可化为:![]() ,
,![]() ,与 RLA 原论文中的操作一致(l 对应原论文中的 t):
,与 RLA 原论文中的操作一致(l 对应原论文中的 t):

【补充】循环神经网络(RNN)
来源:12.循环神经网络(基础篇)_哔哩哔哩_bilibili


5. Uncertainty Consistency

经过上述步骤获得较高质量的伪标签后,作者对无标签数据采取 uncertainty-consistency regularizaiton 的方法提升模型的泛化性能。具体来说,模型每次接受一对图像作为输入,分别是经过 Strong & Patch Augmented 的图像(![]() ),以及对应的2倍下采样版本(
),以及对应的2倍下采样版本(![]() ),产生不同尺度的密集特征图。
),产生不同尺度的密集特征图。
Patch shuffle augmentation 算法如下:

作者使用 patch shuffle 以减少前景目标对于周围环境的依赖,提升模型对于上下文信息的鲁棒性。
而计算 ![]() 则是为了提升模型对于不同尺度目标的鲁棒性:
则是为了提升模型对于不同尺度目标的鲁棒性:

Dense Teacher
Dense Teacher: Dense Pseudo-Labels for Semi-supervised Object Detection
动机
此前的SOTA半监督目标检测器(SSOD)大多数都基于伪框(pseudo-boxes)进行训练,而筛选伪框需要一系列后处理步骤,调试相应的超参数。作者认为使用伪框作为无监督图像的伪标签对于 SSOD 并不是最优的,因而提出 Dense Pseudo-Label(DPL)方法, 使用网络的原始输出作为伪标签,不经过任何后处理,保留了更丰富的信息。
1. Overview

Dense Teacher 使用 FCOS 作为基础检测器,ResNet-50 作为 backbone,总体框架与此前的伪标签范式相似。每次迭代,随机选取带标签和无标签图像组成 data batch;教师模型(学生模型的 EMA 参数集成)为无标签数据生成 DPL;随后学生模型使用带标签图像的 ground truth 和无标签图像的 DPL共同训练,分别计算监督损失 ![]() 和无监督损失
和无监督损失  :
:
![]()
虽然相较于此前的伪框标签,DPL 提供了更丰富的信息,但也包含了更多的噪声(低分预测)。为了缓解这一问题,作者采取区域选择(region selection)技巧,以突出关键区域信息,同时抑制密集标签携带的噪音。
2. Disadvantages of Pseudo-box Labels
1) Dilemma in Thresholding
在 SSOD 算法中,教师模型的输出将作为无监督图像的 “ground truth” 使用,而通过特定阈值 ![]() 筛选过滤掉一些低分预测框是其中很关键的一个步骤,也会很大程度上影响整体训练过程。然而作者通过实验指出,若将阈值设置得过高,那么会使得很多高质量预测被淘汰,产生很多 false negatives,从而导致训练根本无法收敛;而若将阈值设置得过低,那么由于大量 false positives 的出现,模型的性能也会随之降低。作者认为,很可能根本找不到一个能够保证伪框质量的合适阈值。
筛选过滤掉一些低分预测框是其中很关键的一个步骤,也会很大程度上影响整体训练过程。然而作者通过实验指出,若将阈值设置得过高,那么会使得很多高质量预测被淘汰,产生很多 false negatives,从而导致训练根本无法收敛;而若将阈值设置得过低,那么由于大量 false positives 的出现,模型的性能也会随之降低。作者认为,很可能根本找不到一个能够保证伪框质量的合适阈值。
2) Dilemma in Non-Maximum Suppression (NMS)
在此前的 SSOD 方法中,非极大值抑制(NMS)会作用于教师模型的原始输出,从而产生最终的伪框。而 NMS 也会设置一个 ![]() 阈值,来控制抑制程度。作者认为这个阈值的选取也会对 SSOD 算法产生不可忽视的影响。首先,不同的
阈值,来控制抑制程度。作者认为这个阈值的选取也会对 SSOD 算法产生不可忽视的影响。首先,不同的 ![]() 会给检测性能带来波动;其次,不同数据集对应的最优
会给检测性能带来波动;其次,不同数据集对应的最优 ![]() 也不同,这就带来了额外的调试负担;另外,对于密集场景(如 CrowdHuman 数据集),可能根本不存在一个最优的
也不同,这就带来了额外的调试负担;另外,对于密集场景(如 CrowdHuman 数据集),可能根本不存在一个最优的 ![]() 。
。
3) Inconsistent Label Assignment
由于伪框可能存在定位不准的问题,所以给各个位置(像素)分配类别标签时,很可能与真实标签存在不一致的情况(可以回顾一下 FCOS 的 center sampling),如下图:

3. Dense Pseudo-Label
作者不使用伪框形式的伪标签,而是直接使用训练模型输出的 post-sigmoid logits 作为伪标签。
【注】FCOS 的分类分支在预测特征图的每个位置上预测 C 个类别概率(C个二分类器),所以我觉得这里的 post-sigmoid logits 应该就是 Logistic Regression 中的 ![]() ,即:
,即:![]() 。
。
定义几率 odds :![]() ;
;
而 logit 即为 log-it ,其中的 "it" 为几率 odds,所以![]() ;
;
logit 即为 z,![]() ;
;
因而实际上,post-sigmoid logits 就是经过 sigmoid 之后的 z,即![]() 。
。
参考资料:Logit究竟是个啥?——离散选择模型之三 - 知乎
由于 DPL 是连续值,标准的 Focal Loss 在此不适用,所以作者采用了 Quality Focal Loss。
作者对每个锚(anchor-free 检测器为锚点 anchor point,区别于 anchor-based 检测器的锚框 anchor box)计算类别损失如下:

4. Region Selection
由于 DPL 携带了很多低分的预测,而这些低分预测往往覆盖信息量较少的背景区域,无益于学生模型的学习。所以作者使用 Feature Richness Score(FRS),将输入图像划分为学习区域和抑制区域两部分(非背景的分类得分的最大值作为 FRS)。

其中,![]() 表示教师模型的第 i 个样本(我对这里有些疑问,不知道是否应为第 i 个锚点)对应于第 c 个类别(共 C 个类别)的预测分值。
表示教师模型的第 i 个样本(我对这里有些疑问,不知道是否应为第 i 个锚点)对应于第 c 个类别(共 C 个类别)的预测分值。
随后,作者选择 top k% 分值的像素点作为学习区域,而其他区域将被抑制为 0。从而 DPL 将进行如下转化:

作者认为,这种 region selection 技巧能够较为容易地实现难例挖掘(Hard Negative Mining),也可以很轻易地将其应用于回归分支。
