4.3 pytorch数据预处理:transforms图像增强方法
一、数据增强概述
二、数据增强方法:裁剪
三、数据增强方法:翻转和旋转
四、数据增强方法:变换
五、transforms方法的选择操作
一、数据增强概述

我们来看图片中的数据增强是怎么样的。

左边的图像可以增强得到右边的图片,供模型训练。模型见过更多更丰富的样本,从而提高模型的泛化能力。
下面开始学习具体的数据增强方法。

二、裁剪
1. transforms.CenterCrop()

功能是对图像进行中心裁剪。
看例子,左边是224*224的图片。进行一个196*196的CenterCrop,得到右边的图像。
例:还是人民币的例子。
# -*- coding: utf-8 -*-
"""
# @file name : transforms_methods_1.py
# @author : TingsongYu https://github.com/TingsongYu
# @date : 2019-09-11 10:08:00
# @brief : transforms方法(一)
"""
import os
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
import numpy as np
import torch
import random
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from PIL import Image
from matplotlib import pyplot as plt
path_lenet = os.path.abspath(os.path.join(BASE_DIR, "model", "lenet.py"))
path_tools = os.path.abspath(os.path.join(BASE_DIR, "tools", "common_tools.py"))
assert os.path.exists(path_lenet), "{}不存在,请将lenet.py文件放到 {}".format(path_lenet, os.path.dirname(path_lenet))
assert os.path.exists(path_tools), "{}不存在,请将common_tools.py文件放到 {}".format(path_tools, os.path.dirname(path_tools))
import sys
'''
hello_pytorch_DIR = os.path.abspath(os.path.dirname(__file__)+os.path.sep+".."+os.path.sep+"..")
sys.path.append(hello_pytorch_DIR)
'''
from tools.my_dataset import RMBDataset
from tools.common_tools import set_seed, transform_invert
set_seed(1) # 设置随机种子
# 参数设置
MAX_EPOCH = 10
BATCH_SIZE = 1
LR = 0.01
log_interval = 10
val_interval = 1
rmb_label = {"1": 0, "100": 1}
# ============================ step 1/5 数据 ============================
split_dir = os.path.abspath(os.path.join(BASE_DIR, "data", "rmb_split"))
if not os.path.exists(split_dir):
raise Exception(r"数据 {} 不存在, 回到lesson-06\1_split_dataset.py生成数据".format(split_dir))
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 1 CenterCrop
transforms.CenterCrop(196), # 196
# 2 RandomCrop
# transforms.RandomCrop(224, padding=16),
# transforms.RandomCrop(224, padding=(16, 64)),
# transforms.RandomCrop(224, padding=16, fill=(255, 0, 0)),
# transforms.RandomCrop(512, pad_if_needed=True), # pad_if_needed=True
# transforms.RandomCrop(224, padding=64, padding_mode='edge'),
# transforms.RandomCrop(224, padding=64, padding_mode='reflect'),
# transforms.RandomCrop(1024, padding=1024, padding_mode='symmetric'),
# 3 RandomResizedCrop
# transforms.RandomResizedCrop(size=224, scale=(0.5, 0.5)),
# 4 FiveCrop
# transforms.FiveCrop(112),
# transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops])),
# 5 TenCrop
# transforms.TenCrop(112, vertical_flip=False),
# transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops])),
# 1 Horizontal Flip
# transforms.RandomHorizontalFlip(p=1),
# 2 Vertical Flip
# transforms.RandomVerticalFlip(p=0.5),
# 3 RandomRotation
# transforms.RandomRotation(90),
# transforms.RandomRotation((90), expand=True),
# transforms.RandomRotation(30, center=(0, 0)),
# transforms.RandomRotation(30, center=(0, 0), expand=True), # expand only for center rotation
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std)
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
# ============================ step 5/5 训练 ============================
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data # B C H W
img_tensor = inputs[0, ...] # C H W
img = transform_invert(img_tensor, train_transform) #这个函数用来对transform进行逆操作。使得可以观察到模型输入的数据长什么样。
plt.imshow(img)
plt.show()
plt.pause(0.5)
plt.close()
# bs, ncrops, c, h, w = inputs.shape
# for n in range(ncrops):
# img_tensor = inputs[0, n, ...] # C H W
# img = transform_invert(img_tensor, train_transform)
# plt.imshow(img)
# plt.show()
# plt.pause(1)后面的只要每次修改标红的地方就行了,就不全写了。
结果:

可以看到生成了196*196的图像。
如果要生成的图像大于224*224呢?比如参数改成256,我们看到程序不报错,而是能正确裁剪出256*256的图片。只不过对超出的部分会填充为0的像素。

2. transforms.RandomCrop()


随机裁剪出大小为size的图片。是随机位置的裁剪。
padding:当为一个数时,上下左右都填充a个像素。当时一个元组(a,b)时,左右填充a个像素,上下填充b个像素。当padding为(a,b,c,d)的元组时,对四边填充不同的值。
例1:对上下左右均进行16像素的padding。然后再在这个大的图片上进行224*224的随机选取。

结果:
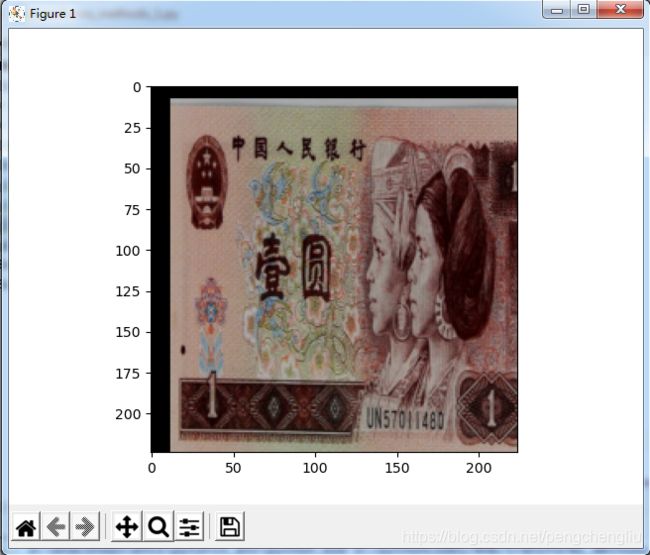
对上下左右均进行16像素的padding。然后再在这个大的图片上进行224*224的随机选取。
例2:左右填充16,上下填充64。然后随机选取224*224。
结果:
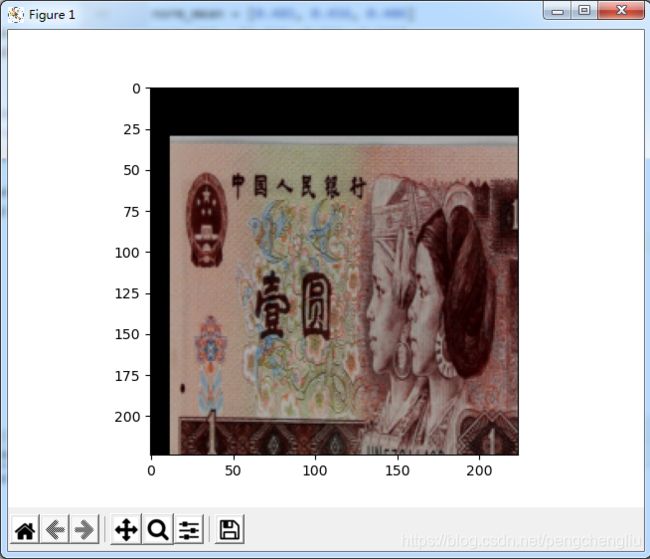
左右填充16,上下填充64。然后随机选取224*224。
例3:不想填充黑色的时候,可以通过fill进行设置。颜色为RGB。
结果:
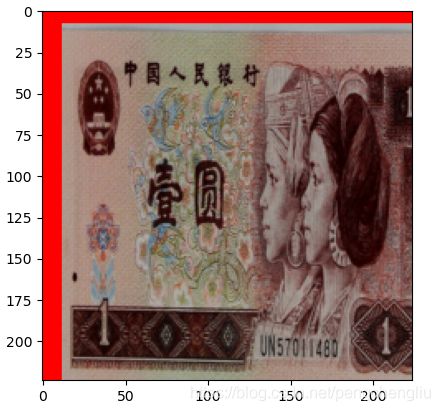
例4:当size大于图像尺寸的时候,一定要设pad_if_need为True,否则会报错。
结果报错:

把参数打开:

结果:
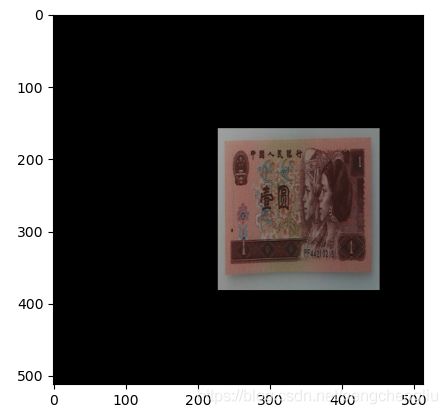
例5:由图片边缘的像素填充。
结果:
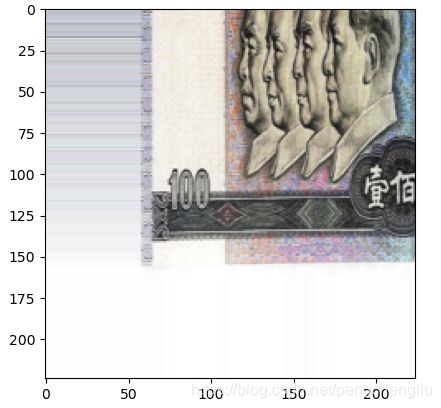
例6:镜像模式
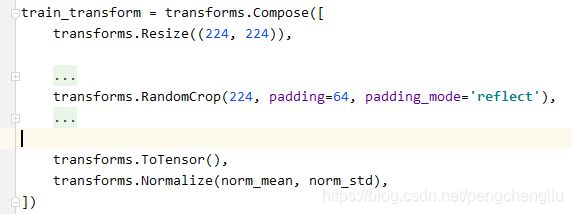
结果:
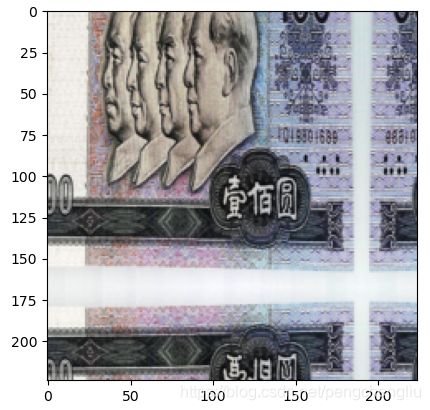
例7:镜像
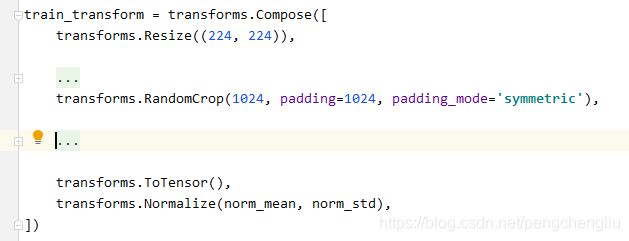
结果:
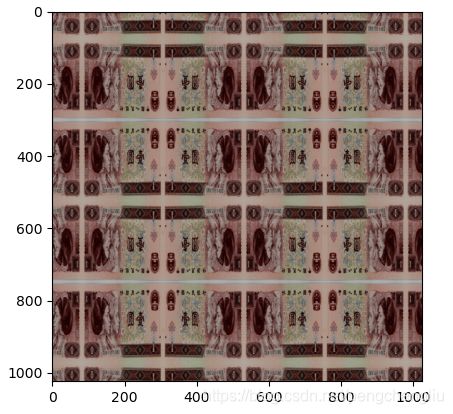
像不像印钞机!
3. RandomResizedCrop()

相比RandomCrop()多了一个Resized的操作。将给定图像随机裁剪为不同的大小和宽高比,然后缩放所裁剪得到的图像为指定的大小.(即先随机采集,然后对裁剪得到的图像缩放为同一大小)。
该操作的含义:即使只是该物体的一部分,我们也认为这是该类物体。比如 猫的图片别裁剪缩放后,仍然认为这是一个猫。
tatio:长宽比的区间是(3/4,4/3)。
插值方法:由于裁剪之后图片的尺寸可能会小于size,因此要对裁剪出来的图片进行插值,缩放到原始的图片
例1:

结果:

可以看到图片小了很多。
首先根据scale在0.08到1之间随机选取。然后根据长宽比ratio在(3/4,4/3)设定图形的长和宽。然后裁剪图片。裁剪完之后,resize到224*224。
例:将scale设为(0.5,0.5),这样每次都裁剪一半的图像。

结果:
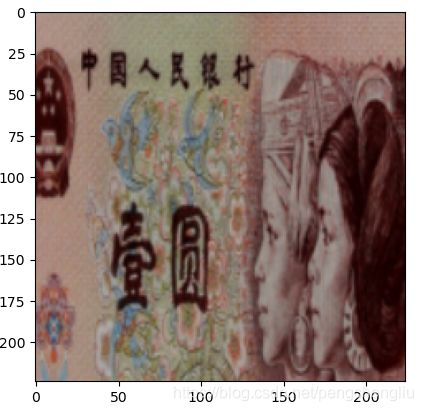
这个图片保存了原有图片的50%的面积。
4. FiveCrop()
5. TenCrop()

FiveCrop()是在图像的左下角、左上角、右上角、右下角以及中心进行裁剪。裁剪出5张图片。【例2】
由于返回的是5张或者10张图片,返回的是一个元组。如果直接使用会报错。【例1】
因此,直接使用是不行的,需要对tuple进行操作。把它变成张量的形式或者PIL image的形式。【例2】
而TenCrop()是在这5张图片的基础上进行镜像得到。代码与FiveCrop()一样。
vertical_flip: True是垂直翻转;False是水平翻转。
例1:

结果:

例2:
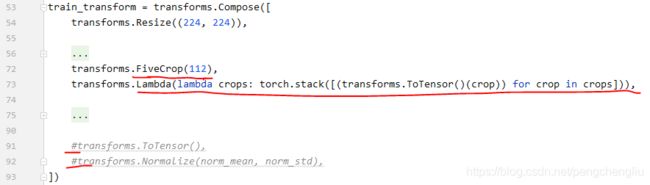
lambda是一个匿名函数。冒号之前的是函数的输入,即“crops”。冒号之后的语句就是函数的返回值。
由于上面进行了ToTenser(),下面就不要进行ToTensor()和Normalize()
由于得到的张量不再是一个4维的张量(batchsize, channel, h, w),而是一个5维的张量(batchsize, ncrops, channel, h, w)。所以,不能用上面的代码进行可视化,而是使用下面的循环对5张图片进行可视化。
结果:
左上角:

右上角:
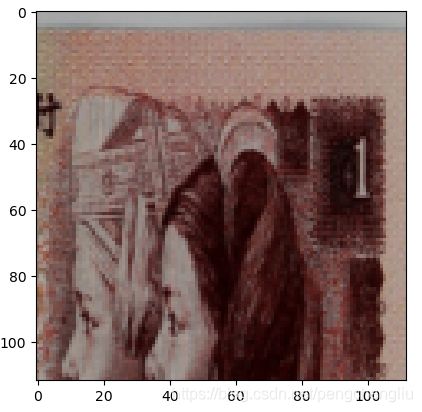
左下角:

右下角:
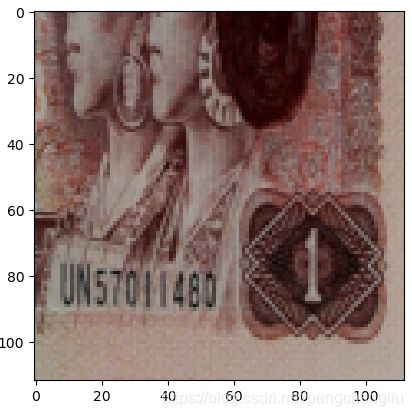
中间:
三、翻转、旋转
1. RandomHorizontalFlip()
2. RandomVerticalFlip()
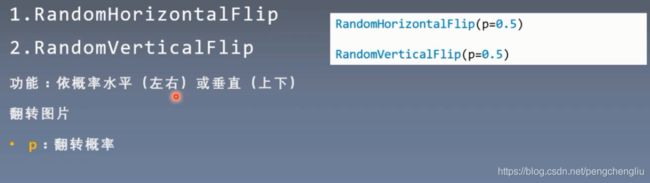
只有一个参数p。每次根据一定的概率执行Flip()操作。
什么是水平翻转:

什么是垂直翻转:

例1:水平翻转

结果:

例2:垂直翻转

结果:
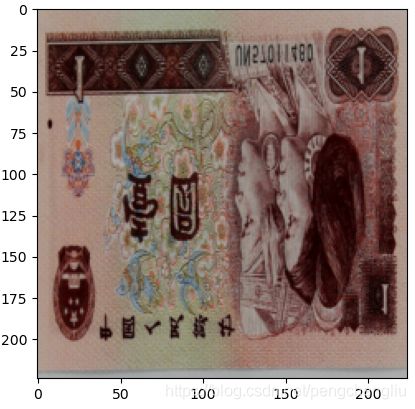
有的垂直翻转, 有的没有翻转。
3. RandomRotation()


degrees:旋转角度。【例1】
expand:图片旋转之后,它的四个角有可能超出原始图片的矩形框。超出的部分信息会丢失。如果想保持图片完整。就要吧expand设置为true。【例2】
比如:

左边是旋转了之后不扩大图片。右边是旋转了之后扩大图片。
使用expand的时候,每次图片大小是不一样的。如果batchsize不是1的话,会报错。因为把数据整理成一个batchdata的时候,因为图片的尺寸不一致。
center:旋转点。默认是中心旋转。也可以设置,比如下面第二张是中心旋转,第三张是以左上角旋转。【例3】

不是中心旋转,是不能通过expand=True找回丢失的信息的。【例4】
例1:旋转-90~90度。


例2:旋转-90~90度,中心扩展

结果:

使用expand的时候,每次图片大小是不一样的。
例3:以左上角为中心点,旋转30度。

结果:

例4:

结果:

发现图片还是会丢失,这是因为expand机制是针对centerRotation这个模式计算需要扩大的长度的。而以左上角为中心,扩大的计算方法不一样。所以会出问题。
四、图像变换
1. Pad()

在学习RandomCrop()的时候,就是首先对图片进行填充,然后随机裁剪。
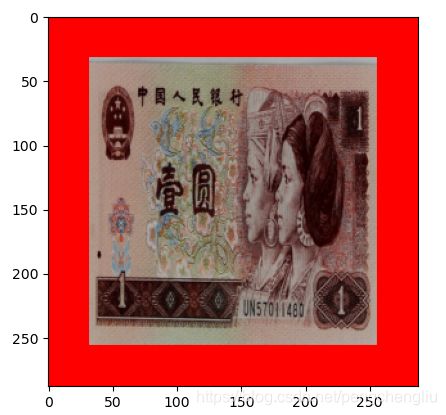
例1:上下左右填充32个像素,填红色。
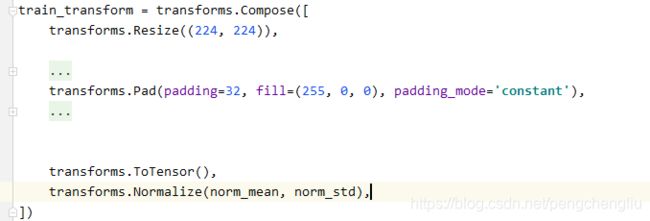
例2:左右填充8像素,上下64像素。颜色红色。
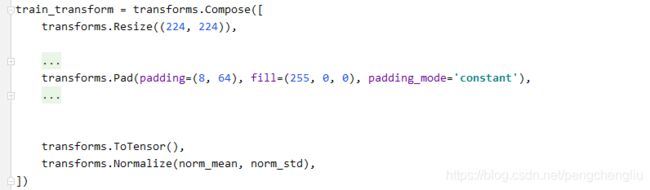
结果:

例3:四周填充不同的像素值。

结果:

例4:对称填充


2. ColorJitter()

这个方法经常用到,尤其是自然图像。由于自然图像在采集过程中,由于光线或者环境不同,色彩通常会有一些偏差。所以要对其进行调整,以弥补这些偏差带来的扰动。
brightness:亮度。如果brights<1,会变暗;如果>1,会更亮一些。【例1】
contrast:对比度。当对比度降低,会发灰。如果对比度升高,白色的地方会更白,灰色的地方会更灰。【例2】
saturation:饱和度。饱和度降低,图像更暗淡。饱和度升高,图像更鲜艳。【例3】
例1:
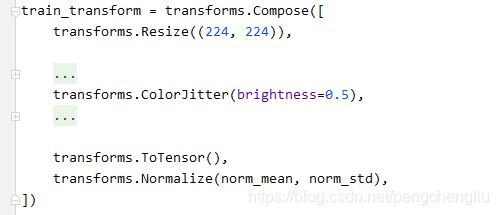
首先去掉注释,查看原始图片:

然后放开注释,执行,看效果:
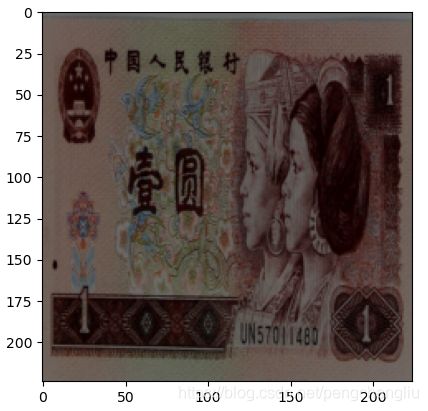
发现变暗了。
例2:对比度

结果:
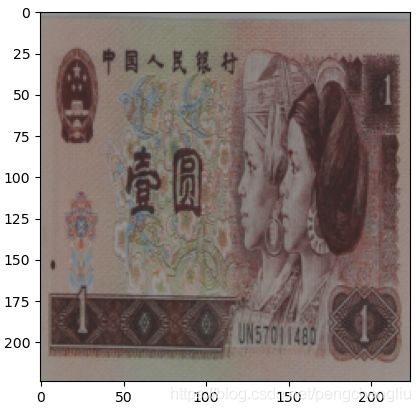
原图为:
例3:饱和度

结果:
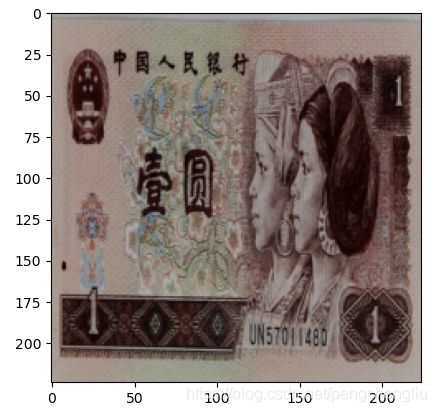
原图:
饱和度降低,图像更暗淡。
例4:色相
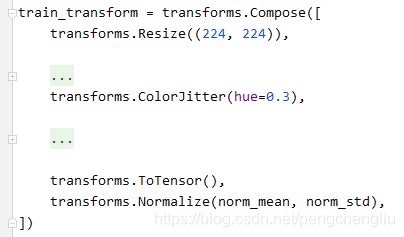
结果:
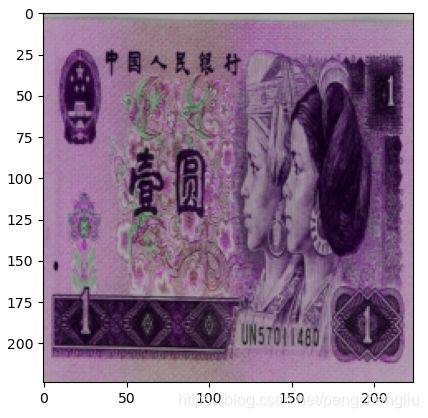
原图:
3. Grayscale()
4. RandomGrayscale()

transforms中提供了两个将彩色图像转换成灰度图像的方法。
RandomGrayscale是依据一定的概率将图片转换成灰度图。Grayscale是RandomGrayscale的一个特例,也就是概率等于1的RandomGrayscale。
我的实验结果是RandomGrayscale()没有num_output_channels这个参数,只有p这个参数。【例2】
例1:
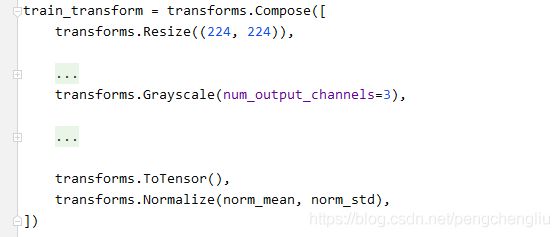
结果:
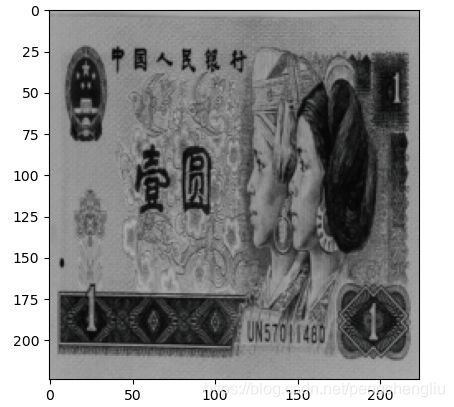
例2:

结果:
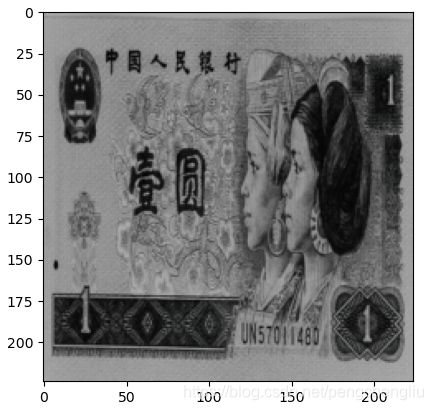
5. RandomAffine()


RandomAffine()方法必须要设置degrees参数。如果不想旋转,就可以把它设置为0.
什么是错切,我们举一个例子:

中间图是进行X轴的错切,可以看到x轴还是平行的;右图是在Y轴进行错切,可以看到y轴还是平行的。
例1:旋转degrees

结果:

可以看到每张图片都是在(-30,30)之间旋转。
例2:平移

结果:

很像RandomCrop()
例3:缩放

结果:

图像还是224*224的,不过进行了缩小。
例4:错切

设置y轴上的错切。

例5:x轴错切

结果:
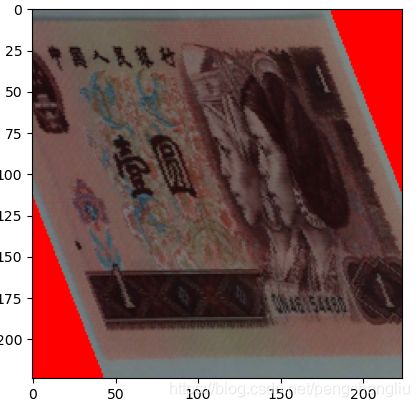
6. RandomErasing()

往往搜集图片的时候,我们的目标会被遮挡住一部分,但是人类的具有联想的功能,即使我们的物体被遮挡一部分,我们根据联想仍然能够识别出图片中的物体。然而我们的模型就没有这么智能了,他没有联想的功能,所以我们需要对训练集进行人为的遮挡,让我们的模型去见过这些被遮挡的图片。
下面举个例子:

对图片进行了随机大小、随机像素值、随机长宽比的遮挡。
scale:要遮挡多大的面积。
ratio:遮挡的长宽比。
value: 遮挡区间的像素值。
p:依据某一概率确定是否遮挡。
inplace:是否执行原位操作。
需要注意的是,随机遮挡接受的是Tensor,它是在一个张量上进行操作。所以在之前要执行一个ToTensor()。后面的ToTensor()和Normalize可以不要。
例1:
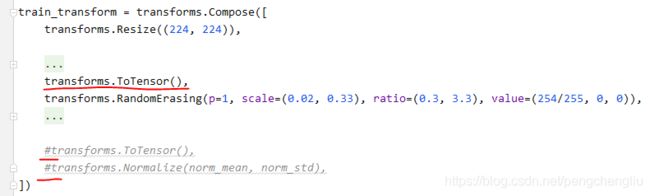
scale=(0.02, 0.33) ration=(0.3, 3.3)是论文推荐的值。因为是Tensor,所以像素值不再是0-255,而是0-1。

例2:如果设置为一个字符串,就会进行随机填充。字符串是个任意的。
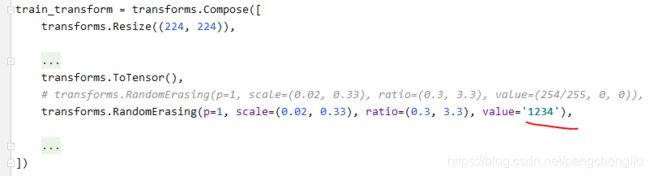
结果:

7. transforms.Lambda()

匿名函数。通常用于几个简单的操作的实现。
冒号前面是输入,冒号后面是表达式。
我们上节课的例子:

参数是crops。
首先从crops中拿出crop。然后把crop转换为Tensor。
拼成一个列表。然后把列表拼接成一个向量。返回。
五、transforms方法的选择操作
transforms对图像的具体操作学习完了。现在学习方法的选择操作。通过选择操作方法,可以使得数据增强方法更加灵活、丰富、多样。

1. transforms.RandomChoice()
在一系列方法中随机挑选一个。【例1】
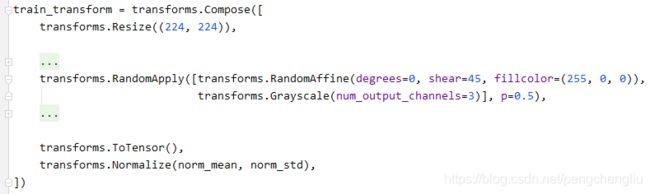
2. transforms.RandomApply()
每次依概率执行还是不执行,执行就执行一组。【例2】
3. transforms.RandomOrder()
打乱顺序再执行。【例3】
例1:图像要么水平翻转要么垂直翻转。

结果:
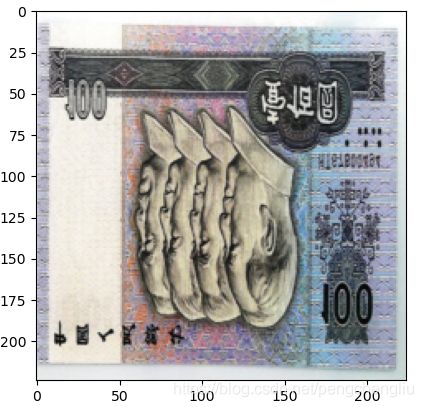
例2:
结果:
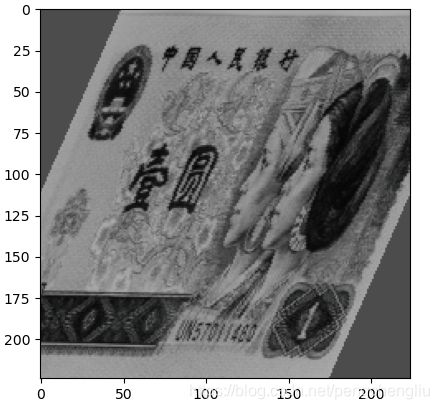
在x轴错切,并变成灰度图。
例3:
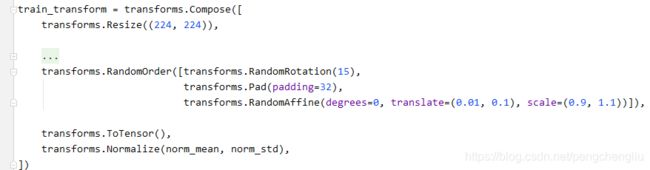
结果:
旋转、填充、仿射变换,随机打乱顺序执行。
