WHENet: Real-time Fine-Grained Estimation for Wide Range Head Pose
WHENet:大范围头部姿势的实时细粒度估计
Yijun Zhou [email protected] James Gregson [email protected] IC Lab, Huawei Technologies Canada
摘要
我们提出了一个端到端的头部姿势估计网络,用于从单个RGB图像预测整个头部雅司病的欧拉角。现有的方法在正面视图中表现良好,但从所有角度来看,很少有目标头部姿势。这在自动驾驶和零售业中都有应用。我们的网络建立在多损失方法的基础上,改变了损失函数和适应大范围估计的训练策略。
此外,我们首次从当前的全景数据集中提取前视图的地面真值标签。由此产生的宽头部姿势估计网络(WHENet)是适用于所有头部雅司病(因此宽)的第一种细粒度现代方法,但也符合或优于最先进的正面头部姿势估计方法。
我们的网络结构紧凑,适用于移动设备和应用。代码将在以下位置提供:https://github.com/Ascend-Research/HeadPoseEstimation-WHENet.
1导言
头部姿势估计(HPE)是从图像或视频中估计头部方向的任务(见图2(a)),已经进行了大量研究。HPE的应用范围很广,包括(但不限于)虚拟和增强现实[25]、驾驶员辅助、无标记运动捕捉[10]或作为凝视估计的一个组成部分[24],因为凝视和头部姿势紧密相连[21]。
[24]中详细描述了HPE的重要性。它们描述了广泛的社会互动,如相互注视、驾驶员-行人和驾驶员-驾驶员互动。在为谈话对象提供视觉线索、指示演讲者/听者角色转换的适当时间以及表示同意时,这一点也很重要[24]。对于自然与人互动的系统来说,对头部姿势保持敏感是很重要的。
大多数HPE方法的目标是从正面到侧面的姿势,因为应用程序丰富,面部特征丰富,训练数据集广泛可用。然而,覆盖全方位在许多领域都很有用,包括驾驶员辅助[26]、运动捕捉,以及为广告和零售业生成注意力地图[37]。
此外,尽管[33,35]等方法表现良好,但对于移动和嵌入式平台来说,它们可能是令人望而却步的大型网络。这在自动驾驶中尤其重要,因为许多子系统必须同时运行。
基于这些标准,我们开发了宽头姿势估计网络(WHENet),该网络使用移动友好的体系结构,将头姿势估计扩展到雅司病的所有范围(因此很宽)。为此,我们做出以下贡献:。

图1:WHENet全方位头部姿势估计网络(中心)通过将效率网[40]主干与俯仰、偏航和横摇的分类和回归损失相结合来定义[33]。一种新的包裹损耗使网络在大范围内保持稳定。通过一种新的再处理程序,使用[18](左下)重新调整的前视图对该网络进行训练,使WHENet能够从前视图预测头部姿势,以及使用移动友好型模型预测严重遮挡、时尚配饰和不利照明(右)的头部。尽管如此,WHENet仍然比现有的仅限于正面或正面视图的最先进方法准确或更准确。一些图片来自[51]&[41]
-
•我们引入了包裹损失,显著提高了全范围HPE前视图的偏航精度。
-
•我们详细介绍了CMU全景数据集的自动标记过程[18],允许其用于全范围HPE的培训和验证数据。
-
•我们将改进后的网络(WHENet)扩展到yaws的全范围,在全范围HPE中实现最先进的性能,在窄范围HPE中达到最先进性能的1.8%以内,尽管已经接受过另一项任务的培训。
-
•我们证明,对HopeNet[33]的简单修改可以实现比原始网络和5%的改进− AFLW2000[51]和BIWI[12]数据集中RGB图像的窄范围HPE比目前最先进的FSANet[48]提高了13%。
2背景及相关工作
在过去的25年里,人们对头部姿势估计进行了积极的研究。[24]中对截至2008年的方法进行了详细的调查,我们对早期方法的大部分讨论都是在他们的工作之后进行的。由于研究活动的广度和我们对单目RGB图像HPE的目标应用,我们将多视角或主动传感方法排除在本综述之外。
经典的方法包括模板匹配和级联检测器。模板匹配-将输入图像与一组标记的模板进行比较,并根据附近的匹配指定姿势[27,36]。他们可能很难区分身份和姿势的相似性[24]。级联检测器训练不同的检测器,也可以为每个(离散化的)姿势定位头部。挑战包括预测分辨率和多个探测器点火时的分辨率[24]。
几何模型和可变形模型是类似的方法。几何模型使用来自输入图像的特征,例如面部关键点,并使用静态模板分析确定匹配的头部姿势[7]。它们的复杂性主要在于检测特征,这本身就是一个经过充分研究的问题,参见[16,39]和[42]调查。可变形模型类似,但允许模板变形以匹配特定主题的头部特征。
姿势或其他信息来自变形模型[8,46,49,51]。
回归和分类方法是大多数其他方法的超集或组成部分。回归方法使用或拟合数学模型,根据标记的训练数据直接预测姿势。回归器的公式范围很广,包括主成分分析[38,52]和神经网络[23,33]等。相比之下,分类方法通过离散化的姿势集预测姿势。预测分辨率往往较低,通常小于10-12个离散姿势。方法包括决策树和随机森林[3,11],多任务学习[44,45]和神经网络[23,33]。我们的网络与[33]中使用分类和回归目标的多重损失框架最为相似。其他作品通过在多个尺度上进行分类和回归目标训练,采用软阶段回归[47,48]。
多任务方法将头部姿势估计问题与其他面部分析问题结合起来。研究[9,29,30,50]表明,同时进行与学习相关的任务比单独进行培训任务能取得更好的绩效。例如,在[29,30]中,人脸检测和姿势回归是联合训练的。
全范围方法远不如窄范围方法常见,因为HPE的大多数现有数据集都集中在从正面到正面的视图上。最近的方法包括[15,31,32],分类将其放入粗粒度的容器/类中,以确定偏航。与我们的方法不同,在[15,31,32]中没有预测俯仰和滚动。
面部姿势的数据集包括BIWI[12]、AFLW2000[51]和300W-LP[51]。AFLW2000和300W-LP都使用了一个可变形的模型,适用于姿态变化较大的人脸,并报告欧拉角。300W-LP生成额外的合成视图以放大数据集。
最近,UMD Faces[2]和Pandora[4]数据集提供了一系列数据标签,包括头部姿势。我们的应用程序的一个缺点是,它们不能覆盖所有的头部姿势,只能覆盖从正面到侧面的视图。
对我们的方法非常重要的是CMU全景数据集[18]。它从覆盖整个半球的大量经过校准的摄像机中捕捉对象,并提供3D面部地标。使用这些数据,我们能够从近正面视图估计头部姿势,并使用此姿势标记非正面视点。通过这样做,我们涵盖了所有与相机相关的姿势,允许我们的方法使用前视图进行训练。这将在第4节中进一步讨论。
3.我们的方法
我们的网络设计源自Ruiz等人[33]的多损耗框架。他们将一个卷积主干与独立的完全连接的网络相结合,这些网络将俯仰、偏航和滚转分为3类◦ 使用具有交叉熵损失的softmax的垃圾箱。均方误差(MSE)回归损失也适用于地面真值标签和softmax输出的预期值之间。对这两个损失进行加权,以产生每个角度的最终训练目标。
在[33]中,鲁伊斯等人。我们认为,由于softmax和交叉熵损失,这种损失组合提供了最终的网络稳健性和稳定性,同时仍然通过回归损失提供了细粒度的监督和输出。
我们采用了[33]中的整体框架,但对两个损失函数进行了替换,以使该方法适用于全范围。据我们所知,我们是第一个这样做的人。偏航预测分为120 3个部分◦ 覆盖各种雅司病的垃圾箱![]() 。俯仰和侧倾预测都是根据66 3进行的◦ 涵盖范围
。俯仰和侧倾预测都是根据66 3进行的◦ 涵盖范围![]() 的箱子,尽管只有[− 90,90]最终被使用。俯仰、偏航和横摇的回归和分类损失通过以下方式组合:
的箱子,尽管只有[− 90,90]最终被使用。俯仰、偏航和横摇的回归和分类损失通过以下方式组合:
![]()
这里L cls是分类损失,L reg是回归损失,而α和β权衡了一个对另一个的影响。
我们测试了不同的分类损失,并为L cls选择了具有二元交叉熵的sigmoid激活。这与[33]有所不同,显示了全量程任务的精度略有提高,但主要是为了再现性。
如[33]中所述,我们通过应用softmax来获得箱子概率,并对每个偏航、俯仰和横滚的结果进行预期,从而从箱子登录中预测输出角度:

这里PI是第i个箱子的概率,3是箱子宽度(度),N是120(偏航)或66(俯仰和横滚)的箱子计数。减去的项将bin指数转移到bin中心。
在[33]中,均方误差(MSE)损失用于回归,这对于目标雅司病的有限范围是足够的。然而,在全程任务中,这种缺失会导致绝对雅司病超过![]() 的受试者行为不稳定。图2(b)显示了这一点,这是因为
的受试者行为不稳定。图2(b)显示了这一点,这是因为![]() 在同一姿势下的角度大不相同。
在同一姿势下的角度大不相同。
为了防止这种情况,我们定义了一种可避免这种行为的包裹损失(见图2(b))。
它不是直接惩罚角度,而是惩罚将每个偏航预测与其相应的数据集注释对齐所需的最小旋转角度:

图2(b)绘制了目标值![]() 的损失函数
的损失函数![]() ,并与MSE损失进行比较。在
,并与MSE损失进行比较。在![]() 范围内,两者相同,但角度不同。当它们分开时,MSE迅速增加,但随着姿势变得更相似,包裹损失减少。包裹损失是平滑的,除了在180度的尖角处,其他地方都可以微分◦ 来自地面的真相。这确实使网络训练变得更加困难,我们怀疑这是由于偏航中最大误差处出现的尖峰。
范围内,两者相同,但角度不同。当它们分开时,MSE迅速增加,但随着姿势变得更相似,包裹损失减少。包裹损失是平滑的,除了在180度的尖角处,其他地方都可以微分◦ 来自地面的真相。这确实使网络训练变得更加困难,我们怀疑这是由于偏航中最大误差处出现的尖峰。
包裹损失是该方法在前视图中性能的关键,如图2(b)所示。MSE训练的网络预测完全不正确的头部姿势,而我们的预测与图像一致。图3将误差绘制为角度的函数,并显示大偏航时的平均误差减少了50%以上。
在[29,33]中,AlexNet和ResNet50被用作主干。对于高度专业化的任务,如HPE,这些都是相当大的网络。由于我们的方法的重点是对移动设备友好,因此我们选择了更轻的主干:Ef ficientnet-B0[40]。Ef-FIENTNET-B0是Ef-FIENTNET系列的基准模型,它包含反向剩余块(来自MobileNet V2[34]),以减少参数数量,同时添加跳过连接。
这种模型尺寸的减小对于低功耗嵌入式设备非常重要,因为头部姿势估计可能只是更大系统的一个组成部分。我们已经成功地将一个初步实现移植到一个低功耗的嵌入式平台上,在这个平台上,我们可以看到推理速度接近60fps。

图2:头部姿势(a)由指定方向上的俯仰(红色轴)、偏航(绿色轴)和滚动(蓝色轴)角度参数化。我们提出的包裹损失函数(b-左)避免了对大于180的预测进行过度惩罚◦ 从true开始,姿势相似,但MSE会产生巨大的损失值。这改善了当受试者面对远离摄像机(b-右)的情况下的预测,其中使用MSE训练的网络的误差接近180◦ 为了偏航。注:x(红色)轴应与受试者的左耳对齐。在(c)中,我们计算了虚拟摄像机的外部定向,以提供正面视图,以及从CMU全景数据集中提取欧拉角的真实外部定向[18]。这使我们能够为全范围HPE任务自动标记数以万计的前视图图像。我们相信我们是第一个这样做的人。
4数据集和训练
目前,HPE的主要数据集为300W-LP[51]、AFLW2000[51]和BIWI[12]。AFLW2000和300W-LP都使用3D密集面部对齐(3DDFA)将可变形的3D模型转换为2D输入图像,并提供准确的头部姿势作为地面真实感。300W-LP额外生成合成视图,大大增加了图像数量。
BIWI数据集由Kinect采集的视频序列组成。受试者移动头部,试图跨越从正面位置观察到的所有可能角度。姿势注释是根据深度信息创建的。
我们遵循[33]的惯例,保留AFLW2000[51]和BIWI[12]用于测试,同时使用300W-LP[51]进行培训。
不幸的是,上面提到的所有数据集都没有提供(绝对)yaws大于100的示例◦ . 为了克服这个问题,我们生成了一个新的数据集,将300W-LP与CMU全景数据集的数据相结合[18]。CMU全景数据集从大约30个高清摄像头中捕获了受试者在圆顶内执行任务的视频。
全景数据集包括3D面部地标和校准的相机外部和内部,但不包括头部姿势信息。我们使用地标和摄像机标定来定位和裁剪受试者头部的图像,并计算相应的摄像机相对头部姿态角。我们相信我们是第一个在这种情况下使用该数据集的公司。
图1显示了数据集中的一个框架。全景数据集的背景变化非常小,因此不能单独用于训练网络,因为网络无法学习将主题与一般背景区分开来的特征。这就是将其与300W-LP相结合的动机,300W-LP用于![]() 中的雅司病,而全景数据集提供的数据大多不在此范围内。
中的雅司病,而全景数据集提供的数据大多不在此范围内。
处理CMU全景数据集。为了从全景数据集中计算相机相对头部姿势的角度,我们使用以下步骤,如图2(c)所示。我们首先定义一组参考3D面部地标![]() ,与使用通用头部模型的全景数据集面部关键点注释相匹配,除了嘈杂的下颌线关键点。然后放置一个带有内部和外部
,与使用通用头部模型的全景数据集面部关键点注释相匹配,除了嘈杂的下颌线关键点。然后放置一个带有内部和外部![]() 的参考摄像机,以获得
的参考摄像机,以获得![]() 的完美正面视图(偏航=俯仰=滚动=0)。对于每一帧中的每一个主题,我们使用[17]估计x re f和全景数据集提供的真实关键点x real之间的刚性变换R。然后,我们为虚拟相机
的完美正面视图(偏航=俯仰=滚动=0)。对于每一帧中的每一个主题,我们使用[17]估计x re f和全景数据集提供的真实关键点x real之间的刚性变换R。然后,我们为虚拟相机
![]()
构造新的外部对象。当主体位于穹顶内时,这提供了主体(名义上)的正面视图。使用panop-tic数据集中已知的真实摄像机外部特征E real和E virt,我们恢复了虚拟摄像机外部特征和每个真实摄像机之间的刚性变换![]() 。最后,我们从T中提取俯仰-偏航-滚转(x-y-z)顺序的欧拉角,镜像偏航和滚转,以匹配数据集中的旋转约定。刚性变换有一个平移组件,但不需要确定头部相对于相机光轴的方向。
。最后,我们从T中提取俯仰-偏航-滚转(x-y-z)顺序的欧拉角,镜像偏航和滚转,以匹配数据集中的旋转约定。刚性变换有一个平移组件,但不需要确定头部相对于相机光轴的方向。
在这个过程中使用合成参考和虚拟摄像机可以确保我们有一个一致的自动标记方法。与手动选择正面摄像头并注释相应的欧拉角相比,它还大大减少了噪音。
为了裁剪图像,我们将主体头部周围的一组球形点定义为头盔,并将其投影到每个视图中,以确定裁剪区域。受明等人[35]的启发,我们在头部边界框中留了一个空白,这样网络就可以学会区分前景和背景。我们遵循[35]的方法,使用K=0.5表示300W-LP的数据,并将CMU数据的头盔半径调整为21cm。
惠内特的训练分为两个阶段。我们首先训练一个窄范围模型WHENet-V,其偏航、俯仰和横滚的预测范围在![]() 之间。我们使用学习率为1e-5的ADAM优化器在300W-LP[51]数据集上训练这个窄范围网络。然后,使用我们结合300W-LP和CMU全景数据集的全范围数据集,从WHENet-V权重开始训练具有120个偏航仓的全范围WHENet。
之间。我们使用学习率为1e-5的ADAM优化器在300W-LP[51]数据集上训练这个窄范围网络。然后,使用我们结合300W-LP和CMU全景数据集的全范围数据集,从WHENet-V权重开始训练具有120个偏航仓的全范围WHENet。
我们在这一步中使用相同的优化器和学习率。由于CMU数据几乎没有背景变化,这种两阶段方法有助于全范围网络更好地收敛并学习更多有用的特征。在训练过程中,图像随机减少15倍,以提高鲁棒性。
300W-LP和全景数据集的训练数据使用量几乎相等,前者提供窄范围样本,后者主要处理宽范围样本。
少量全景数据也被用于在偏航=0附近的窄范围图像直方图中调平倾斜。
5结果与讨论
对于本节中的大范围结果,我们将绝对包裹误差(AWE)定义为
![]()
,它可以正确处理雅司病的包裹。
我们还将平均AWE(MAWE)定义为AWE的算术平均值。对于下面的结果,我们使用![]() 。
。
根据我们的烧蚀情况,![]() 用于WHENet和
用于WHENet和
![]()
用于WHENet-V。超参数详细信息可在我们的补充文件中找到。
表1总结了WHENet和WHENet-V的主要结果。我们比较了八种窄量程和两种全量程方法,并报告了输出范围、参数数量、BIWI上的平均误差[12]、AFLW-2000[51]、两者的平均值(表示泛化)和报告的全量程MAE(如适用)。WHENet和WHENet-V在300W-LP[51]或我们的组合数据集上接受培训,而不是按照标准惯例在AFLW2000或BIWI数据集上接受培训。我们首先讨论全方位网络WHENet,因为这是我们的主要应用。
全范围的WHENet结果和比较如表1所示。在比较的三种全方位方法中,WHENet是唯一也能预测纵摇和横摇的方法。
由于Raza等人[31]和Rehder等人[32]都只预测雅司病(无俯仰和滚转),并且在非公开数据集上预测雅司病,因此很难客观地进行比较。对于[31],没有报告MAE,因此我们报告了雅司病及其仓宽均匀分布的最低可能误差(即,如果他们的方法执行完美,结果)。虽然由于缺乏一致的测试数据,这些结果应被视为定性的,但WHENet仍显示出31%的改善。后一点是我们在这项工作中试图通过公开CMU全景数据集[18]的数据集处理代码来解决的。
此外,除WHENet-V外,全量程WHENet在BIWI上的平均误差最低,在AFLW2000上的平均误差第二低,总体平均误差第二低,缺失第一名0.084◦ (1.8%)至FSANet[48]。这是非常重要的,因为全量程WHENet没有专门针对窄量程任务进行培训,但仍然是最先进的,或与FSANet[48]竞争非常激烈,FSANet是一个非常复杂的网络。在处理全范围输入时,WHENet比FSANet有更大的能力,但其准确性却非常低。
图2(a)显示了使用WHENet生成的姿势预测,以跟踪在整个偏航旋转过程中旋转的对象。WHENet在整个过程中都会产生连贯的预测,即使脸完全不存在。实现这一点的关键是我们的包裹损失功能,它显著改善了前视图。如果没有包装的损失预测是比较合理的,通常接近180◦ 从图2(b)所示的真实姿势开始。这一改进是由我们对CMU全景数据集[18]的注释过程实现的,它允许我们自动为成千上万的前视图生成标签,以应对这一挑战。
表2中列出了窄范围结果和比较。Dlib[19]、开普勒[20]和范[6]都是基于地标的方法。3DDFA[51]使用CNN将3D密集模型嵌入RGB图像。Hopenet[33]和FSANet[48]是两种无里程碑意义的方法,它们都探索了将连续问题(头部姿势)分为不同类别/阶段的可能性。如表2所示,WHENet-V在BIWI[12]和AFLW2000[51]上都达到了最先进的准确度,分别比之前最先进的FSANet[48]高出了![]() (13.1%)和
(13.1%)和![]() (4.7%),总体改善了0.38%◦ (8.4%)对这两个数据集的总体影响。它在每一项指标上都获得了第一名。有趣的是,WHENet-V在这些数据集上比HopeNet[33]分别提高了29%和21%,尽管其网络结构非常相似。
(4.7%),总体改善了0.38%◦ (8.4%)对这两个数据集的总体影响。它在每一项指标上都获得了第一名。有趣的是,WHENet-V在这些数据集上比HopeNet[33]分别提高了29%和21%,尽管其网络结构非常相似。
主干和损失函数变化的消融研究如图3和表3所示。图3绘制了包裹回归损失(WHENet)和MSE损失(WHENet MSE)之间不同角度间隔的平均误差。当使用MSE损失时,极端姿势(接近-180/180度)的偏航平均误差达到35度。通过引入包裹损耗,这些角度的误差减少了50%以上,并且与中等或低雅司病的误差更加一致。在HPE方法中,高俯仰和横滚误差是典型的,正如[35]中所示,yaws接近![]() ,我们认为这是由于数据标记中的万向节锁定。此外,定量结果比较见表3。WHENet CE使用交叉熵损失进行分类,使用包裹回归损失进行回归。
,我们认为这是由于数据标记中的万向节锁定。此外,定量结果比较见表3。WHENet CE使用交叉熵损失进行分类,使用包裹回归损失进行回归。
WHENet MSE使用二进制交叉熵损失进行分类,MSE损失进行再分类。WHENet使用二进制交叉熵损失进行分类,使用包裹回归损失进行回归。我们可以在大范围数据集(combine)中看到,WHENet在偏航方面具有优越的性能,这证实了我们在图3中的观察结果。虽然与其他两种损耗设置相比,WHENet在窄范围测试中表现出了一些性能,但我们主要关注的是大范围预测,在大范围预测中,我们发现误差显著改善。我们认为,通过调整CMU数据集注释中使用的模板关键点,而不是使用固定的模板,可以提高性能,但这要留待将来的工作。
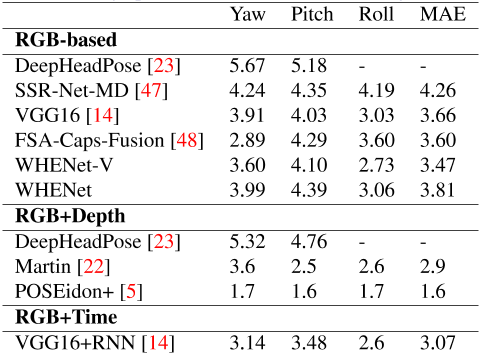
补充资料提供了关于亚参数α和β的额外消融研究,以及分辨率的影响,以及与我们目标应用范围之外的基于视频和深度的方法的相对比较。
表1:结果摘要:“Aggr”。MAE:BIWI和AFLW2000总体结果的平均值全MWAE”:全范围结果。First/only,second,-:未报告
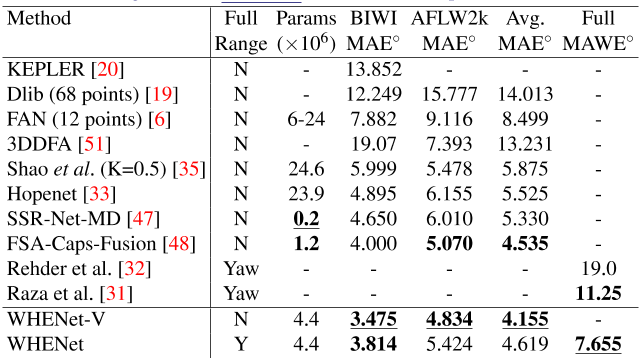
表2:BIWI[12](左)和AFLW2000[51](右)数据集与最新技术的比较。最佳(粗体下划线)和次优(粗体)结果将突出显示。

图3:WHENet和WHENet(MSE)混合数据集上的误差直方图,高偏航时的误差随着我们提出的包裹损失显著减少。

表3:不同损耗设置的结果比较。Combine表示CMU Panopic和300W-LP的组合数据集

6结论和今后的工作
在本文中,我们提出了WHENet,一种新的HPE方法,可以在整个360度雅司病范围内估计头部姿势。这是通过仔细选择包裹损失函数以及为CMU全景数据集开发自动标记方法来实现的[18]。我们相信,我们是第一个将该数据集应用于头部姿势估计的特定任务的人。WHENet达到或超过了最先进的方法的性能,这些方法针对正面HPE的特定任务进行了调整,尽管已经接受了各种雅司病的培训。
我们不了解具有类似能力和准确性的竞争方法。
在未来,我们希望通过进一步缩小网络规模来扩展这项工作。降低输入图像分辨率有可能降低内存使用率,并允许使用较少功能的较浅网络。这将进一步提高网络的速度和规模。
另一个有趣的方法是修改头部姿势的表示。欧拉角最小且可解释,但有框架锁的缺点。AFLW2000和BIWI等现有数据集的俯仰-偏航-滚转-旋转顺序强调了在±90°左右的偏航时的这种影响◦ 俯仰和滚动有效地相互抵消。我们认为,这会导致图3中所示的姿势附近出现相对较高的俯仰和侧倾误差,这也可以在邵等人[35]等方法中看到。将数据重新标记为偏航-俯仰-滚转顺序可能会减少这种情况。类似地,轴角、指数映射或四元数等其他旋转表示也可能有所帮助,但由于分类网络的存在,使体系结构适应其他旋转表示可能非常重要。
7致谢
我们感谢陈少华和谭曼娜·萨杜的富有洞察力的讨论。我们还感谢华为技术部的詹旭、邓鹏、马睿、温若成、王强等同事对该项目的支持,以及匿名审稿人,他们的评论帮助改进了论文。
参考文献
[1] Shabnam Abtahi, Mona Omidyeganeh, Shervin Shirmohammadi, and Behnoosh Hariri. Yawdd: A yawning detection dataset. In Proceedings of the 5th ACM Multimedia Systems Conference , pages 24–28. ACM, 2014.
[2] Ankan Bansal, Anirudh Nanduri, Carlos D Castillo, Rajeev Ranjan, and Rama Chel- lappa. Umdfaces: An annotated face dataset for training deep networks. In 2017 IEEE International Joint Conference on Biometrics (IJCB) , pages 464–473. IEEE, 2017.
[3] Ben Benfold and Ian D Reid. Colour invariant head pose classification in low resolution video. In BMVC , pages 1–10, 2008.
[4] Guido Borghi, Marco Venturelli, Roberto Vezzani, and Rita Cucchiara. Poseidon: Face-from-depth for driver pose estimation. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages 5494–5503. IEEE, 2017.
[5] Guido Borghi, Matteo Fabbri, Roberto Vezzani, Rita Cucchiara, et al. Face-from-depth for head pose estimation on depth images. IEEE transactions on pattern analysis and machine intelligence , 2018.
[6] Adrian Bulat and Georgios Tzimiropoulos. How far are we from solving the 2d & 3d face alignment problem?(and a dataset of 230,000 3d facial landmarks). In Proceedings of the IEEE International Conference on Computer Vision , pages 1021–1030, 2017.
[7] Patrick Burger, Martin Rothbucher, and Klaus Diepold. Self-initializing head pose estimation with a 2d monocular usb camera. Technical report, Lehrstuhl für Datenver- arbeitung, 2014.
[8] Qin Cai, David Gallup, Cha Zhang, and Zhengyou Zhang. 3d deformable face tracking with a commodity depth camera. In European conference on computer vision , pages 229–242. Springer, 2010.
[9] Dong Chen, Shaoqing Ren, Yichen Wei, Xudong Cao, and Jian Sun. Joint cascade face detection and alignment. In European conference on computer vision , pages 109–122. Springer, 2014.
[10] Márcio Cerqueira de Farias Macedo, Antônio Lopes Apolinário, and Antonio Carlos dos Santos Souza. A robust real-time face tracking using head pose estimation for a markerless ar system. In 2013 XV Symposium on Virtual and Augmented Reality , pages 224–227. IEEE, 2013.
[11] Gabriele Fanelli, Juergen Gall, and Luc Van Gool. Real time head pose estimation with random regression forests. In CVPR 2011 , pages 617–624. IEEE, 2011.
[12] Gabriele Fanelli, Matthias Dantone, Juergen Gall, Andrea Fossati, and Luc Van Gool. Random forests for real time 3d face analysis. Int. J. Comput. Vision , 101(3):437–458, February 2013.
[13] Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset. The International Journal of Robotics Research , 32(11): 1231–1237, 2013.
[14] Jinwei Gu, Xiaodong Yang, Shalini De Mello, and Jan Kautz. Dynamic facial analy- sis: From bayesian filtering to recurrent neural network. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 1548–1557, 2017.
[15] DuYeong Heo, Jae Yeal Nam, and Byoung Chul Ko. Estimation of pedestrian pose orientation using soft target training based on teacher–student framework. Sensors , 19 (5):1147, 2019.
[16] Rainer Herpers, Markus Michaelis, K-H Lichtenauer, and Gerald Sommer. Edge and keypoint detection in facial regions. In Proceedings of the Second International Con- ference on Automatic Face and Gesture Recognition , pages 212–217. IEEE, 1996.
[17] Berthold KP Horn, Hugh M Hilden, and Shahriar Negahdaripour. Closed-form solution of absolute orientation using orthonormal matrices. JOSA A , 5(7):1127–1135, 1988.
[18] Hanbyul Joo, Tomas Simon, Xulong Li, Hao Liu, Lei Tan, Lin Gui, Sean Banerjee, Timothy Godisart, Bart Nabbe, Iain Matthews, et al. Panoptic studio: A massively multiview system for social interaction capture. IEEE transactions on pattern analysis and machine intelligence , 41(1):190–204, 2017.
[19] Vahid Kazemi and Josephine Sullivan. One millisecond face alignment with an ensem- ble of regression trees. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 1867–1874, 2014.
[20] Amit Kumar, Azadeh Alavi, and Rama Chellappa. Kepler: Keypoint and pose estima- tion of unconstrained faces by learning efficient h-cnn regressors. In 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017) , pages 258–265. IEEE, 2017.
[21] Stephen RH Langton, Helen Honeyman, and Emma Tessler. The influence of head contour and nose angle on the perception of eye-gaze direction. Perception & psy- chophysics , 66(5):752–771, 2004.
[22] Manuel Martin, Florian Van De Camp, and Rainer Stiefelhagen. Real time head model creation and head pose estimation on consumer depth cameras. In 2014 2nd Interna- tional Conference on 3D Vision , volume 1, pages 641–648. IEEE, 2014.
[23] Sankha S Mukherjee and Neil Martin Robertson. Deep head pose: Gaze-direction estimation in multimodal video. IEEE Transactions on Multimedia , 17(11):2094–2107, 2015.
[24] Erik Murphy-Chutorian and Mohan Manubhai Trivedi. Head pose estimation in com- puter vision: A survey. IEEE transactions on pattern analysis and machine intelli- gence , 31(4):607–626, 2008.
[25] Erik Murphy-Chutorian and Mohan Manubhai Trivedi. Head pose estimation and aug- mented reality tracking: An integrated system and evaluation for monitoring driver awareness. IEEE Transactions on intelligent transportation systems , 11(2):300–311, 2010.
[26] Erik Murphy-Chutorian, Anup Doshi, and Mohan Manubhai Trivedi. Head pose esti- mation for driver assistance systems: A robust algorithm and experimental evaluation. In 2007 IEEE Intelligent Transportation Systems Conference , pages 709–714. IEEE, 2007.
[27] Jeffrey Ng and Shaogang Gong. Composite support vector machines for detection of faces across views and pose estimation. Image and Vision Computing , 20(5-6):359– 368, 2002.
[28] Daniil Osokin. Real-time 2d multi-person pose estimation on cpu: Lightweight open- pose. arXiv preprint arXiv:1811.12004 , 2018.
[29] Rajeev Ranjan, Vishal M Patel, and Rama Chellappa. Hyperface: A deep multi-task learning framework for face detection, landmark localization, pose estimation, and gen- der recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence , 41 (1):121–135, 2017.
[30] Rajeev Ranjan, Swami Sankaranarayanan, Carlos D Castillo, and Rama Chellappa. An all-in-one convolutional neural network for face analysis. In 2017 12th IEEE Interna- tional Conference on Automatic Face & Gesture Recognition (FG 2017) , pages 17–24. IEEE, 2017.
[31] Mudassar Raza, Zonghai Chen, Saeed-Ur Rehman, Peng Wang, and Peng Bao. Ap- pearance based pedestriansâĂŹ head pose and body orientation estimation using deep learning. Neurocomputing , 272:647–659, 2018.
[32] Eike Rehder, Horst Kloeden, and Christoph Stiller. Head detection and orientation estimation for pedestrian safety. In 17th International IEEE Conference on Intelligent Transportation Systems (ITSC) , pages 2292–2297. IEEE, 2014.
[33] Nataniel Ruiz, Eunji Chong, and James M Rehg. Fine-grained head pose estimation without keypoints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops , pages 2074–2083, 2018.
[34] Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages 4510–4520, 2018.
[35] Mingzhen Shao, Zhun Sun, Mete Ozay, and Takayuki Okatani. Improving head pose estimation with a combined loss and bounding box margin adjustment. arXiv preprint arXiv:1905.08609 , 2019.
[36] Jamie Sherrah, Shaogang Gong, and Eng-Jon Ong. Understanding pose discrimination in similarity space. In BMVC , pages 1–10, 1999.
[37] Teera Siriteerakul. Advance in head pose estimation from low resolution images: A review. International Journal of Computer Science Issues , 9(2):1, 2012.
[38] Sujith Srinivasan and Kim L Boyer. Head pose estimation using view based eigenspaces. In Object recognition supported by user interaction for service robots , volume 4, pages 302–305. IEEE, 2002.
[39] Yi Sun, Xiaogang Wang, and Xiaoou Tang. Deep convolutional network cascade for facial point detection. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 3476–3483, 2013.
[40] Mingxing Tan and Quoc V Le. Efficientnet: Rethinking model scaling for convolu- tional neural networks. arXiv preprint arXiv:1905.11946 , 2019.
[41] Tuan-Hung Vu, Anton Osokin, and Ivan Laptev. Context-aware cnns for person head detection. In Proceedings of the IEEE International Conference on Computer Vision , pages 2893–2901, 2015.
[42] Nannan Wang, Xinbo Gao, Dacheng Tao, Heng Yang, and Xuelong Li. Facial feature point detection: A comprehensive survey. Neurocomputing , 275:50–65, 2018.
[43] Jiahong Wu, He Zheng, Bo Zhao, Yixin Li, Baoming Yan, Rui Liang, Wenjia Wang, Shipei Zhou, Guosen Lin, Yanwei Fu, et al. Ai challenger: a large-scale dataset for going deeper in image understanding. arXiv preprint arXiv:1711.06475 , 2017.
[44] Yan Yan, Elisa Ricci, Ramanathan Subramanian, Oswald Lanz, and Nicu Sebe. No matter where you are: Flexible graph-guided multi-task learning for multi-view head pose classification under target motion. In Proceedings of the IEEE international con- ference on computer vision , pages 1177–1184, 2013.
[45] Yan Yan, Elisa Ricci, Ramanathan Subramanian, Gaowen Liu, Oswald Lanz, and Nicu Sebe. A multi-task learning framework for head pose estimation under target mo- tion. IEEE transactions on pattern analysis and machine intelligence , 38(6):1070– 1083, 2015.
[46] Ruigang Yang and Zhengyou Zhang. Model-based head pose tracking with stereo- vision. In Proceedings of Fifth IEEE International Conference on Automatic Face Gesture Recognition , pages 255–260. IEEE, 2002.
[47] Tsun-Yi Yang, Yi-Hsuan Huang, Yen-Yu Lin, Pi-Cheng Hsiu, and Yung-Yu Chuang. Ssr-net: A compact soft stagewise regression network for age estimation. In IJCAI , volume 5, page 7, 2018.
[48] Tsun-Yi Yang, Yi-Ting Chen, Yen-Yu Lin, and Yung-Yu Chuang. Fsa-net: Learning fine-grained structure aggregation for head pose estimation from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages 1087–1096, 2019.
[49] Xiang Yu, Junzhou Huang, Shaoting Zhang, Wang Yan, and Dimitris N Metaxas. Pose- free facial landmark fitting via optimized part mixtures and cascaded deformable shape model. In Proceedings of the IEEE International Conference on Computer Vision , pages 1944–1951, 2013.
[50] Xiangxin Zhu and Deva Ramanan. Face detection, pose estimation, and landmark localization in the wild. In 2012 IEEE conference on computer vision and pattern recognition , pages 2879–2886. IEEE, 2012.
[51] Xiangyu Zhu, Zhen Lei, Xiaoming Liu, Hailin Shi, and Stan Z Li. Face alignment across large poses: A 3d solution. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 146–155, 2016.
[52] Youding Zhu and Kikuo Fujimura. Head pose estimation for driver monitoring. In IEEE Intelligent Vehicles Symposium, 2004 , pages 501–506. IEEE, 2004.
附录A-超参数
表4、5、6、7和8显示了在AFLW2000、BIWI数据集和我们的组合数据集上测试的WHENet-V和WHENet的β和α元参数的平均误差的消融研究。由此,我们选择了最佳的整体性能为β=2和α=0。5对于WHENet-V,β=1,α=1对于WHENe,尽管性能对这些选择不太敏感。
表4:AFLW2000上WHENet-V MAE与α和β的对比

表5:WHENet-V MAE与BIWI上的α和β

表6:AFLW2000上WHENet MAE与α和β的对比

表7:BIWI上WHENet MAE与α和β的对比

表8:综合数据集上的WHENet MAE与α和β的对比

表9:不同模态方法对BIWI数据集的比较结果。WHENet和WHENet-V在300W-LP和我们的组合数据集上进行训练。其余的方法在BIWI上进行训练,将BIWI数据集分为测试和训练。
附录B-稳定性
WHENet的一个关键目标是对不利的成像条件以及眼镜和帽子等遮挡物和附件具有鲁棒性。WHENet的许多健壮性可以通过使用与Hopenet[33]类似的网络架构来获得,由于CNN架构,它的性能也很好。
图4显示了一组被遮挡的人脸图像,受试者试图在遮挡面部区域的同时保持一致的头部姿势。角度预测非常稳定,角度变化仅为7◦ 尽管特征有明显的遮挡(由于受试者的运动,姿势可能会有一些潜在的变化)。这表明该方法是学习高级特征,而不是特定的局部细节。
我们还评估了决议的效果。图5定性地说明,高达16倍的大幅度下采样不会严重降低预测精度。
我们在AFLW2000数据集上进行了这项测试。结果如图6所示,并与Hopenet[33]和FSANet[48]进行了比较。我们在[33]中列出了四种训练策略中Hopenet报告的最小错误,并感谢作者提供这些数据。
综上所述,全范围WHENet的目标是使用更快、更小的网络完成现有最先进技术范围之外的任务。尽管如此,当在培训期间未使用的两个数据集上进行评估时,它达到或超过了HPE限制情况下正面到平面视图的最先进性能。
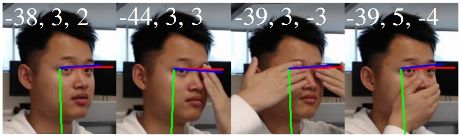
图4:遮挡情况下的头部姿势估计。受试者要求保持静止,同时覆盖面部的不同区域。预测偏差在7%以内◦ 未包含的视图(左)。由于受试者轻微的运动,预计会出现一定程度的偏差。

图5:下采样系数与偏航、俯仰和横滚的关系。基本真值分别为47.6,22.0,18.8。图像按指定的量进行下采样,然后使用最近邻插值调整到原始大小,然后再提供给WHENet。当图像被大幅减少16倍采样时,头部姿势预测保持相对稳定。原始图像来自[51]

图6:下采样因子对MAE的影响。WHENet(橙色)在已经令人印象深刻的Hopenet[33]和FSANet[48]性能(灰色和黑色)上表现出一致的改善。对于Hopenet,我们绘制了[33]中报告的所有训练策略中每个下采样因子的最小(最佳)值
附录C-应用
在这里,我们展示了应用于多个应用程序的WHENet定性示例,这些应用程序演示了HPE如何与现实系统集成,以及我们的培训策略如何允许该方法推广到培训期间不存在的低分辨率和低质量数据。
图7显示了使用基于轻量级OpenPose[28]代码的姿势检测器来检测姿势关键点,同时使用WHENet预测头部姿势。通常情况下,姿势估计无法估计准确HPE的足够关键点,但通过结合全范围HPE方法(如WHENet),可以克服此类限制。举例来说,这可以用于体育广播或教练组在分析比赛时评估参与者的观点和情境意识。
图8描述了一个假设的驾驶员注意模块,其中驾驶员被认为在摄像头相对雅司病<30的情况下保持警惕◦ 否则就会漫不经心。扩展到全范围可以扩展到预测其他活动中的盲点,比如倒车,而不需要额外的硬件。

图7:WHENet应用于根据[28]中的关键点预测生成的头部作物,关键点显示为点,说明了HPE如何与全身姿势估计方法相结合。来自[43]的图片

图8:自动驾驶和驾驶员辅助的应用。左:绿色框表示雅司病<±45◦ 红色框表示可能未注意到车辆。本例强调了高效低分辨率方法对HPE的需求,共有6次低分辨率检测。在这里,低质量的姿态估计产生了贫瘠的种植区域,但尽管没有可比的训练数据,惠内成功地进行了推广。来自[13]的图片。右:WHENet用于监控驾驶员的注意力,当偏航超过30时,将驾驶员标记为注意力不集中(红色)◦ 否则就要专心(绿色)。来自[1]的图片