MonoGRNet论文精读
一、前期准备
3D目标检测集合:https://blog.csdn.net/unbekannten/article/details/127989929
Monogrnet: A geometric reasoning network for monocular 3d object localization.
论文地址:https://arxiv.org/pdf/1811.10247.pdf
代码地址:https://github.com/Zengyi-Qin/MonoGRNet
二、核心思想
将单目3D目标检测任务分解成四个子任务,即2D目标检测+实例级深度估计+投影3D中心估计+局部角点回归
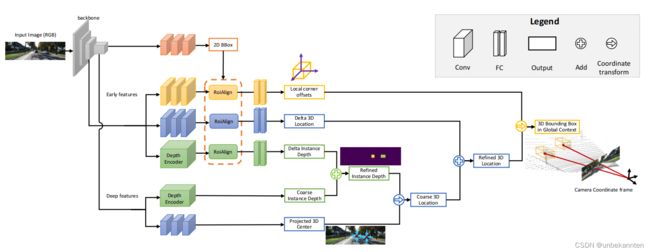
棕:2D检测 绿:实例级深度估计 蓝:3D位置估计 黄:局部角点回归
在检测到的二维边界框的引导下,网络首先估计三维框中心的深度和二维投影,获得全局三维位置,然后在局部背景下回归角坐标。最终的三维边界框基于估计的三维位置和局部角以端到端方式进行优化。
三、相关工作
3.1 2D目标检测
1)效果好,但复杂的多步结构推理速度慢:(Girshick 2015; Ren et al. 2017)
2)快速训练与测试:(Redmon et al. 2016;Redmon and Farhadi 2017; Liu et al. 2016; Fu et al. 2017)
3)引入encoder-decoder结构进行实施语义推理:Multi-net(Teichmann et al. 2016)结合YOLO(Redmon et al. 2016)的快速回归器与Mask-RCNN(He et al. 2017)的size-adjusting RoiAlign
3.2 3D目标检测
1)单目RGB方法:(Chen et al. 2016; Xu and Chen 2018; Chabot et al. 2017; Kehl et al. 2017)
2)多视角RGB方法:(Chen et al. 2017; Chen et al. 2015; Wang et al.)
3)RGB-D的方法:(Qi et al. 2017; Song and Xiao 2016; Liu et al. 2015; Zhang et al. 2014)
Mono3D(Chen et al. 2016)使用语义分割与上下文先验知识来产生3D proposal。
Xu et al.(Xu and Chen 2018)利用预训练的视差估计模型
(Mahjourian, Wicke,and Angelova 2018)引导几何信息推理。
(Chabot et al. 2017; Kehl et al. 2017)利用3DCAD模型产生训练的模拟数据,提供了用于监督的目标的3D模板,目标姿态与相应的2D投影。
使用RGB-D数据,FPointNet(Qi et al. 2017)将2D中region proposal的方式扩展到截面的3D视角,在点云中分割出感兴趣的目标。
MV3D(Chen et al. 2017)在LIDAR点云的鸟瞰图上进行3D目标的proposal,在RGB图片、LIDAR前向图、与鸟瞰图上复用这些特征进行3Dbbox的预测。
3DOP(Chen et al. 2015)使用用于自动驾驶的立体信息与上下文模型。
3.3 单目深度估计
像素级的深度估计网络(Fu et al. 2018; Eigen and Fergus 2015)
四、本文方法
给定一幅单目RGB图像,目标是在3D空间中定位特定类别的对象。目标对象由一个类标签和一个ABBox-3D来表示,该ABBox-3D限定了整个对象,而不考虑遮挡或截断。
AABox-3D由全局3D中心点C=(Xc, Yc, Zc)与8个局部角点{Ok},k=1,……8,组成。三维位置C在摄像机坐标系中标定,局部角点O在局部坐标系中标定
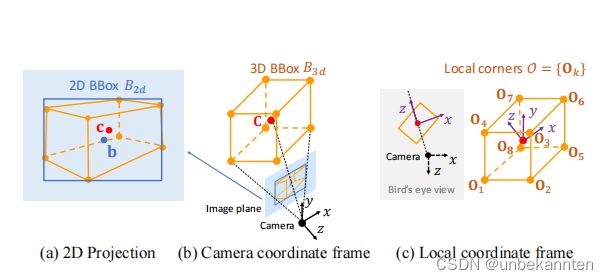
首先,检测ABBox-3D投影的2Dbbox B2d,中心点为b,大小为(w, h);
之后,预测3Dbbox中心点C的深度Zc与2D投影c,以实现C的定位;
最后,基于局部特征根据3D中心回归出局部角点O。
通过估计每个感兴趣目标下列参数来表达ABBox-3d定位:B3d=(B2d, Zc, c, O)
(注:说明二维中心和三维中心投影不一样)
单目几何推理网络
输入:单目RGB图像
输出:B2d(2Dbbox中心)、Zc(3Dbbox中心深度)、c(3Dbbox中心二维投影)、O(8个局部角点)
4.1 2D目标检测
我们使用(Teichmann et al. 2016)中的检测组建设计,将快速回归(Redmon et al. 2016)与尺度自适应RoiAlign(He et al. 2017)相结合,达到速度与准确率合理的均衡。
W×H的输入图像I被分解成Sx×Sy网格G,单元格用g表示。与图像网格单元对应的特征图中每个像素都产生一个预测。每个单元格g的二维预测包含了一个感兴趣的对象存在的置信度和该对象的二维边界框,即(Pr obj,B2d),表示为上标g。二维边界框B2d =(δxb,δyb,w,h)通过中心b到单元格g偏置(δxb、δyb)和2D框大小(w,h)。
预测的二维边界盒作为RoiAlign(He et al. 2017)层的输入,提取高分辨率的早期特征,以细化预测,并减少基于检测器的快速检测器之间的性能差距。
4.2 实例级深度估计
IDE子网络估计ABBox-3D中心Zc的深度。给定骨干网络特征图划分的网格G,每个网格单元g预测距离阈值σscope最近实例的三维中心深度,考虑深度信息,即为单元网格分配更接近的实例。

IDE模块由一个不考虑尺度与特定目标2D位置的区域深度的粗回归与一个细化的阶段依靠2Dbbox在目标覆盖的区域提取编码的深度特征
从深度层回归大致深度偏置Zcc。给定检测到的2Dbbox,我们可以对早期特征图中包含实例的区域用更高的分辨率与更小的感受野进行RoiAlign。校准特征通过全连接网络回归δZc从而优化实例级深度值.最终预测值为Zc=Zcc+δZc。

4.3 投影3D中心估计
这个子网络估计了在每个网格g中一个感兴趣的对象的3D中心C =(Xc,Yc,Zc)的位置。由于透视变换,C的二维中心b和三维中心点的二维投影c并不位于同一位置。首先将投影c进行回归,然后根据估计的深度Zc将其反向投影到三维空间。
X=(X, Y, Z)——> x = (u, v)
u = fx * X/Z + px
v = fy * Y/Z + py
fx fy为X,Y轴的焦距;px py为主点的坐标
用到的公式如下:

利用深度特征将投影中心c的偏移量δc =(δxc,δyc)回归到网格单元g,并计算一个粗糙的3D位置Cs=ψ2D→3D(δc+g,Zc)。提取高分辨率的早期特征,回归预测的δC和地面之间的增量,细化最终的3D位置C = Cs + δC。
4.4 局部角点回归
该子网络回归局部坐标系下的8个角点
由于每个网格单元在二维检测器中预测一个二维边界框,将RoiAlign应用于具有高分辨率的早期特征图中的单元格的相应区域,并回归到三维边界框的局部角。
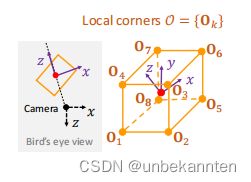
构造局部坐标系,原点在物体的中心,z轴从相机直接指向中心,x轴在z轴的右侧,y轴没有变化。从局部坐标到相机坐标的转换涉及到一个旋转R和一个平移C。Ocam = RO + C,Ocam为全局角坐标
五、损失函数
5.1 2D目标检测损失
目标的置信度使用softmax交叉熵loss进行训练,2DBBox的B2d=(xb, yb, w, h)通过带掩模的L1距离loss回归得到。注意w与h通过W与H进行正则化。
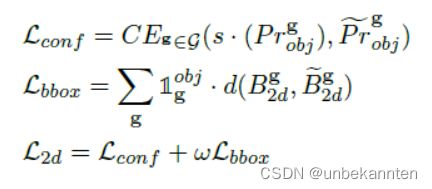
其中,Pr obj和**分别表示预测的与真实的置信度
d(.)表示L1距离llobj屏蔽未包含任何物体的网络。每个网格g的掩模函数如果小于阈值设置为1,否则设置为0,两部分通过w均衡。
5.2 实例级深度损失
L1损失
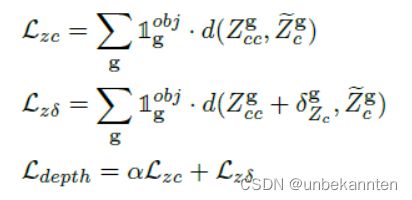
其中,α > 1鼓励网络首先学习粗深度,然后再学习增量。
5.3 3D定位损失
将2D投影与3D定位的L1loss相加

β>1,首先学习投影中心,然后细化最终的3D预测
5.4 局部角点损失
所有角点L1 loss之和
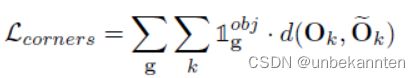
联合损失表达式
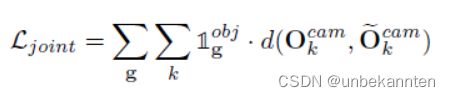
六、实验实施
暂略
七、相关链接参考
https://blog.csdn.net/qq_26623879/article/details/103039667
https://blog.csdn.net/chengyq116/article/details/92425255
https://blog.csdn.net/chengyq116/article/details/90705491
https://blog.csdn.net/abrams90/article/details/98484420
https://zhuanlan.zhihu.com/p/367061627