Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting
ICLR 2018,DCRNN,模型借鉴了Structured Sequence Modeling With Graph Convolutional Recurrent Networks (ICLR 2017 reject)里面的DCRNN,将该模型应用于了交通预测上。而且后者的论文使用的卷积是Defferrard提出的图卷积,这篇论文中使用的是扩散卷积,这种扩散卷积使用的是随机游走,与Diffusion-Convolutional Neural Networks (NIPS 2016)的扩散卷积还不一样。构造出来的DCRNN使用了Structured Sequence Modeling With Graph Convolutional Recurrent Networks (ICLR 2017 reject)两种形式中的模型2,即使用扩散卷积学习出空间表示后,放入GRU中进行时间上的建模。原文链接:Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting
摘要
交通预测的挑战:1. 对路网复杂的空间依赖关系, 2. 路况变换与非线性的时间动态性, 3. 长期预测的困难性。我们提出了在有向图上对交通流以扩散形式进行建模的方法,介绍了 Diffusion Convolutional Recurrent Neural Network (DCRNN),用于交通预测的深度学习框架,同时集成了交通流中的空间与时间依赖。DCRNN 使用图上的双向随机游走捕获了空间依赖,使用编码解码框架以及 scheduled sampling 捕获时间依赖。我们在两个真实的交通数据集上评估了模型,比 state-of-the-art 强了12%-15%。
1 引言
对一个在动态系统中运行的学习系统来说,时空预测是一个很关键的任务。自动驾驶、电网优化、供应链管理等都是它的应用。我们研究了一个重要的任务:路网上的交通预测,这是智能交通系统中的核心部分。目标是给定历史车速与路网数据,预测未来的车速。
任务有挑战性的原因是复杂的时空依赖关系以及长期预测的上的难度。一方面,交通数据序列表现出了强烈的时间动态性(temporal dynamics)。反复的事件如高峰期或交通事故导致了数据的非平稳性,使得长期预测很困难。另一方面,路网上的监测器包含了复杂但是唯一的空间联系(spatial correlations)。图1展示了一个例子。路1和路2是相关联的,但是路1和路3没有关联。尽管路1和路3在欧氏空间中很近,但是他们表现出了不同的形式。此外,未来的车速更容易受到下游交通的影响,而非上游。这就意味着交通上的空间结构不是欧氏空间的,而是有向的。

Figure1
交通预测已经研究了几十年,有两个主要类别:知识驱动的方法和数据驱动的方法。在运输和操作研究中,知识驱动的方法经常使用排队论,模拟交通中的用户行为(Cascetta, 2013)。时间序列社区中,数据驱动的方法如 Auto-Regressive Integrated Moving Average(ARIMA) 模型,Kalman filtering 还是很流行的(Liu et al., 2011; Lippi et al., 2013)。然而,简单的时间序列模型通常依赖平稳假设,这经常与实际交通数据不符。最近开始在交通预测上应用深度学习模型 (Lv et al., 2015; Yu et al., 2017b) ,但是没有考虑空间结构。Wu & Tan 2016和Ma et al. 2017 使用 CNN 对空间关系进行建模,但是在欧氏空间中的。Bruna et al. 2014,Defferrard et al. 2016 研究了图卷积,但是只能处理无向图。
我们使用一个有向图来表示 pair-wise spatial correlations。图的顶点是sensors,边是权重,通过路网上 sensor 之间的距离得到。我们使用扩散卷积 (diffusion convolution) 操作来捕获空间依赖关系,以扩散性是对交通流的动态性建模。提出了 Diffusion Convolutional Recurrent Neural Network (DCRNN),整合了 diffusion convolution 和 sequence to sequence 架构以及 scheduled sampling 技术。在真实数据集上衡量模型时,DCRNN 比state-of-the-art好很多。
· 我们研究了交通预测问题,在有向图上对交通的空间依赖以扩散形式建模。提出了 diffusion convolution,有着直观的解释以及高效的计算。
· 我们提出了 Diffusion Convolutional Recurrent Neural Network (DCRNN),使用 diffusion convolution,sequence to sequence,scheduled sampling 同时对时间和空间依赖关系进行捕获的方法。DCRNN 不限于运输领域,可以应用到其他的时空预测问题上。
· 做了很多实验,效果很好。
2 Methodology
2.1 Traffic Forecasting Problem
NN 个sensors。检测器网络表示成带权有向图 G=(V,E,W)G=(V,E,W),VV 是顶点集,|V|=N|V|=N,EE 是边集,W∈RN×NW∈RN×N 是带权邻接矩阵,表示顶点相似性(如路网距离的一个函数)。图信号矩阵X∈RN×PX∈RN×P,PP 是每个顶点的特征数。X(t)X(t) 表示时间 tt 观测到的图信号,交通预测问题目的是学习一个函数 h(⋅)h(⋅),将 T′T′ 个历史的图信号映射到未来的 TT 个图信号上,给定图 GG:
[X(t−T′+1),…,X(t);G]−→−h(⋅)[X(t+1),…,X(t+T)][X(t−T′+1),…,X(t);G]→h(⋅)[X(t+1),…,X(t+T)]
2.2 Spatial Dependency Modeling
扩散形式以 GG 上的随机游走来刻画,重启概率 α∈[0,1]α∈[0,1],状态转移矩阵 D−1OWDO−1W。这里,DO=diag(W1)DO=diag(W1) 是出度的对角矩阵,1∈RN1∈RN 表示所有都为1的向量。多个时间步之后,Markov process 会收敛到平稳分布 P∈RN×NP∈RN×N上,第 ii 行 Pi,:∈RNPi,:∈RN 表示从顶点 vi∈Vvi∈V 扩散的可能性,也就是对顶点 vivi 的 proximity。下面的引理是平稳分布的闭式解。
Lemma 2.1 (Teng et al., 2016) 扩散过程的平稳分布可以表示为图上的无限随机游走的带权组合,可以通过以下式子计算:
P=∑k=0∞α(1−α)k(D−1OW)k(1)(1)P=∑k=0∞α(1−α)k(DO−1W)k
其中 kk 是diffusion step。实际上,我们使用有限的 KK 阶扩散过程,给每一步分配一个可训练的权重。我们也融入反向扩散过程,因为双向扩散可以让模型更灵活地去捕获上游和下游交通带来的影响。
Diffusion Convolution 图信号 X∈RN×PX∈RN×P 和滤波器 fθfθ 的扩散卷积操作的结果是:
X:,p⋆Gfθ=∑k=0K−1(θk,1(D−1OW)k+θk,2(D−1IWT)k)X:,p for p∈{1,…,P}(2)(2)X:,p⋆Gfθ=∑k=0K−1(θk,1(DO−1W)k+θk,2(DI−1WT)k)X:,p for p∈{1,…,P}
其中 θ∈RK×2θ∈RK×2 表示卷积核参数,D−1OWDO−1W 和 D−1IWTDI−1WT 表示扩散过程和反向扩散的转移概率矩阵。一般,计算卷积是很耗时的。然而,如果 GG 是稀疏的,式2可以通过递归的复杂度为 O(K)O(K) 的sparse-dense矩阵乘法高效的计算,总时间复杂度为 O(K|E|)≪O(N2)O(K|E|)≪O(N2)。附录B有详细的描述。
Diffusion Convolutional Layer 式2定义的卷积操作,我们可以构建一个扩散卷积层,将 PP维特征映射到 QQ 维输出上。将参数表示为 Θ∈RQ×P×K×2=[θ]q,pΘ∈RQ×P×K×2=[θ]q,p,其中 Θq,p,:,:∈RK×2Θq,p,:,:∈RK×2 是第 pp 个输入和 qq 个输出的参数。扩散卷积层为:
H:,q=a(∑p=1PX:,p⋆GfΘq,p,:,:) for q∈{1,…,Q}(3)(3)H:,q=a(∑p=1PX:,p⋆GfΘq,p,:,:) for q∈{1,…,Q}
其中,X∈RN×PX∈RN×P 是输入,H∈RN×QH∈RN×Q 是输出,{fΘq,p,:,:}{fΘq,p,:,:} 是滤波器,aa 是激活函数。扩散卷积层学习图结构数据的表示,我们可以使用基于随机梯度的方法训练它。
Relation with Spectral Graph Convolution: 扩散卷积是定义在有向和无向图上的。当使用在无向图上时,我们发现很多现存的图结构卷积操作,包括流行的普图卷积,ChebNet,可以看作是一个扩散卷积的特例。令 DD 表示度矩阵,L=D−12(D−W)D−12L=D−12(D−W)D−12 是图归一化的拉普拉斯矩阵,接下来的Proposition解释了连接。
Proposition 2.2. 谱图卷积的定义:
X:,p⋆Gfθ=ΦF(θ)ΦTX:,pX:,p⋆Gfθ=ΦF(θ)ΦTX:,p
特征值分解 L=ΦΛΦTL=ΦΛΦT,当图 GG是无向图时,F(θ)=∑K−10θkΛkF(θ)=∑0K−1θkΛk,等价于图的扩散卷积。
证明见后记C。
2.3 Temporal Dynamics Modeling
我们利用 RNN 对时间依赖建模。我们使用 GRU,简单有效的 RNN 变体。我们将 GRU 中的矩阵乘法换成了扩散卷积,得到了我们的扩散卷积门控循环单元 Diffusion Convolutional Gated Recurrent Unit(DCGRU).
r(t)=σ(Θr⋆G[X(t),H(t−1)]+br)u(t)=σ(Θu⋆G[X,H(t−1)]+bu)C(t)=tanh(ΘC⋆G[X(t),(r(t)⊙H(t−1))]+bc)H(t)=u(t)⊙H(t−1)+(1−u(t))⊙C(t)r(t)=σ(Θr⋆G[X(t),H(t−1)]+br)u(t)=σ(Θu⋆G[X,H(t−1)]+bu)C(t)=tanh(ΘC⋆G[X(t),(r(t)⊙H(t−1))]+bc)H(t)=u(t)⊙H(t−1)+(1−u(t))⊙C(t)
其中 X(t),H(t)X(t),H(t) 表示时间 tt 的输入和输出,r(t),u(t)r(t),u(t) 表示时间 tt 的reset gate和 update gate。⋆G⋆G 表示式2中定义的混合卷积,Θr,Θu,ΘCΘr,Θu,ΘC 表示对应的滤波器的参数。类似 GRU,DCGRU 可以用来构建循环神经网络层,使用 BPTT 训练。

Figure2
在多步预测中,我们使用 Sequence to Sequence 架构。编码解码器都是 DCGRU。训练时,我们把历史的时间序列放到编码器,使用最终状态初始化解码器。解码器生成预测结果。测试时,ground truth 替换成模型本身生成的预测结果。训练和测试输入的分布的差异会导致性能的下降。为了减轻这个问题的影响,我们使用了 scheduled sampling (Bengio et al., 2015),在训练的第 ii 轮时,模型的输入要么是概率为 ϵiϵi 的 ground truth,要么是概率为 1−ϵi1−ϵi 的预测结果。在训练阶段,ϵiϵi 逐渐的减小为0,使得模型可以学习到测试集的分布。
图2展示了 DCRNN 的架构。整个网络通过 BPTT 循环生成目标时间序列的最大似然得到。DCRNN 可以捕获时空依赖关系,应用到多种时空预测问题上。
3 Related Work
运输领域和运筹学中交通预测是传统问题,主要依赖于排队论和仿真(Drew, 1968)。数据驱动的交通预测方法最近受到了很多的关注,详情可以看近些年的 paper (Vlahogianni et al., 2014)。然而,现存的机器学习模型要么有着很强的假设(如 auto-regressive model )要么不能考虑非线性的时间依赖(如 latent space model Yu et al. 2016; Deng et al. 2016)。深度学习模型为解决时间序列预测问题提供了新的方法。举个例子,在 Yu et al. 2017b; Laptev et al. 2017 的工作中,作者使用深度循环神经网络研究时间序列预测问题。卷积神经网络已经被应用到交通预测上。Zhang et al. 2016; 2017 将路网转换成了 2D 网格,使用传统的 CNN 预测人流。Cheng et al. 2017 提出了DeepTransport,通过对每条路收集上下游邻居路段对空间依赖建模,在这些邻居上分别使用卷积操作。
最近,CNN 基于谱图理论已经泛化到任意的图结构上。图卷积神经网络由 Bruna et al. 2014 首次提出,在深度神经网络和谱图理论之间建立了桥梁。Defferrard et al. 2016 提出了 ChebNet,使用快速局部卷积滤波器提升了 GCN。Kipf & Welling 2017 简化了 ChebNet,在半监督分类任务上获得了 state-of-the-art 的表现。Seo et al. 2016 融合了 ChebNet 和 RNN 用于结构序列建模。Yu et al. 2017a 对检测器网络以无向图的形式,使用 Chebnet 和卷积序列模型 (Gehring et al. 2017) 进行建模做预测。这些提及的基于谱的理论的限制之一是,他们需要图是无向的,来计算有意义的谱分解。从谱域到顶点域,Atwood & Towsley 2016 提出了扩散卷积神经网络 (DCNN),以图结构中每个顶点的扩散过程定义了卷积。Hechtlinger et al. 2017 提出了 GraphCNN 对每个顶点的 pp 个最近邻邻居进行卷积,将卷积泛化到图上。然而,这些方法没有考虑时间的动态性,主要处理的是静态图。
我们的方法不同于这些方法,因为问题的设定不一样,而且图卷积的公式不同。我们将 sensor network 建立成一个带权有向图,比网格和无向图更真实。此外,我们提出的卷积操作使用双向图随机游走来定义,集成了序列到序列模型以及 scheduled sampling ,对长时间的时间依赖建模。
4 Experiments
我们在两个数据集上做了实验:(1)METR-LA 这个交通数据集包含了洛杉矶高速公路线圈收集的数据 (Jagadish et al., 2014)。我们选择了207个检测器,收集了从2012年3月1日到2012年6月30日4个月的数据用于实验。(2)PEMS_BAY 这个交通数据集由 California Transportation Agencies(CalTrans)Performance Measurement System (PeMS) 收集。我们选了 Bay Area 的325个检测器,收集了从2017年1月1日到2017年5月31日6个月的数据用于实验。两个数据集监测器的分布如图8所示。
这两个数据集,我们将车速聚合到了5分钟的窗口内,使用了 Z-Score normalization。70%的数用于训练,20%用于测试,10%用于验证。为了构建检测器网络,我们计算了任意两个 sensor 的距离,使用了 thresholded Gaussian kernel 来构建邻接矩阵(Shuman et al., 2013)。Wij=exp(−dist(vi,vj)2σ2) if dist(vi,vj)≤κ,otherwise 0Wij=exp(−dist(vi,vj)2σ2) if dist(vi,vj)≤κ,otherwise 0,其中 WijWij 表示了检测器 vivi 和 vjvj 之间的权重,dist(vi,vj)dist(vi,vj) 表示检测器 vivi 到 vjvj 之间的距离。σσ 表示距离的标准差,κκ 表示阈值。

Figure8

Table
4.1 Experimental Settings
Baselines 1. HAHA:历史均值,将交通流建模成周期性过程,使用之前的周期的加权平均作为预测。2. ARIMAkalARIMAkal:Auto-Regressive Integrated Moving Average model with Kalman filter,广泛地应用于时间序列预测上。3. VARVAR: Vector Auto-Regression(Hamilton, 1994)。4. SVRSVR:Support Vector Regression,使用线性支持向量机用于回归任务。5. Feed forward Neural network (FNN):前向传播神经网络,两个隐藏层,L2正则化。6. Recurrent Neural Network with fully connected LSTM hidden units (FC-LSTM)(Sutskever et al., 2014).
所有的神经网络方法都是用 Tensorflow 实现,使用 Adam 优化器,学习率衰减。使用 Tree-structured Parzen Estimator(TPE)(Bergstra et al., 2011) 在验证集上选择最好的超参数。DCRNN 的详细参数设置和 baselines 的超参数设置见附录E。
4.2 Traffic Forecasting Performance Comparison
表1展示了不同的方法在15分钟,30分钟,1小时在两个数据集上预测的对比。这些方法在三种常用的 metrics 上进行了评估,包括1. MAE, 2. MAPE(Mean Absolute Percentage Error), 3. RMSE。这些 metrics 中的缺失值被排除出去。这些公式在后记E.2。我们观察到这两个数据集上有以下现象:1. RNN-based methods,包括FC-LSTM和DCRNN,一般比其他的方法表现得好,这强调对时间依赖的建模的重要性。2. DCRNN在所有的 forecasting horizons 中的所有 metrics 上都获得了最好的表现,这说明对空间依赖建模的有效性。3. 深度学习模型,包括 FNN,FC-LSTM,DCRNN 在长期预测上,倾向于比线性的 baseline 有更好的结果。比如,1小时。这是因为随着 horizon 的增长,时间依赖变得更加非线性。此外,随着历史均值不依赖短期数据,它的表现对于 forecasting horizon 的小增长是不变的。
需要注意的是,METR-LA(Los Angeles,有很复杂的交通环境)数据比 PEMS-BAY 更有挑战性,所以我们将 METR-LA 的数据作为以下实验的默认数据集。
4.3 Effect of Spatial Dependency Modeling
为了继续深入对空间依赖建模的影响,我们对比了 DCRNN 和以下变体: 1. DCRNN-NoConv,这个通过使用单位阵替换扩散卷积(式2)中的转移矩阵,忽略了空间依赖。这就意味着预测只能通过历史值预测。 2. DCRNN-UniConv,扩散卷积中只使用前向随机游走;图3展示了这三个模型使用大体相同数量的参数时的学习曲线。没有扩散卷积,DCRNN-NoConv 有着更大的 validation error。此外,DCRNN获得了最低的 validation error,说明了使用双向随机游走的有效性。这个告诉我们双向随机游走赋予了模型捕获上下游交通影响的能力与灵活性。
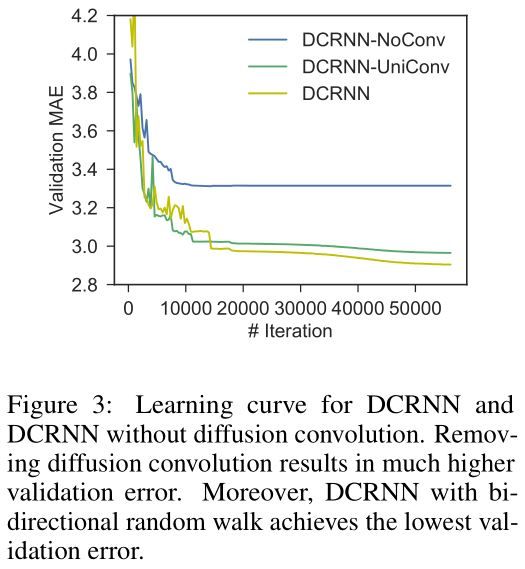
Figure3
为了研究图的构建方法的影响,我们构建了一个无向图,Wˆij=Wˆji=max(Wij,Wji)W^ij=W^ji=max(Wij,Wji),其中 WˆW^ 是新的对称权重矩阵。然后我们使用了 DCRNN 的一个变体,表示成 GCRNN,使用 ChebNet 卷积的序列到序列学习,并用大体相同的参数数量。表2展示了 DCRNN 和 GCRNN 在 METR-LA 数据集上的对比。DCRNN 都比 GCRNN 好。这说明有向图能更好的捕获交通检测器之间的非对称关系。图4展示了不同参数的影响。KK 大体对应了卷积核感受野的大小,单元数对应了卷积核数。越大的 KK 越能使模型捕获更宽的空间依赖,代价是增加了学习的复杂度。我们观测到随着 KK 的增加,验证集上的误差先是快速下降,然后微微上升。改变不同数量的单元也会有相似的情况。

Table2
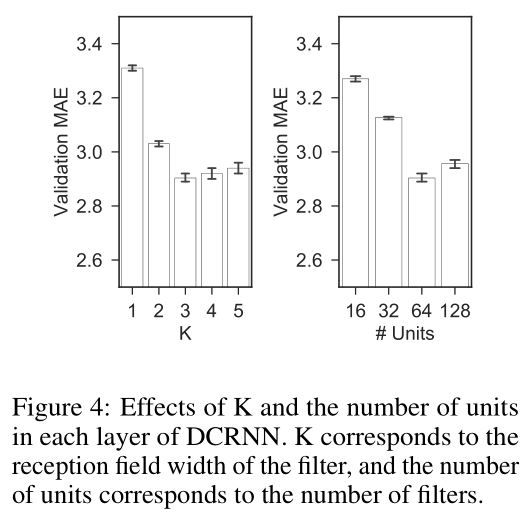
Figure4
4.4 Effect of Temporal Dependency Modeling
为了衡量时间建模的影响,包括序列到序列框架以及 scheduled sampling 技术,我们设计 DCRNN 的三种变体:1. DCNN:我们拼接历史的观测值为一个固定长度的向量,将它放到堆叠的扩散卷积层中,预测未来的时间序列。我们训练一个模型只预测一步,将之前的预测结果放到模型中作为输入,使用多步前向预测。2. DCRNN-SEQ:使用编码解码序列到序列学习框架做多步预测。3. DCRNN:类似 DCRNN-SEQ ,除了增加了 scheduled sampling。
图5展示了这四种方法针对 MAE 的对比。我们观察到:1. DCRNN-SEQ 比 DCNN 好很多,符合了对时间建模的重要性。2. DCRNN 达到了最好的效果,随着预测 horizon 的增加,它的先进性变得越来越明显。这主要是因为模型在训练的时候就在处理多步预测时出现的误差,因此会很少的受到误差反向传播的影响。我们也训练了一个总是将输出作为输入扔到模型中的模型。但是它的表现比这三种变体都差,这就强调了 scheduled sampling 的重要性。

Figure5
4.5 模型的解释性
为了更好的理解模型,我们对预测结果和学习到的滤波器进行性了可视化。图6展示了预测1小时的效果。我们观察到了以下情况:1. DCRNN 在交通流速度中存在小的震荡时,用均值生成了平滑的预测结果(图6a)。这反映了模型的鲁棒性。2. DCRNN 比 baseline 方法(如FC-LSTM)更倾向于精确的预测出突变。图6b展示了 DCRNN 预测了高峰时段的起始和终止。这是因为 DCRNN 捕获了空间依赖,能够利用邻居检测器速度的变换来精确预测。图7展示了以不同顶点为中心学习到的滤波器的样例。星表示中心,颜色表示权重。我们可以观察到权重更好的在中心周围局部化,而且权重基于路网距离进行扩散。更多的可视化在附录F。

Figure6
Figure7
5 Conclusion
我们对路网上的交通预测做了时空上的建模,提出了 diffusion convolutional recurrent neural network,可以捕获时空依赖。特别地,我们使用双向随机游走,对空间依赖建模,使用循环神经网络捕获时间的动态性。还继承了编码解码架构和 scheduled sampling 技术来提升长期预测的性能。在两个真实的数据集上评估了性能,我们的方法比 baselines 好很多。未来的工作,1. 使用提出的网络解决其他的时空预测问题;2. 对不断演化的图结构的时空依赖关系建模。
Appendix
B Efficient Calculation Of Equation
式2可以分解成两个有相同时间复杂度的部分,一部分是 D−1OWDO−1W,另一部分是 D−1IWTDI−1WT。因此我们只研究第一部分的时间复杂度。
令 Tk(x)=(D−1OW)kxTk(x)=(DO−1W)kx,式2的第一部分可以重写为:
∑k=0K−1θkTk(X:,p)(4)(4)∑k=0K−1θkTk(X:,p)
因为 Tk+1(x)=D−1OWTk(x)Tk+1(x)=DO−1WTk(x) 和 D−1OWDO−1W 是稀疏的,可以很容易看出式4可以通过 O(K)O(K) 的递归稀疏-稠密矩阵乘法,每次时间复杂度为 O(|ε|)O(|ε|) 得到。然后,式2和式4的时间复杂度都为 O(K|ε|)O(K|ε|)。对于稠密图,我们可以使用 spectral sparsification(Cheng et al., 2015) 使其稀疏。
C Relation With Spectral Graph Convolution
Proof. 谱图卷积利用归一化的拉普拉斯矩阵 L=D−12(D−W)D12=ΦΛΦTL=D−12(D−W)D12=ΦΛΦT。ChebNet 使 fθfθ 参数化为一个 ΛΛ 的 KK 阶多项式,使用稳定的切比雪夫多项式基计算这个值。
X:,p⋆Gfθ=Φ(∑k=0K−1θkΛk)ΦTX:,p=∑k=0K−1θkLkX:,p=∑k=0K−1θ~kTk(L~)X:,p(5)(5)X:,p⋆Gfθ=Φ(∑k=0K−1θkΛk)ΦTX:,p=∑k=0K−1θkLkX:,p=∑k=0K−1θ~kTk(L~)X:,p
其中 T0(x)=1,T1(x)=x,Tk(x)=xTk−1(x)−Tk−2(x)T0(x)=1,T1(x)=x,Tk(x)=xTk−1(x)−Tk−2(x) 是切比雪夫多项式的基。令 λmaxλmax 表示 LL 最大的特征值,L~=2λmaxL−IL~=2λmaxL−I 表示将拉普拉斯矩阵的缩放,将特征值从 [0,λmax][0,λmax] 映射到 [−1,1][−1,1],因为切比雪夫多项式生成了一个在 [−1,1][−1,1] 内正交的基。式5可以看成一个关于 L~L~ 的多项式,我们一会儿可以看到,ChebNet 卷积的输出和扩散卷积到常数缩放因子的输出相似。假设 λmax=2λmax=2,无向图 DI=DO=DDI=DO=D。
L~=D−12(D−W)D−12−I=−D−12WD−12∼−D−1W(6)(6)L~=D−12(D−W)D−12−I=−D−12WD−12∼−D−1W
L~L~ 和负的随机游走转移矩阵相似,因此式5的输出也和式2直到常数缩放因子的输出相似。