Pytorch入门--详解Mnist手写字识别
1 什么是Mnist?
Mnist是计算机视觉领域中最为基础的一个数据集。
MNIST数据集(Mixed National Institute of Standards and Technology database)是美国国家标准与技术研究院收集整理的大型手写数字数据集,包含了60,000个样本的训练集以及10,000个样本的测试集。Mnist中所有样本都会将原本28*28的灰度图转换为长度为784的一维向量作为输入,其中每个元素分别对应了灰度图中的灰度值。Mnist使用一个长度为10的向量作为该样本所对应的标签,其中向量索引值对应了该样本以该索引为结果的预测概率。
2、代码实现
需导入的python库
import torch
import scipy.misc
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.datasets import MNIST
from torch import optim
import torch.nn as nn
import torch.nn.functional as F构建模型
# 构建模型(简单的卷积神经网络)
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size =5, padding = 2) # 卷积
self.conv2 = nn.Conv2d(6, 16, 5)
# Linear(in_feactures(输入的二维张量大小), out_feactures)
self.fc1 = nn.Linear(16*5*5, 120) # 全连接
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10) # 最后输出10个类
def forward(self, x):
# 激活函数
out = F.relu(self.conv1(x))
# max_pool2d(input, kernel_size(卷积核), stride(卷积核步长)=None, padding=0, dilation=1, ceil_mode(空间输入形状)=False, return_indices=False)
out = F.max_pool2d(out, kernel_size = 2) # 池化
out = F.relu(self.conv2(out))
out = F.max_pool2d(out, 2)
# 将多维的的数据平铺为一维
out = out.view(out.size(0), -1)
out = F.relu(self.fc1(out))
out = F.relu(self.fc2(out))
out = self.fc3(out)
return out
训练集
def train():
# 学习率0.001
learning_rate = 1e-3
# 单次大小
batch_size = 100
# 总的循环
epoches = 50
lenet = LeNet()
# 1、数据集准备
# 这个函数包括了两个操作:transforms.ToTensor()将图片转换为张量,transforms.Normalize()将图片进行归一化处理
trans_img = transforms.Compose([transforms.ToTensor()])
# path = './data/'数据集下载后保存的目录,下载训练集
trainset = MNIST('./data', train=True, transform=trans_img, download=True)
# 构建数据集的DataLoader,
# Pytorch自提供了DataLoader的方法来进行训练,该方法自动将数据集打包成为迭代器,能够让我们很方便地进行后续的训练处理
# 迭代器(iterable)是一个超级接口! 是可以遍历集合的对象,
trainloader = DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=10)
# 2、构建迭代器与损失函数
criterian = nn.CrossEntropyLoss(reduction='sum') # loss(损失函数)
optimizer = optim.SGD(lenet.parameters(), lr=learning_rate) # optimizer(迭代器)
# 如果网络能在GPU中训练,就使用GPU;否则使用CPU进行训练
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#lenet.to("cpu")
# 3、训练
for i in range(epoches):
running_loss = 0.
running_acc = 0.
for (img, label) in trainloader: # 将图像和标签传输进device中
optimizer.zero_grad() # 求梯度之前对梯度清零以防梯度累加
output=lenet(img) # 对模型进行前向推理
loss=criterian(output,label) # 计算本轮推理的Loss值
loss.backward() # loss反传存到相应的变量结构当中
optimizer.step() # 使用计算好的梯度对参数进行更新
running_loss+=loss.item()
#print(output)
_,predict=torch.max(output,1) # 计算本轮推理的准确率
correct_num=(predict==label).sum()
running_acc+=correct_num.item()
running_loss/=len(trainset)
running_acc/=len(trainset)
print("[%d/%d] Loss: %.5f, Acc: %.2f" % (i + 1, epoches, running_loss,100 * running_acc))
return lenet
测试集
def test(lenet):
batch_size = 100
trans_img = transforms.Compose([transforms.ToTensor()])
testset = MNIST('./data', train=False, transform=trans_img, download=True)
testloader = DataLoader(testset, batch_size, shuffle=False, num_workers=10)
running_acc = 0.
for (img, label) in testloader:
output = lenet(img)
_, predict = torch.max(output, 1)
correct_num = (predict == label).sum()
running_acc += correct_num.item()
running_acc /= len(testset)
return running_acc主函数
if __name__ == '__main__':
lenet = train()
torch.save(lenet, 'lenet.pkl') # save model
lenet = torch.load('lenet.pkl') # load model
test_acc = test(lenet)
print("Test Accuracy:Loss: %.2f" % test_acc)结果:
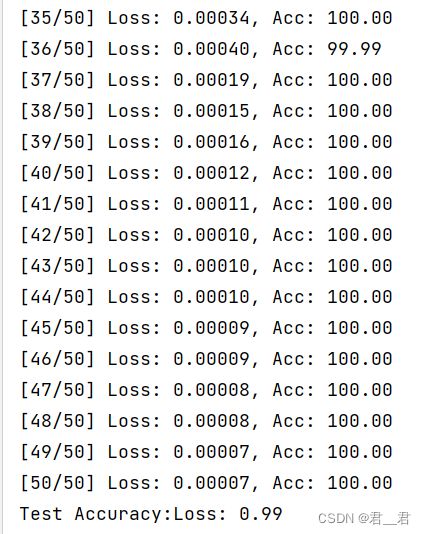
继上面对minst手写数字集进行训练和测试的完成,现将黑底白字的0~9的数字图片,进行识别










识别函数代码如下
def practice(img_path):
img = Image.open(img_path)
img = img.convert('L')
prac_img = transforms.Compose([transforms.Resize((28, 28)),transforms.ToTensor()])
pracset = MNIST('./data', train=True, transform=prac_img, download=True)
img = prac_img(img)
img = torch.reshape(img, (1, 1, 28, 28))
lenet = torch.load('lenet.pkl') # load model
output = lenet(img)
output = output.argmax(1)
dict_target = pracset.class_to_idx
dict_target = [indx for indx, vale in dict_target.items()] # 获得标签字典
print('识别类型为{}'.format(dict_target[output]))主函数调用(图片路径按自身修改)
if __name__ == '__main__':
practice('0.jpg')
practice('1.jpg')
practice('2.jpg')
practice('3.jpg')
practice('4.jpg')
practice('5.jpg')
practice('6.jpg')
practice('7.jpg')
practice('8.jpg')
practice('9.jpg')识别结果如下所示:
