Pytorch深度学习实践第八讲课后习题 训练titanic数据集
本节没有课程传送门,算是博主根据老师讲的内容做的作业。
数据集传送门 Kaggle Titanic dataset
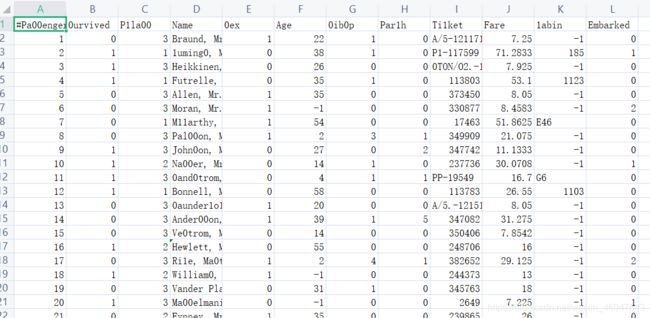
这里对数据集进行了一些处理,首先第一行不能是属性名而非特征,不能使用所以在第一个表格
前加了'#',另外有一些无用特征比如乘客姓名这里选择了直接跳过,最后在处理过发现np.loadtxt
函数不能识别'str'类型数据,所以空数据用‘-1’进行了替换,数据集最后一项只有三个类别,所以用
'0','1','2'标记替换。下面是处理后的训练集截图
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import numpy as np
import matplotlib.pyplot as plt
#程序运行过程会有一些警告,这个没问题。
class titanicDataset(Dataset):
def __init__(self,filepath):
x = np.loadtxt(filepath, delimiter=',', dtype=np.float32, usecols=(2, 5, 6, 7, 8, 10, 12))
#上面只取有效特征,类似人名,票号等唯一特征对训练没用就没取。
y = np.loadtxt(filepath, delimiter=',', dtype=np.float32, usecols=1)
# 'delimiter'为分隔符
y = y[:, np.newaxis]
#这里增加一维,不然计算loss的时候维度不同会报错
self.x_data = torch.from_numpy(x)
self.y_data = torch.from_numpy(y)
self.len = x.shape[0]
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = titanicDataset('titanic_train.csv')#读数据集
#print(dataset.x_data,'\n',dataset.y_data)
train_loader = DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2)#将数据集分成小批量
#读测试集数据
class test(Dataset):
def __init__(self,filepath):
x = np.loadtxt(filepath, delimiter=',', dtype=np.float32, usecols=(1, 4, 5, 6, 7, 9, 11))
self.len = x.shape[0]
self.x = torch.from_numpy(x)
def __getitem__(self, index):
return self.x[index]
def __len__(self):
return self.len
testset = test('titanic_test.csv')#测试集
testset = testset.x
#---设计模型
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(7, 6)
self.linear2 = torch.nn.Linear(6, 3)
self.linear3 = torch.nn.Linear(3, 1)
self.sigmoid = torch.nn.Sigmoid()
self.activate = torch.nn.ReLU()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
#---设计模型
#---计算损失和更新
criterion = torch.nn.BCELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01)
#---计算损失和更新
#自己写了一个保存到csv表格的函数
import pandas as pd
def save(num, value, filepath):
dataframe = pd.DataFrame({'PassengerId':num,'Survived': value})
# 将DataFrame存储为csv,index表示是否显示行名,default=True
dataframe.to_csv(filepath, index=False, sep=',')
#---训练
if __name__=='__main__':
for epoch in range(10):
for i, data in enumerate(train_loader, 0):
# 1 Prepare data
inputs, labels = data
# 2 Forward
y_pred = model(inputs)
loss = criterion(y_pred, labels)
if epoch % 10 == 0:
print(epoch)
# 3 Backward
optimizer.zero_grad()
loss.backward()
# 4 Update
optimizer.step() #更新权重
#---训练
#print('w= ', model.linear1.weight.shape)
#print('b = ',model.linear1.bias.shape)#输出参数
y_pred = model(testset)
num = y_pred.shape[0] #测试集个数,按个数预测结果
test_value = []
for i in range(num):
if y_pred.data[i] < 0.5 :
test_value.append(0)
else:
test_value.append(1)
#print('测试结果为:', test_value)
# 892-1309
num = []
for i in range(892, 1310):
num.append(i)
save(num, test_value, 'value.csv')#输出到表格,然后上传到服务器就可以看排名了
#这是我自己写的第一个比赛程序,虽然排名只有200多,但还是很有成就感的。