医学分割综述 MedISeg(tricks,challenges and future directions)
MedISeg(tricks,challenges and future directions)
摘要:
MedISeg方面的内容通常侧重于主要贡献的介绍(例如,网络架构、训练策略和损失函数),而无意中忽略了一些边缘实现细节(也称为“技巧”),从而导致潜在的问题不公平的实验结果比较。在本文中,我们针对不同的模型实现阶段(即预训练模型、数据预处理、数据增强、模型实现、模型推理和结果后处理)收集了一系列MedISeg技巧,并通过实验探索其有效性这些技巧在一致的基线模型上。与仅平淡地关注分割模型的优势和局限性分析的纸质调查相比,我们的工作提供了大量可靠的实验,并且在技术上更具可操作性。随着对代表性 2D 和 3D 医学图像数据集的广泛实验结果,我们明确阐明了这些tricks的效果。此外,根据调查的技巧,我们还开源了一个强大的 MedISeg 存储库,其中每个组件都具有即插即用的优势。我们相信,这项里程碑式的工作不仅完成了对最先进的 MedISeg 方法的全面和补充调查,而且还为解决未来的医学图像处理挑战提供了实用指南,包括但不限于小数据集学习、类不平衡学习、多模态学习和域适应。
介绍:
近年来,由于图像处理深度学习技术的显着进步,MedISeg的性能有了很大的提高。高级主干网(例如,AlexNet、VGG、ResNet、DenseNet、MobilNet、ShuffleNet、ResNeXt HRNet、RegNet、ViT、Swin Transformer [38]、CMT、ConFormer、CvT)可以固有地学习丰富的语义特征表示,直接促进 MedISeg 识别能力。某些复杂的特征规则(例如,横向连接、残差映射、编码器-解码器方案、密集连接、特征金字塔和全局上下文聚合)也提高了性能。将这些复杂的元素集成到一个统一的 MedISeg 系统中是 MedlSystem 表现如此出色的主要原因。此外,一些训练策略(例如,协同训练、协同教学、协同学习和测试时间训练)和一些成熟的损失函数(cross-entropy loss, dice loss, Lovasz-softmax loss),也是影响模型性能不可或缺的组成部分。
然而,进展的迹象并不是单独提出的,它们通常与现有的实现混合在一起。特别是,目前,一个完整的 MedISeg 系统通常由大量的实现细节(包括一些非学习模型无关的预处理程序)组成,以实现理想的最先进的识别性能。不幸的是,论文中很少出现边缘实现描述(也称为“技巧”),或者仅在发布的代码中介绍(补充材料中存在一些)。

例如,如图 1 所示,在流行的 ResNet 架构(通常被视为 MedISeg 模型的主流骨干网络)的修改输入干中,三个累积的 3 × 3 卷积层(在图 1(b)) 用于替换输入词干中的原始 7×7 卷积层(在图 1 (a) 中),以降低计算成本。尽管这种细微的变化可以显着提高准确性,但很少有论文中明确提及这一点。因此,基于这种修改实现的性能与基于原始实现的性能的比较本质上是不公平的。
细节决定成败。在这项工作中,为了揭示trick对 MedISeg 模型的影响,如图2所示,根据一整套实施阶段,包括预训练模型(参考第 3.1 节)、数据预处理(参考第 3.2 节) 、数据增强(参考第 3.3 节)、模型实现(参考第 3.4 节)、模型推断(参考第 3.5 节)和结果后处理(参考第 3.6 节),我们首先收集了一系列实用且具有代表性的技巧在当前的 MedISeg 模型中被忽略。然后在具有代表性的卷积神经网络 (CNN) 骨干网络的帮助下,在包括传统的2D-UNet和 3D-UNet在内的一致分割基线模型上通过实验探索这些技巧的有效性,使得影响可以避免模型变体(即由于模型更改导致的性能变化)。与现有的论文驱动的技术调查仅仅平淡地关注图像分割模型的优势和局限性分析相比,我们的工作提供了大量可靠的实验结果,并且在技术上对未来的工作更具可操作性。基于四个医学图像数据集的广泛实验结果(即具有挑战性的 2D ISIC 2018 病变边界分割数据集、2D 结肠核识别和计数挑战数据集、3D肾肿瘤分割2019数据集和 3D 肝肿瘤分割挑战数据集),我们明确阐明了这些技巧的效果。此外,基于调查的技巧和使用的基线模型,我们还开源了一个强大的 MedISeg 存储库,其中每个组件都具有即插即用的优势。相信这项里程碑式的工作不仅完成了对SOTA的 MedISeg 方法的全面技术调查,而且还为解决未来的医学图像处理(尤其是密集图像预测任务),挑战(包括小数据集)提供了小数据集学习、类不平衡学习、多模态学习和域适应。
这项工作的主要贡献可以总结如下:
• 我们收集了一系列针对不同实施阶段的MedISeg的trick,并通过实验探索这些技巧在一致的 CNN 基线模型上的有效性。
• 我们明确阐明了这些trick的有效性,并且在 2D 和 3D 医学图像数据集上的大量可靠实验结果弥补了 MedISeg 中的实施疏忽。
• 我们开源了一个强大的 MedISeg 存储库,其中包括丰富的分割技巧,并且每个技巧都具有即插即用的优势。
• 这项里程碑式的工作将有助于后续在公平环境下比较 MedISeg 模型的实验结果。
• 这项工作将为广泛的医学图像处理,尤其是未来的分割挑战提供实践指导。
本文的其余部分结构如下:在第2节中,我们首先介绍初步的实验设置,包括基线模型、实验设置、使用的数据集和评估指标。在第3节中,我们根据顺序训练阶段介绍收集的技巧,并提供广泛的实验结果和详细的实验分析。在第4节中,全面讨论了包括这项任务的挑战在内的整篇论文。最后,在第5节中,我们做出结论并展示潜在的方向。
2.初步
2.1 基线
在这项工作中,为确保模型的全面性,我们选择常用且具有代表性的 2D-UNet和 3D-UNet作为我们的基线模型。这两个模型的详细信息如下:
2D-UNet:2D-UNet由编码器网络和解码器网络组成,已广泛应用于医学图像分割领域。编码器网络遵循经典的全卷积架构,因为它具有四个空间渐缩阶段。每个阶段由两个3×3卷积层组成,后跟一个整流线性单元(ReLU)激活函数和一个全局最大池化层(步长 S = 2)。以编码器网络的输出作为输入的解码器网络也有四个阶段,对应相同的空间编码器阶段。在每个解码器阶段,一个 2D 转置卷积算子首先通过双线性插值操作对特征图进行2倍上采样,然后依次部署两个3×3卷积层和一个ReLU激活函数。特别是,在最后一个解码器网络层中,输出特征图的通道大小通过2×2卷积层分配给所用数据集的类大小。
3D-UNet:3D-UNet具有与2D-UNet几乎相同的网络架构,因为它由3D编码器网络和3D解码器网络组成。3D-UNet 通常用于处理 3D 图像数据集进行分割。3D-UNet和2D-UNet 的实现差异是:i) 2D卷积层被3D卷积层替换;ii) 在编码器级和解码器级的同一级别之间增加横向连接,具有相同的空间和通道大小; iii) 在输入图像上实施强度归一化层。
2.2 数据集
在我们的实验中,为了实现全面的实验实现,并避免一个特定数据集的性能特异性,选择了四个具有代表性的医学图像数据集,它们是具有普通大小的二维数据集(即 ISIC 2018 病变边界分割数据集),一个具有小对象大小的2D数据集(即结肠核识别和计数挑战(CoNIC)数据集)、3D肾脏肿瘤分割2019 (KiTS19)数据集和3D肝脏肿瘤分割挑战 (LiTS)数据集。图3展示了这四个数据集的一些实验样本,每个数据集的详细介绍如下:
2D ISIC 2018。ISIC 2018 是计算机辅助诊断领域中最具代表性但最具挑战性的 2D 皮肤病变边界分割数据集之一,它由2594张JPEG皮肤镜图像和2594张PNG真实标签(GT)图像组成。在每个图像中,如图3(a)所示,一个或多个不同大小的病变区域包括在内。每个皮肤病变图像具有统一的600×450空间大小。对于这个数据集,我们只需要分割两类区域,即前景“病变”区域和“背景”区域。在我们的实验中,我们将这个数据集随机分成80%的图像用于训练集和20%的图像用于测试集。在每次交叉验证中,我们进一步从训练集中随机拆分10%作为验证集。
2D CoNIC。在2D CoNIC挑战数据集中,图像来自Lizard数据集,该数据集由六个核类别(即“上皮细胞”、“结缔组织细胞”、“淋巴细胞”、“浆细胞”、“中性粒细胞”和“嗜酸性粒细胞”)和一个“背景”。对于 Lizard 数据集,如图3(c)所示,每个原始图像都有一个 ground truth 标签,其中包含实例图、核类别、边界框分割掩码、和核数。在我们的实验中,我们使用分割掩码进行图像分割,我们只区分前景对象“核”和“背景”,即,它是中的二分类分割任务。在该数据集中,以RGB格式提供了4981个大小为 256×256的图像块。在我们的实验中,我们将所有图像随机分成 80%用于训练和20%用于测试。在每次交叉验证中,我们进一步从训练集中随机拆分10%作为验证集。
3D KiTS19。对于KiTS19,共有210张高质量注释患者的3D腹部计算机断层扫描图像被公开提供。如图3(b)所示,KiTS19由三个类别组成,包括“肾脏”、“肿瘤”和一个“背景”。我们可以观察到肾脏和肿瘤的位置在给定的图像中是相对固定的。在我们的实验中,我们验证了两种常见设置的二值分割性能,即设置 -i)前景“肾”和“背景”;设置 -ii) 前景“肿瘤”和“背景”。尽管KiTS19中提供了一些其他人体结构(例如,输尿管、动脉和静脉),但它们不在需要分割的范围内,即它们被统一视为背景。 KiTS19 中的每张图像和对应的 GT 掩码均以 NIFTI 格式提供,其中包括切片数(平均216个切片)、高度(512)和宽度(512)。继文献[74]、[103]之后,由于对GT质量的关注,从原始数据集中删除了案例15、23、37、68、125和133,其余204个案例随机分成80%进行训练,和20% 用于测试。在每个交叉验证中,我们进一步从训练集中随机拆分 10% 为验证集。此外,虽然其官网提供了额外的 90 个测试用例,但GT的mask不是公开访问的,因此我们忽略了这些用例。
3D LiTS 。肝癌是最常见的肿瘤之一,它在男性中的发生率(第五大最常见的癌症)通常远高于女性(第九大最常见的癌症)。为了提高病灶自动分割的进展,LiTS提出了一个基于对比增强腹部计算机断层扫描的基准。LiTS包含130次训练扫描和70次测试扫描。图3(d)中显示了一组横截面图像,其中红色区域代表肝脏区域。从左到右的图像是同一肝脏区域的一系列横截面。该数据集的图像原始以PNG格式提供,空间大小为 256 × 256,每个图像包含两个类别:“背景”和“肝脏”。继[106]、[107]之后,我们对肿瘤区域和肝脏区域进行相同的处理。在训练阶段,所有图像都被裁剪成 200 × 200 的空间大小。在每次交叉验证中,我们进一步从训练集中随机分出 10% 作为验证集。
2.3 设置
平台。本文中的所有实验均在具有NVIDIA GeForce RTX 2080 GPU的PyTorch深度学习平台上实现。在我们的实现中,为了尽可能避免编码缺陷,我们使用PyTorch官方函数来完成相应的操作,包括基础操作、损失计算、度量计算。
骨干。骨干网络是影响模型性能的最重要因素之一。考虑到数据集的大小和网络应用的成熟度,使用具有代表性的ResNet-50作为默认骨干网络,遵循全卷积网络架构的经典实现。还注意到主干网络的输入干是其通过累积卷积的原始实现,即图1(a)中的那个。
2D-UNet的实现。在ISIC 2018 数据集中用于病灶边界分割和CoNIC数据集中用于结肠核分割的2D训练图像统一调整为200×200的固定输入大小,并使用ImageNet数据集的平均值和标准差进行归一化。初始学习率设置为 0.0003。自适应矩估计(Adam)用作优化器,其中权重衰减设置为0.0005。整个模型使用200个训练epoch进行训练,批量大小为 32,验证集上的最佳模型的结果用于测试,我们采用常用的像素级交叉熵损失作为默认损失函数。
3D-UNet的实现。根据对KiTS19和LiTS的3D-UNet常用实验设置,对Hounsfield单位(CT中的亨氏单位)进行剪裁到 [−79, …, 304],体素间距按照[56]、[101]、[102]中的 3.22 × 1.62 × 1.62 mm3的系数重新采样。我们对横截面的CT进行下采样并对其重新采样,以将LiTS的所有数据的z轴间距调整为1mm。训练体素大小(即图像Patch大小)被重新采样为 96×96×96,正好可以塞进NVIDIA GeForce RTX 2080 GPU。随机梯度下降用作优化器,其中动量设置为0.9,权重衰减设置为0.0001。初始学习率设置为0.01,batch size 设置为 2。模型以100个epoch的端到端方式进行训练,验证集上最佳模型的结果用于测试中。交叉熵损失用作中的唯一损失函数。在推理阶段,我们使用50%的区域重叠(即48×48×48)进行patch重叠。
2.4 评估指标
为了评估模型性能,我们采用常用的Recall、Precision、Dice和IoU作为我们的主要指标。特别是,我们执行五折交叉验证来评估模型性能并得到平均结果,从而避免随机实验结果和过拟合问题。
3 方法和实验
我们将一个完整的 MedISeg 系统分为六个实施阶段;这些阶段是:
3.1 小节中描述的预训练模型;
3.2 小节中描述的数据预处理;
3.3 小节中描述的数据增强;
3.4 小节中描述的模型实现;
3.5 小节中描述的模型推断;
3.6 小节中描述的结果后处理。
基于每个阶段,经验性地探索了一组具有代表性的 MedISeg 技巧。请注意,所有实验没有具体声明都是在第2.3节中描述的初步设置上实施的。
3.1 预训练模型
预训练模型(即使用预训练的权重作为模型微调的初始化参数)提供了有利的参数,这样可以很容易地加速训练收敛,潜在的模型可以获得强大的泛化能力。不同的预训练模型有明显不同的影响,但这个技巧通常被忽视。例如,对于流行的 ImageNet 的预训练模型,作者一般说:“我们的网络是在 ImageNet上预训练的”,而在 ImageNet 上的预训练至少包含两种基本形式(即 1k 和 21k 版本)。只有阐明详细的预训练实施的实验结果比较是公平的。在本小节中,我们探讨了MedISeg上六种常用且公开发布的预训练权重,这些预训练权重可分为以下两个主要阵营:全监督权重(即 PyTorch 官方权重和面向模型的 ImageNet 1k/21k权重)和自监督权重(即SimCLR权重、MOCO权重和模型生成权重)。每个预训练权重的实现细节和 MedISeg 上的实验结果如下:
PyTorch官方权重。在PyTorch存储库中,有一些由 torchvision.models提供的主干预训练权重。这些预训练的权重是通过在ImageNet 1k数据集上为单标签图像分类任务训练相应的骨干网络获得的,其中“1K”表示该数据集由1000个常见场景类别组成。
面向模型的ImageNet 1k权重。除了PyTorch官方的预训练权重,模型创建者通常也会在 ImageNet上发布预训练的权重。例如,作为我们使用的骨干网络,可以通过在ImageNet 1k 数据集上训练ResNet-50进行图像分类来获得面向模型的ImageNet 1k权重。然后,我们将获得的训练权重用于下游视觉任务。
面向模型的ImageNet 21k权重。与ImageNet 1k相比,ImageNet 21k 是一个更通用和全面的数据集版本,总共有大约21000个对象类用于(弱监督或半监督或全监督)图像分类。因此,ImageNet 21k上的训练权重更有利于提高下游计算机视觉模型的识别性能。
SimCLR权重。SimCLR表明,在特征表示和对比学习损失之间引入可学习的非线性变换可以大大提高模型表示质量。基于这个假设,SimCLR主要包括三个实现步骤: 1)首先将输入图像分组为一些图像块; 2)然后对不同批次的图像patch实施不同的数据增强策略; 3)模型最终被训练以获得相同的图像块具有不同增强的相似结果,并相互排斥其他结果。在我们的工作中,我们使用在ImageNet 1k上训练的SimCLR权重在ResNet-50上进行分类。
MOCO权重。MoCo是经典的自监督对比学习方法之一。它旨在解决存储库中采样特征不一致的问题。为此,MoCo使用队列来存储和采样负样本;也就是说,它存储了用于训练的多个最近批次的特征向量。在其实现中,固定网络保持不变,在骨干网络的末端增加一个带有softmax层的线性层在无监督的情况下进行分类。在我们的工作中,我们使用在ImageNet 1K 上进行MOCO权重的训练,在ResNet-50上进行分类。
Model genesis(ModelGe) 权重。ModelGe是一种先进的自监督模型预训练技术,通常由四个变换操作(即非线性、局部像素混洗、向外填充和修复)组成,用于CT和MRI图像的单幅图像恢复。(论文总结:尽管模型Genesis的性能非常出色,但仍然需要一个用于医学图像分析的数据集(如ImageNet)。作者开发Genesis模型的目标之一就是帮助创建这样一个用于医学图像分析的大型标注数据集,因为基于一组小的专家标注好的数据集,从模型Genesis微调的模型将能够帮助快速生成未标记图像的初始粗略的标注,以供专家审查,从而减少标注工作并加速创建大型、强标注的医学图像数据集。综上所述,模型Genesis的设计目的并不是为了取代像ImageNet这样的用于医学图像分析的大型强标注数据集,而是为了帮助创建一个数据集)在其实现中,网络被训练以通过从变换后的图像块中恢复原始图像块来学习一般的视觉表示,其中这些变换操作的权重设置为:0.9的非线性,0.5的局部像素混洗,0.8的向外填充,0.2的in-painting。基于训练好的模型,得到的训练权重可以作为下游模型的预训练权重。
实验结果。在ISIC 2018、CoNIC和KiTS19上的实验结果如表1所示,在LiTS上的实验结果如表2所示。
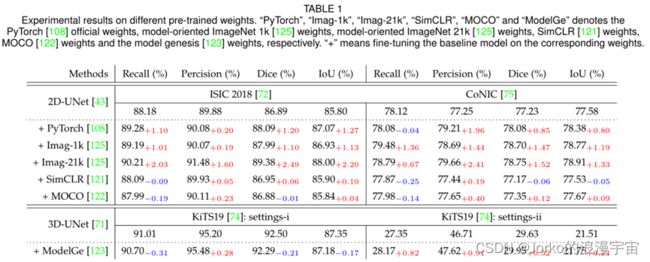
一般来说,我们可以观察到,与从头开始训练的基线模型(即不使用预训练的权重)相比,微调后的模型可以实现整体更好的性能。这一观察不仅验证了预训练权重的有效性,而且验证了不同预训练权重的效果是可变的。例如,与ISIC 2018上2D-UNet的基线结果相比,使用预训练的权重可以提高几乎所有评估指标下的性能。具体来说,fine-tuning可以分别带来 Recall、Precision、Dice和IoU的最大性能增益 2.03%、1.60%、2.49% 和 2.20%。这些最大性能获得了ImagNet-21k预训练权重的所有好处。该实验观察验证了ImagNet-21k的强大表示能力。此外,Pre-training模型在Precision上的性能增益相对较小,平均只有0.45%。我们可以从CoNIC数据集中获得类似的实验观察和结论。特别是,在CoNIC上,Recall的性能提升相对较小(平均只有 0.41%),而Precision的性能提升相对较大(即平均1.08%)。上述实验结果表明,相同的技巧可能对不同的数据集产生不同的影响。而且,使用相同的数据集,不同的评价指标也会表现不同。尽管模型性能在某些评估指标上有所下降,但我们认为这不是由于预训练的权重。由于预训练的权重是从自然场景中获得的,我们的任务是关于医学图像。自然场景和医学图像之间可能存在领域差距。未来可以通过使用预先训练的医学图像权重来解决这个问题。与KiTS19和LiTS 上的基线结果相比,使用已发布的ModelGe权重的微调3D-UNet可以在设置-ii (即,分割前景“肿瘤”和“背景”)上带来最大的性能提升分别提高了 Recall、Precision、Dice和 IoU 的 1.21%、0.91%、0.88% 和 1.23%。然而,在设置-ion KiTS19上,四分之三的性能略有下降,即-0.31%Recall、-0.21%Dice和-0.17%IoU。我们推测这可能是因为KiTS19中的肾脏区域对初始化参数更敏感。这一观察启发我们,在未来,不仅要考虑微调模型的网络架构之间的差异,还要考虑使用数据集的状态作为重要因素。这些3D实验结果表明,在具有相同数据集和评估指标的相同实现技巧下,不同的实验设置将导致性能差异。
3.2 数据预处理
由于深度 CNN 的 3D 医学图像的数据特异性(例如,图像模态和通用图像分辨率),数据预处理对于获得令人满意的识别性能是必要的。我们主要探讨3D-UNet中四种常用图像预处理技巧的有效性,即patching、过采样(OverSam)、重采样(ReSam)和强度归一化(IntesNorm) ) 。每种数据预处理策略的实现细节和在MedISeg上的实验结果如下:
Patching。某些特定类别的医学图像(例如,MRI和病理图像)在空间大小上往往非常大,并且在定量方面缺乏足够的训练样本。因此,直接使用这些图像训练 MedISeg 模型是不切实际的。相反,人们通常将整个图像重新采样到具有/不具有重叠的较小空间尺度的不同图像块中,这样可以以更少的 GPU 内存成本实现模型并且可以更好地训练。直观地说,Patching size 是影响模型性能的最重要因素之一。在我们的工作中,按照 3D-UNet上的实验设置,训练补丁大小设置为无重叠的96 × 96 × 96,在推理阶段设置为96 × 96 × 96,区域重叠50%。
过采样。 OverSam策略被提出来解决正负样本之间的类不平衡问题。OverSam主要用于少数类样本。目前,已经提出了一组OverSam方案,例如随机过采样、合成少数过采样 (SMOTE)、边界SMOTE和自适应合成采样。大量的实验结果证实 OverSam 方案不会影响模型斜率,但可以放大模型截距。在我们的工作中,我们遵循[102]中流行的过采样策略,即70%的选定训练样本来自随机图像位置,而30%的图像块保证至少包含一个训练前景类。这样,每个训练样本可以同时包含一个训练前景图像块和一个随机图像块。
重采样。提出了Image ReSam策略,以通过机器学习模型提高所用数据集的表示能力。因为可用的样本能力有时是有限的和异构的,所以可以通过随机/非随机 ReSam 策略获得更好的子样本数据集。 ReSam在其实现中主要包括四个步骤:1)间距插值; 2)窗口变换; 3) mask有效范围的选取,以及 4)生成子图像。基于重组的子样本数据集,可以训练出性能更好的识别模型。在我们的基线实现中,使用了常用的随机 ReSam 策略。为了证明它在 MedISeg 中的重要性,在本节中,我们通过在我们的实验中移除它(即 /o)来探索 ReSam 策略的效果,即直接对图像像素进行插值和缩放,使得实际距离由像素是一样的。
强度归一化。 IntesNorm是一种特定的归一化策略,主要用于医学图像。通常有两种常用的 IntesNorm 方法:所有模式的 z 评分和计算机断层扫描图像的另一种方法。在我们的工作中,我们主要通过在我们的实验中移除 KiTS19上的 IntesNorm(即 /o)来探索 IntesNorm 的有效性。继通用实现[102]、[155]之后,本文采用全局归一化方案,其中0.5%的前景体素用于裁剪和计算前景均值,99.5%的前景体素用于计算标准差。
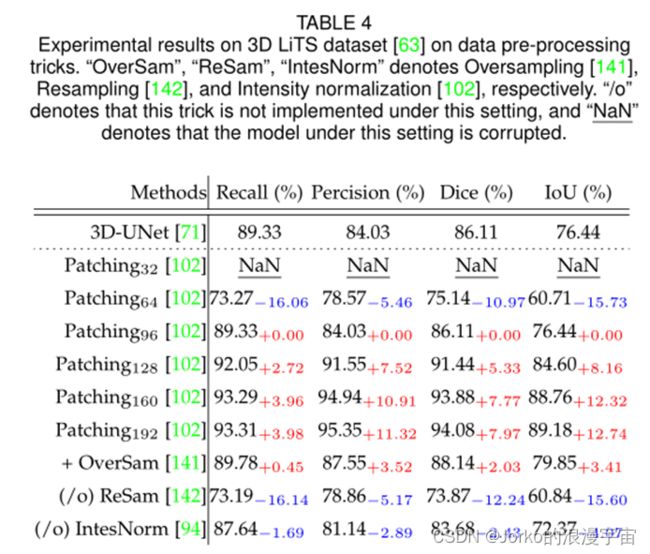
实验结果。 KiTS19和LiTS 的实验结果分别在表 3 和表 4 中给出。我们可以观察到,与 KiTS19 [136] 上的基线模型相比,这些预处理操作对 setting-ii 的影响比对 setting-i 的影响更敏感。更具体地说,1)补丁大小越大,模型的整体性能越好,其中基线模型基于 Patching96。当补丁大小相对较小时(例如,补丁大小设置为 32),分割模型甚至在 KiTS19 和 LiTS上都被破坏。当补丁大小设置为 128 时,KiTS19上的模型可以在 settingii上达到最佳性能,37.81% Recall、52.28% Precision、38.06% Dice 和 28.81% IoU,超过基线 10.46% Recall,分别为 5.57% 的Precision、8.43% 的Dice和 7.30% 的IoU。
LiTS 的实验结果表明,模型性能增益随着Patching大小的增加而逐渐增加。尽管与基线性能相比,Patching128 下的 setting-i 性能略有下降,但这是由于图像尺度上的实验设置而不是Patching方案。这一实验现象与之前论文的结论一致,建议我们应该使用GPU内存可以容纳的尽可能大的图像块大小。 2)在OverSam策略的帮助下,模型性能得到整体提升。特别是,KiTS19上的+ OverSam 可以带来显着的性能增益,在设置 i 上实现 0.84% Recall、0.43% Dice 和 0.73% IoU,并在设置 ii 上带来 9.11% Recall、6.98% Precision、6.06% Dice 和 5.05% IoU。 3) 在没有 ReSam的情况下,KiTS19和LiTS上的模型性能都显着降低。例如,在 KiTS19 上,该模型在 setting-i 上可导致 90.83% Recall、69.71% Precision、92.15% Dice 和 87.17% IoU 的性能下降。令人惊讶的是,在 setting-ii 下没有使用 ReSam 的情况下,模型完全损坏了。 4) IntesNorm对 setting-i 和 settingii 在KiTS19 的实验结果影响相对较弱。例如,在基线 3D-UNet [71] 上不使用 IntesNorm 在 setting-i 上降低 0.78% Recall、0.30% Dice 和 0.70% IoU 以及在设置ii上减低0.20% Recall 和 0.00% Dice 的最大模型性能。然而,IntesNorm 对 LiTS的实验结果有显着影响。这一现象表明,相同的方法在不同的数据集上具有不同的效果。从 2) 到 4) 的实验结果验证了 OverSam、ReSam 和 IntesNorm 在 MedISeg 上的重要性。

3.3 数据增强
数据增强是计算机视觉领域中最基本的技术之一。它通常用于处理定量方面训练样本不足的问题,可用于缓解过拟合问题,赋予强大的模型泛化能力,并赋予鲁棒性。特别是对于医学图像,数据增强通常用于解决数据短缺问题。用于MedISeg的数据增强方案主要可分为以下两类:基于几何变换的数据增强 (GTAug)和基于生成对抗网络(GAN)的数据增强(GANAug)。每种数据增强策略的实施细节和MedISeg上的实验结果如下:
GTAug。 GTAug被提出来消除训练图像中一些几何对象变化的影响,例如位置、比例和视角。普遍使用的 GTAug包括翻转、裁剪、旋转、平移、颜色抖动、对比度、低分辨率模拟、高斯噪声注入、混合图像、随机擦除、高斯模糊、混合和 cutmix 。在我们的工作中,我们选择了常用的随机亮度对比度(亮度限制 = 0.2,对比度限制 = 0.2,p = 0.5)、随机伽马(伽马限制 = (80, 120) 和p = 0.5)、CLAHE(对比度受限AHE(CLAHE)是自适应直方图均衡的一种变体,其中对比度放大受到限制,从而减少了这种噪声放大问题)、p = 0.5 的随机噪声、p = 0.5 的 gamma 调整,移位角度旋转(设置移位限制=0.1,刻度限制=0.1,旋转限制=45,p = 0.5), p = 0.5 的水平翻转,p = 0.5 的垂直翻转,p = 0.5 的随机缩放([0.85, 1.25]),随机旋转([90, 180, 279]),沿 X、Y、Z 轴的随机镜像MedISeg 模型中的方向。
通过将上述数据增强方案分为两组,我们实现了两种类型的数据增强,称为 GTAug-A(即像素级变换)和 GTAug-B(即空间级变换)。具体来说,在 2D-UNet上的实验中,GTAug-A 中使用了随机亮度对比度、随机 gamma 和 CLAHE,GTAug-B 中使用了shift scale旋转,水平翻转和垂直翻转。所有方案都使用其默认参数进行部署。对于 3D-UNet的实验,在 GTAug-A 中使用随机噪声和 gamma调整,在 GTAugB 中使用随机尺度、随机旋转和随机镜像,并使用它们的默认参数。
GANAug。数据增强的内在先决条件是将领域知识或其他增量信息引入训练数据集,从这个方面来看,GANAug可以被视为一个损失函数,它专注于引导网络生成一些接近源数据集域的真实数据。特别是,考虑到医学图像中的小数据集,GAN的生成模型拟合的数据分布优于判别模型。因此,GANAug适用于MedISeg任务。在我们的工作中,具有条件对抗网络的经典像素级图像到图像转换被用于默认设置的数据增强。
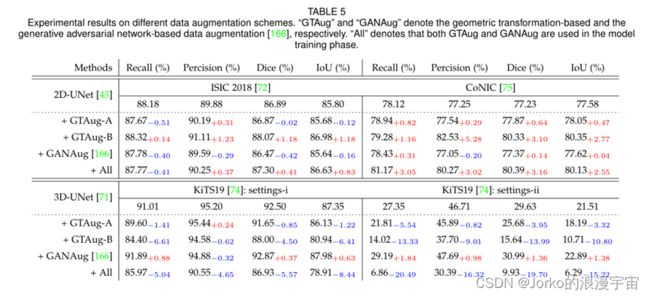
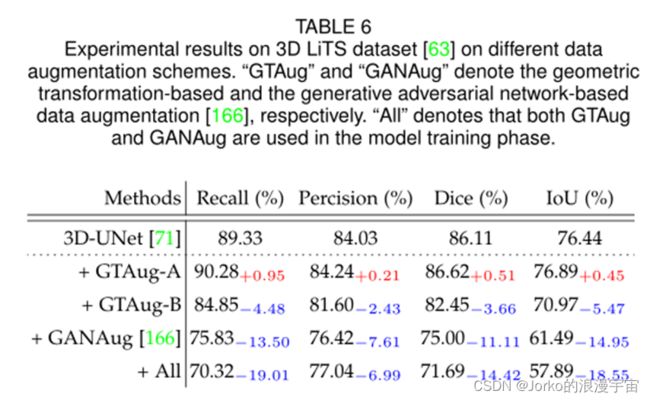
实验结果。 在表 5 和表 6 中,我们展示了不同数据增强方案的实验结果。我们可以观察到,与表 5 中 ISIC 2018上的基线 2D-UNet相比,GTAug-B可以根据所有评估指标显着提高了识别性能,而 GTAug-A在-0.51% Recall、-0.02% Dice 和 -0.12% IoU 三个指标下带来了轻微的性能下降。上述实验观察验证了像素级变换在 2D 医学图像上优于空间级变换(按理来说应该是空间变换优于像素级变换)。与 GTAug 相比,GANAug 实现了 87.78% Recall、89.59% Precision、86.47% Dice 和 85.64% IoU,这表示性能降低了 -0.40% Recall、-0.29% Precision、-0.42% Dice 和 -0.16% IoU 。 GANAug 的整体性能比 GTAug 的识别性能差。当 GTAug 和 GANAug 都在 ISIC 2018 上的 2D-UNet [43] 上实现时(即表 5 中的 + All),模型根据三个评估指标提高性能,即 0.37% 精度,0.41% Dice , 和 0.83% IoU,最终达到了 87.77% Recall、90.25% Precision、87.30% Dice、86.63% IoU 的性能。与在 CoNIC 上的基线 2D-UNet上的实验结果相比,我们可以观察到这些评估指标下的几乎所有值都得到了改善。特别是,只有 0.20%的精度降低。通过比较 ISIC 2018和CoNIC上的实验结果,我们可以观察到GTAug-B在两个数据集上的实验结果都优于 GTAug-A 和 GANAug,证明了移位尺度旋转、水平翻转和垂直翻转在医学图像分割中的重要性。此外,以上两组实验结果表明,在面对不同的数据集时,我们应该选择合适的数据增强技巧。在第3.1节中得到了相同的观察和结论。
对于3D KiTS19和LiTS的实验结果,一般来说,使用GANAug可以提高最大性能增益,而使用GTAug对KiTS19几乎没有好处。虽然LiTS的实验结果表明只有GTAug-A 是有益的,但GTAug-B和GANAug都对实验性能有害。例如,在KiTS19上的 3D-UNet 上使用GTAug 分别通过 Recall、Precision、Dice 和 IoU 降低了 -13.33%、9.01%、13.99% 和 10.80% 的最大性能。相比之下,实施 GANAug 在 setting-i 上实现了 0.88% Recall、0.37% Dice 和 0.63% IoU 的性能提升,在 setting-ii 上实现了 1.84% Recall、0.98% Precision、1.36% Dice 和 1.38% IoU 的性能提升。毫不奇怪,当 GTAug 和 GANAug 都在 KiTS19上实现时,该模型在 setting-i 上实现了 85.97% Recall、90.55% Precision、86.93% Dice 和 78.91% IoU 以及 6.86% Recall、30.39% 的较低性能精度,9.93% Dice 和 6.29% IoU on setting-ii。特别是,setting-ii 的结果具有最大的性能下降,在 Recall、Precision、Dice 和 IoU 上分别为 -20.49%、-16.32%、-19.70% 和 -15.22%。 LiTS的实验结果表明,GTAug-A 可以为每个评估指标带来性能提升,即分别为 0.95% Recall、0.21% Precision、0.51% Dice 和 0.45% IoU。相比之下,同时部署 GANAug 和 GTAug(即 +All)会带来最大的性能下降。这些在 KiTS19和 LiTS上的实验结果表明,我们在选择数据增强方法时需要考虑特定的数据集状态。更详细的分析可以在第 4 节中找到。
3.4 模型实现
MedISeg 模型通常包含许多实现细节,如今尤其如此。在实践中,每个不关心的变换都可能对性能产生潜在的显着影响。因此,模型实现技巧对于MedISeg模型至关重要。特别是对于实验结果的公平结果比较,需要保证对实施细节的充分解释。在我们的工作中,我们选择了三类常用的实现技巧并探索它们的分割效果。这三类是:深度监督(DeepS);类平衡损失(CBL),其中包括四个损失函数(即,CBLDice、CBLFocal、CBLTvers 和 CBLWCE);在线硬示例挖掘(OHEM);和实例规范化(IntNorm)。每个实现技巧的细节和MedISeg 上的实验结果如下:
DeepS。 DeepS是一种辅助学习技巧,在DSN中提出并用于的常见场景图像分类。这个技巧是通过以直接或间接的方式在一些中间隐藏层上添加辅助分类器或分段器来监督骨干网络的。可用于解决训练梯度消失或收敛速度慢的问题。对于图像分割,这个技巧通常是通过添加图像级分类损失来实现的。在我们的工作中,我们首先从最后三个解码器层中提取特征图,并使用 1×1 卷积层将病变掩码投影到相同的通道大小。然后,来自不同层的输出特征图通过双线性插值被上采样到与分割头网络的输入图像相同的空间大小。
CBL。 CBL 通常用于学习一个通用的类权重,即每个类的权重只与对象类别有关。与类不平衡数据集上的一些传统分割损失函数(例如,交叉熵损失)相比,CBL 可以提高模型表示能力。在使用的数据集中,CBL引入了有效样本数来表示所选数据集的预期体积表示,并通过有效样本数而不是原始样本数对不同类别进行加权。在本文中,我们主要探讨了四种常用的 CBL 损失函数对医学图像领域中类不平衡问题的影响,包括 Dice 损失(CBLDice)、Focal 损失(CBLFocal)、Tversky 损失(CBLTvers)和加权交叉熵损失(CBLWCE)。
OHEM。 OHEM的核心思想是首先通过损失函数过滤掉一些难学习的样本(即图像、物体和像素),这些选择的难样本都对识别任务有很大的影响。然后,将这些样本应用于模型训练过程中的梯度下降。不同视觉任务的大量实验结果表明,OHEM不仅高效,而且在各种数据集上表现良好。在我们的工作中,我们使用默认设置验证了 OHEM 在 2D 和 3D 医学数据集上的有效性。
实例规范化。 IntNorm 是一种流行的归一化算法,适用于对单个像素要求较高的识别任务。在其实现中,在计算统计归一化时,会考虑每个样本和样本单个通道的所有元素。在医学图像领域,使用 IntNorm的一个重要原因是,在训练过程中,batch size 通常设置为较小的值(尤其是对于 3D 图像),这使得使用批归一化无效。在本文中,我们通过在3D实验中将 IntNorm 替换为强度归一化来证明其效果。
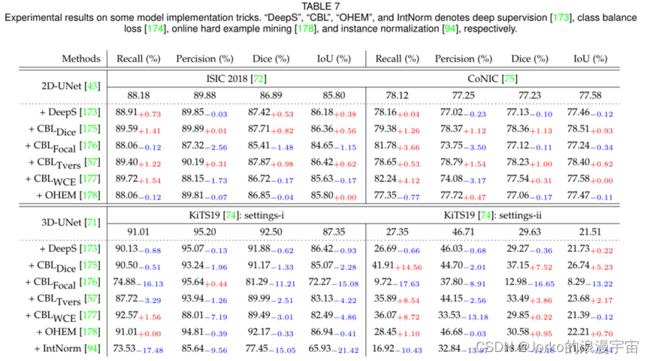

实验结果。 在 2D ISIC 2018 和 2D CoNIC以及 KiTS19和 3D LiTS数据集上使用 2D-UNet和 3D-UNet上的详细模型实现技巧的实验结果是在表 7 和表 8 中给出。总而言之,实施这些技巧在 2D 数据集上比在 3D 数据集上的识别准确度上带来了更显着的改进。例如,我们可以观察到,与 ISIC 2018上 2DUNet 的基线结果相比,实施 DeepS、CBLDice和 CBLTvers可以显着提高模型性能。具体来说,+CBLDice的性能提升为1.41% Recall、0.01% Precision、0.82% Dice 和 0.56% IoU。 +CBLTvers 的性能为 89.40% Recall、90.19% Precision、87.87% Dice 和 86.42% IoU。+CBLTvers 的性能提升为1.22% Recall、0.31% Precision、0.98% Dice 和 0.62% IoU。相比之下,其他技巧并未对2D ISIC 2018和2D CoNIC带来全面的性能提升。例如,ISIC 2018上的 +DeepS 的性能提升为 0.73% Recall、0.53% Dice 和 0.38% IoU。令人沮丧的是,+ CBLFocal、+ CBLWCE 和 + OHEM降低了两个 2D 数据集上大多数评估指标的模型性能。例如,+ CBLFocal 的性能降低为 -0.12% Recall、-2.56% Precision、-1.48% Dice 和 -1.15% IoU。 + CBLFocal 最终实现了 88.06% 的召回率、87.32% 的精度、85.41% 的骰子和 84.65% 的 IoU。
在 ISIC 2018和 CoNIC上的2D-UNet上可以一致地获得相同的实验结果观察和结论。特别是,我们可以看到 DeepS和 CBL在Recall上的表现都不佳。
此外,与在 ISIC 上的实验结果相比,对 CoNIC 的影响更为显着。原因可能是因为这些技巧最初是为 2D 数据集设计并在 2D 数据集上验证的,因此它们不适用于 3D 数据集。
在 KiTS19和3D LiTS上的 3D-UNet实验结果表明,这些模型实现技巧不能显着提高性能。特别是在 KiTS19上,+CBLDice 可以带来 14.56% Recall、7.52% Dice 和 5.23% IoU 的性能提升,而 +CBLTvers 在 settingii 上可以带来 8.54% Recall、3.86% Dice 和 2.17% IoU 的性能提升. OHEM也可以提高模型性能。
例如,KiTS19上的 + OHEM 在设置-ii 上实现了 28.45% 的召回率、30.58% 的骰子和 22.21% 的 IoU。表 7 中的最后一组实验结果表明,IntNorm [94] 在 3D KiTS19 数据集上的效果不如强度归一化的效果。具体来说,用强度归一化替换 IntNorm 可以降低 -17.48% Recall、-13.87% Precision、-15.05% Dice 和 -21.42% IoU 的最大性能。 2D 技巧不适用于 3D 数据集的现象提醒我们,在未来的模型设计中需要考虑数据集格式。此外,为了使上述技巧在 3D 数据集中发挥作用,我们可能需要在应用过程中部署它们之前对其进行修改。
3.5 模型推断
使用实现技巧是提高识别性能的重要策略。在我们的工作中,我们主要探索两种常用的推理技巧,即测试时间增强(TTA)和模型集成。这两个技巧的实现细节如下:
TTA。 TTA 是目前模型推理阶段流行的一种数据增强机制,用于提高模型的准确性。 TTA无需训练即可提高识别性能,具有即插即用的潜力。同时,它可以提高模型校准的能力,有利于视觉任务。在这项工作中,我们在三个方面遵循与 3.3 小节相同的图像增强策略:
1)在基线模型(即 TTAbaseline)上实施 TTA 策略。 2)在相同的数据增强策略 GTAug-A下,在基线模型上实现测试时间增强 GTAug-A(即 TTAGTAug-A)。 3)在相同的数据增强策略 GTAug-B下,在基线模型上实现测试时间增强 GTAug-B(即 TTAGTAug-B)。
集成。模型集成策略旨在联合多个训练好的模型,基于一定的集成机制在测试集上实现多模型融合结果,使得最终结果可以从每个训练好的模型中学习,提高整体泛化能力。常用的模型集成方法有投票、平均、堆叠和非交叉堆叠(混合)。在我们的工作中,我们首先独立地进行了 5 个具有不同随机种子(即 2022 - 2026)的训练集,在折叠验证中获得了 5 个不同的模型。然后,我们选择常用的投票和平均作为模型集成策略,分别称为 EnsVot 和 EnsAvg。
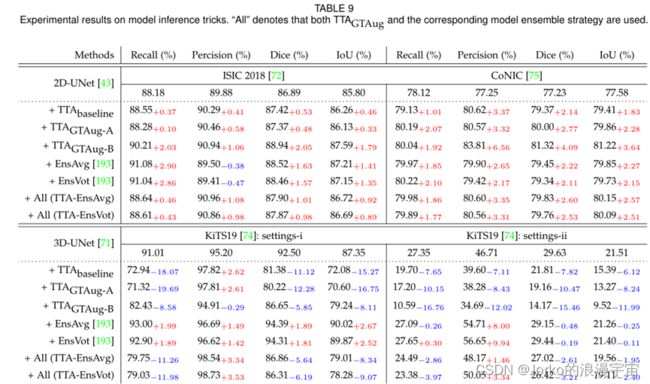

实验结果。 模型推理实验在 2D-UNet和 3D-UNet上进行。实验结果在表9和表10中给出。我们可以观察到,这些技巧可以在 ISIC 2018和 CoNIC上为2D-UNet带来显着的整体性能提升,但并非所有这些都是有益于KiTS19 和 LiTS上的3DUNet。例如,与基线 2D-UNet在ISIC 2018 数据集上的实验结果相比,最大性能增益分别为 2.90% Recall、1.08% Precision、2.05% Dice 和 1.79% IoU。在这些技巧中,TTAGTAug-B 的性能提升最大,而 TTAGTAug-A 的平均性能提升最小。特别是,+ EnsVot 和 + EnsAvg 在 Precision 上的性能降低了 -0.38% 和 -0.47%。与未在训练过程中使用数据增强技巧的 ISIC 2018上的实验结果相比,在训练和测试阶段使用数据增强技巧的模型显示出大致相同的性能提升。在 ISIC 2018上的模型集成方面,EnsAvg和 EnsVot都可以将模型性能提高 0.46% Recall、1.08% Precision、1.01% Dice、0.92% IoU 和 0.43%召回率、0.98% 的精度、0.98% 的 Dice 和 0.89% 的 IoU。对于使用 CoNIC数据集在 2D-UNet上的实验结果,我们可以观察到这些评估指标下的所有值都得到了改进,有力地证明了测试时间增强和模型集成技巧对医学图像分割的影响任务。与 KiTS19和 LiTS的基线结果相比,TTA 的实验结果没有显示出显着的性能提升。例如,在KiTS19 [74] 上,+ EnsAvg [193] 和 + EnsV ot [193] 可以在设置 i 的召回率、精度、Dice和 IoU 上将模型性能分别提高 1.99%、1.49%、1.89% 和 2.67% 。 + EnsAvg [193] 和 + EnsVot [193] 在 Recall、Precision、Dice 和 setting-i 上也可以分别将模型性能提高 1.89%、1.42%、1.81% 和 2.52%。此外,+ All 可以提高 setting-i 和 setting-ii 的 Precision。 3D 设置模型最终在 KiTS19上的设置 i 上的 Recall、Precision、Dice 和 IoU 上分别达到了 93.00%、98.73%、94.39% 和 90.02% 的最佳性能。 3D 设置模型最终在KiTS19上的设置i上的 Recall、Precision、Dice 和 IoU 上也分别达到了 27.65%、56.65%、29.44% 和 21.40% 的最佳性能。从 KiTS19和 LiTS上3D-UNet的实验结果来看,我们可以进行相同的观察并得出与 3.3 小节相同的结论。一般来说,在 MedISeg 模型实现中需要考虑数据增强方案本身的有效性,同时,数据集的状态(例如,模态、分布和病变大小)是该技巧是否有效的重要原因之一。
3.6 结果后处理
后处理操作的目的主要是通过不可学习的方法提高模型性能。例如,可以通过聚合全局图像信息来细化分割结果。在本文中,我们尝试研究医学图像分析领域中两种常用的结果后处理方案。这些方案都是最大分量抑制(ABLCS)和小面积去除 (RSA)。
ABL-CS。 ABL-CS 旨在基于对生物体物理特性的了解,去除分割结果中的一些错误区域。例如,对于心脏分割任务,我们都知道每个人只有一颗心脏,所以如果得到的mask中有小的分割区域,我们需要去除这些小区域。
RSA。对于 MedISeg,成像协议通常不变,因此每个实例分割掩码的区域也保持不变。基于这个物理特性,我们可以设置一个像素级的阈值来去除获得的分割掩码中一些太小(即低于给定阈值)的实例掩码。在我们的工作中,设置-i的阈值设置为5000,设置-ii的阈值设置为80,ISIC 2018设置为120,CoNIC和LiTS设置为10。这意味着分割区域中小于此阈值的所有掩码都将从最终结果中消除。
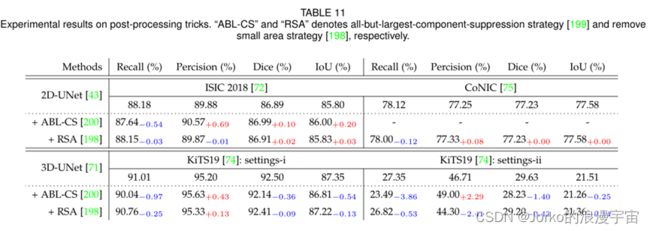
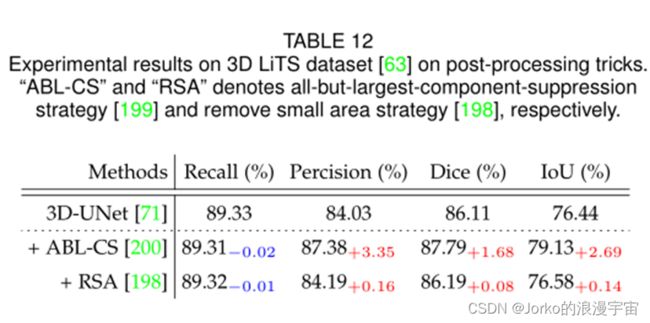
实验结果。 这些后处理策略的实验分别在 ISIC 2018和 CoNIC 数据集的 2D-UNet和 KiTS19和 LiTS数据集的 3D-UNet上进行。结果如表 11 和表 12 所示。我们可以观察到,与 ISIC 2018上的基线 2D-UNet 相比,在基线模型上实施ABL-CS可以提高四分之三个评估指标。例如,0.69% 的精度、0.10% 的Dice和 0.20% 的 IoU。在基线模型上实施RSA可以提高0.02% Dice 和 0.03% IoU。我们还可以观察到+RSA 对ISIC 2018的性能改进影响很小,例如,模型性能的提高几乎总是小于0.1%。由于 ABL-CS 不适用于 CoNIC数据集(我们不能假设每个输入图像中结肠核的数量),我们只在 CoNIC上实现 RSA。
我们可以观察到这些评估指标下的值变化很小。在 KiTS19上的 3DUNet上的实验结果表明,+ ABL-CS 可以在 setting-i 和 setting-ii 上分别将模型在 Precision 上的性能提高 0.43% 和 2.29%。此外,+ RSA 仅对设置 i 起作用,提高了 0.13% 的精度。以上 + ABL-CS 和 + RSA 在 KiTS19上的 3D 设置上的实验结果表明,这两种后处理方案在提高 Recall、Dice 和 IoU 的性能方面无效。在LiTS上的实验结果表明,这两种方案可以提高除 Recall 之外的所有评估指标。这些实验结果表明,相同的后处理操作在不同的数据集和不同的评价指标上的表现也不同。它还告诉我们,在选择后处理技巧时,我们需要注意数据集的状态,以及我们关注的评估指标。
4 讨论
在本节中,我们讨论与上述实验技巧相对应的潜在挑战和问题。
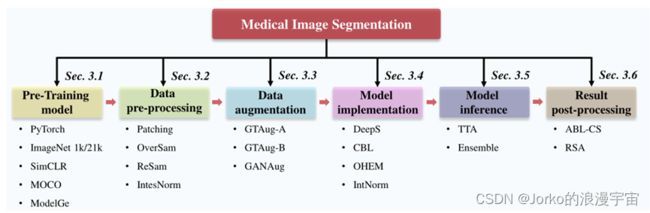
此外,我们还指出了这些技巧的局限性。如图2所示,一个完整的 MedISeg 系统可以分为六个主要实现阶段,即预训练模型、数据预处理、数据增强、模型实现、模型推理和结果后处理。我们在基于 CNN 的一致基线模型的每个阶段收集并探索了一系列实用但具有代表性的技巧。我们解决的潜在挑战包括但不限于小数据集学习、类不平衡学习、多模态学习和域适应。
4.1 挑战
通过在具有一致的基于 CNN 的主干的不同分割基线上实施这些收集的技巧,我们发现性能存在显着差异。
此外,大多数这些技巧在经验上不会导致过多的计算开销,这进一步强调了它们在图像分割任务中的潜在实用价值。在我们的工作中,值得注意的是,尽管性能差异可归因于基线实现的这些技巧,但性能改进是潜在的,因为一些基本但具有挑战性的医学图像处理问题在本质上得到了处理。尽管在部署和外观方面存在不同的表述,但从高级方法的目的来看,技巧解决的问题可能是相似的。
例如,我们观察到,根据大多数评估指标,微调现有的预训练权重可以大幅提高模型性能(参考表 1 和表 2)。首先,这一观察表明,自然场景上的预训练权重可以通过简单的微调策略转移到医学场景中,从而从根本上解决多模态学习和域适应(即自然场景之间的跨域表示和医疗场景)问题。尽管这些问题也可以通过一些高级迁移学习或元学习方法来解决,但微调是一种廉价的解决方案。
其次,它表明在更多数据样本(预训练数据集+微调数据集)上进行训练有助于提高模型性能,这对应于小数据集学习和过拟合的问题。这两个问题在具有非常强学习能力的模型(例如,基于转换器的模型)中更加突出,因为这些模型通常需要非常大的数据集来训练。
除了预训练模型,我们还可以对数据预处理(参考表 3和表 4)、数据增强(参考表 5 和表 6,以及表11 和表12)做出类似的观察和结论,以及测试时间增加(参考表 9 和表 10)技巧。具体来说,可以通过数据预处理和数据增强技巧来隐式增强实验数据集的表示能力,从而可以通过 Patching、OverSam 和 ReSam来缓解训练样本不足的挑战。小数据集学习的问题可以通过 Patching和OverSam来解决。类不平衡学习的问题可以通过 Patching、OverSam、ReSam 和 IntesNorm 来解决。幸运的是,这些技巧类别不会产生明显的计算成本,这证明这些技巧隐藏在其实现中。尽管在某些场景下,数据增强和测试时间增强策略并不能提高模型性能,但我们确实认为这不是因为这些策略本身难以处理医学图像,而是由数据集的特异性决定的。例如,在 CoNIC上的 3D-UNet 基线上实现实用的 TTAbaseline和 TTAGTAug并不能提高所有性能改进。这种现象的原因可能是人体组织的位置在给定的图像中是相对固定的(参考图 3(b))。但是一些基于几何变换的数据增强方案会破坏模型学习中的这种归纳偏差,导致分割精度差。
此外,不同的基于几何变换的数据增强方案之间也存在显著差异。如图4所示,我们在KiTS19和LiTS数据集上可视化了3D上每个单个数据增强方案的分割图示。
我们可以观察到,在KiTS19的一些评估指标上,多尺度和旋转提高了模型性能,而翻转的使用显著降低了模型性能。LiTS的结果表明,多尺度仅改进了一部分评估指标(例如,Dice),其余其他数据增强方案不起作用。这些单独的实验结果可以验证我们上面的假设,即具有非破坏性归纳偏差(即多尺度)的数据增强方法对具有相对固定的对象位置的图像更有利。相比之下,基于生成性对抗性网络的数据增强可以在不破坏此类归纳偏差的情况下改进数据集表示,从而在KiTS19上实现更好的性能(参考表5)。这些实验提醒我们,在未来的数据增强设计中,我们还需要考虑所用数据集的特定状态(例如,形态、分布和病变大小)。此外,类不平衡学习也是一个显而易见的话题,可以通过这些收集的技巧来处理(参考表7和表8)。总之,根据上述分析,我们的工作不仅完成了MedISeg综述,也是解决未来医学图像处理挑战(特别是与分割相关的任务)的实用指南,包括但不限于小数据集学习、类不平衡学习、多模态学习和域适应。
在对医学图像进行后处理时,还需要考虑人体组织的实际情况。自然场景图像与医学图像有显著差异。例如,在KiTS19上实现ABL-CS和RSA都降低了模型召回率(参考表5和表11)。这是因为,对于一些ISIC图像,不仅包括一个病变区域,还包括多个病变区域。RSA的简单实施可以去除一些小但存在的病变区域。例如,大多数人有两个肾脏,但有些人(由于手术、疾病或先天性)只有一个肾脏;在这种情况下,使用ABL-CS可以减少召回率的现象。
4.2限制
本工作存在一些限制。首先,所收集的技巧是有限的,即本文中收集和实验的技巧只是所有医学图像分割技巧的有限子集。这一点可以阐述为以下两个方面:
(1)我们调查了有限的技巧子集。我们只收集了相同阶段类别的代表性技巧。例如,有许多数据增强方案,例如平移、颜色抖动、对比度、低分辨率模拟、高斯噪声注入、混合图像、随机擦除、高斯模糊、混合和剪切混合。然而,考虑到医学图像处理的实际要求和实验数据集的特点,仅使用了其中的一小部分。
(2) 调查技巧的应用有限。在我们的工作中,我们选择了常用的2D UNet和3D UNet作为基线模型,并在四个代表性的2D和3D医学图像数据集上验证了这些技巧的有效性。然而,有大量的渐进式MedISeg模型在不同的层次上具有不同的骨干,但并未涉及。
(3) 调查的技巧效果有限。医学图像处理与临床实践密切相关,并涉及许多复杂的挑战性问题(例如,遮挡对象、模糊图像[、长尾问题、医学图像中的增量学习问题以及对象边界检测和细化)。我们只处理一些基本问题。
5 结论和未来方向
我们收集了不同实施阶段的MedISeg技巧,即预训练模型、数据预处理、数据增强、模型实施、模型推断和结果后处理。这些技巧几乎涵盖了用于医学图像分割任务的所有常见和基本方案;其他精心设计的技巧可以被视为这些技巧的更复杂的组合。在我们的工作中,为了避免实现变化带来的性能模糊,我们通过实验探索了收集的技巧在一致的2D UNet和3D UNet基线模型上的有效性。通过2D ISIC 2018、2D CoNIC、3D KiTS19和3D LiTS的实验结果,我们明确阐明了这些技巧的效果。此外,基于调查的技巧和基线模型,我们为2D和3D医学图像开放了强大的MedISeg存储库,其中每个组件都具有即插即用的优势。与现有的纸面分割调查相比,我们的工作可以提供广泛的实验,在技术上更具可操作性。
我们工作的重要贡献之一是明确探索这些收集到的技巧的效果。我们的工作不仅可以促进后续方法注意技巧,还可以实现公平的结果比较。这可能是必要的,尤其是在面对一些复杂任务,例如图像分割、目标检测和图像生成,网络架构变得越来越复杂的当下。此外,当我们将所有常用的技巧集成到一个统一的框架中时,MedISeg模型中的技巧之间的实现或抵消可能存在冲突,这可以为即将到来的细分管道提供经验和协调指导,包括网络架构、训练策略和损失函数。
未来,我们将朝以下方向努力:
(1)调查并开发更多关于MedISeg的技巧。在临床实践中,我们经常面临非常复杂的情况,MedISeg是一个与实践紧密结合的基础研究课题。因此,在现有基础上继续探索和开发一些更先进的MedISeg技巧,以满足不同问题的要求,具有重要的现实价值和意义。
(2)继续探索更多方法和数据集上技巧的有效性。在少量有限数据集上的实验结果不可避免地存在偏差。特别是当面临MedISeg问题时,不同的图像类型、分布和内部类的差异会影响特定技巧的有效性。为了能够更全面和公平地比较实验结果,有必要进行彻底的技巧调查。
(3)探索以技巧为灵感的模型设计。尽管技巧在现有出版物中很容易被忽略,但它
(4) 探索基于注意力的技巧。最近,Vision Transformer框架通过多头注意力机制具有强大的特征表示能力,在计算机视觉和医学图像分析领域受到越来越多的关注。然而,由于其复杂的内部架构和不成熟的实践应用(尤其是面对小数据集),Vision Transformer的进一步应用仍在探索中。因此,对Vision Transformer框架进行技巧研究也很有价值。