PaddleSeg飞桨高性能图像分割开发套件,端到端地完成从训练到部署的全流程图像分割应用。
PaddleSeg中集成了很多分割模型算法。
https://github.com/PaddlePaddle/PaddleSeg/blob/release/2.4/README_CN.md
产品矩阵如下图所示
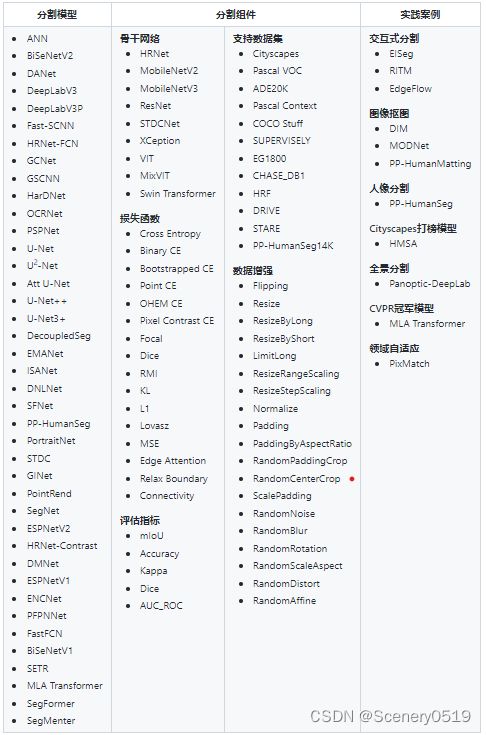
接下来详细说明安装PaddleSeg的过程和遇到的一些问题。
目录
- 安装Paddle
-
- 查看cuda版本号
- 安装paddle
- 检查paddle是否安装成功
- 遇到的问题
- 安装PaddleSeg
-
- 下载PaddleSeg代码
- 安装PaddleSeg依赖
- 确认环境安装成功
- 遇到的问题
- 跑通SegFormer模型
-
- 训练的命令
- 参数
- segformer_b5_cityscapes_1024x1024_160k.yml
- cityscapes_1024x1024.yml
- cityscapes.yml
- 可视化
- 多卡训练
- 遇到的问题
安装Paddle
需要根据cuda版本选择合适的paddle版本。
查看cuda版本号
- nvcc -V
- cat /usr/local/cuda/version.txt
注意:网上还有一种利用nvidia-smi查看cuda版本号,但是这个命令显示的是nvidia显卡最高支持的cuda版本,因此用这个命令查询到的并不是运行时的cuda版本号。
安装paddle
以安装cuda版本11.2适配的paddle为例。
python -m pip install paddlepaddle-gpu==2.3.2.post112 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
检查paddle是否安装成功
# 在您的Python解释器中确认PaddlePaddle安装成功
python
>>> import paddle
>>> paddle.utils.run_check()
# 确认PaddlePaddle版本
python -c "import paddle; print(paddle.__version__)"
# 如果命令行出现以下提示,说明PaddlePaddle安装成功
# PaddlePaddle is installed successfully! Let's start deep learning with PaddlePaddle now.
遇到的问题
paddle.utils.run_check()
这个命令虽然报了success,但是我出现了警告。
W1125 18:48:08.316130 3327857 parallel_executor.cc:642] Cannot enable P2P access from 7 to 6
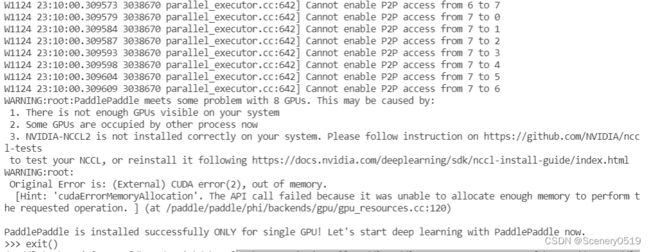
大概意思是多卡出现了问题。
我怀疑是因为当前服务器多卡有其他程序正在占用,所以会报这个警告。等服务器多卡空闲的时候再试一试。
安装PaddleSeg
pip install paddleseg
下载PaddleSeg代码
git clone https://github.com/PaddlePaddle/PaddleSeg
安装PaddleSeg依赖
pip install -r requirements.txt
确认环境安装成功
执行下面命令,并在PaddleSeg/output文件夹中出现预测结果,则证明安装成功
python predict.py \
--config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \
--model_path https://bj.bcebos.com/paddleseg/dygraph/optic_disc/bisenet_optic_disc_512x512_1k/model.pdparams\
--image_path docs/images/optic_test_image.jpg \
--save_dir output/result
遇到的问题
遇到了一些警告,说我安装的paddle适配的cudnn应该是8.1,但是现在机器中安装的cudnn版本是8.0,这可能会带来一些问题。

但是在PaddleSeg/output中已经出现了预测结果,表示可以正常使用。出现的只是一个警告,我就不管他了。
跑通SegFormer模型
训练的命令
在这里插入代码片export CUDA_VISIBLE_DEVICES=0 # 设置1张可用的卡
**windows下请执行以下命令**
**set CUDA_VISIBLE_DEVICES=0**
python train.py \
--config configs/segformer/segformer_b5_cityscapes_1024x1024_160k.yml \
--do_eval \
--use_vdl \
--save_interval 500 \
--save_dir output
参数
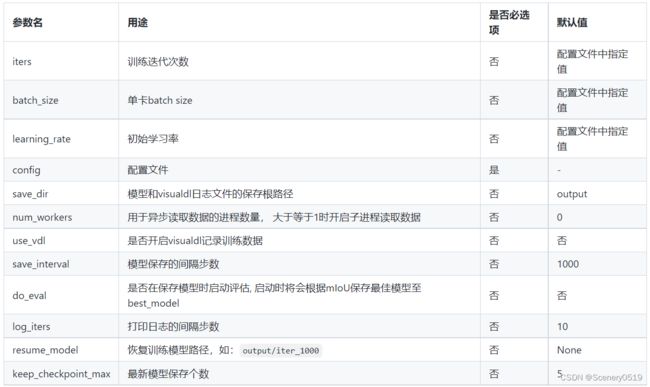
segformer_b5_cityscapes_1024x1024_160k.yml
重点参数说明:
- 在PaddleSeg的配置文件给出的学习率中,除了"bisenet_optic_disc_512x512_1k.yml"中为单卡学习率外,其余配置文件中均为4卡的学习率,如果用户是单卡训练,则学习率设置应变成原来的1/4。
- 在PaddleSeg中的配置文件,给出了多种损失函数:CrossEntropy Loss、BootstrappedCrossEntropy Loss、Dice Loss、BCE Loss、OhemCrossEntropyLoss、RelaxBoundaryLoss、OhemEdgeAttentionLoss、Lovasz Hinge Loss、Lovasz Softmax Loss,用户可根据自身需求进行更改。
_base_: '../_base_/cityscapes_1024x1024.yml'
batch_size: 1
iters: 160000
model:
type: SegFormer_B5
num_classes: 19
pretrained: https://bj.bcebos.com/paddleseg/dygraph/mix_vision_transformer_b5.tar.gz
optimizer:
_inherited_: False
type: AdamW
beta1: 0.9
beta2: 0.999
weight_decay: 0.01
lr_scheduler:
type: PolynomialDecay
learning_rate: 0.00006
power: 1
loss:
types:
- type: CrossEntropyLoss
coef: [1]
test_config:
is_slide: True
crop_size: [1024, 1024]
stride: [768, 768]
在文件的第一行,还看到了一个配置文件“cityscapes_1024x1024.yml”,找到这个文件,更改数据集的配置。
cityscapes_1024x1024.yml
_base_: './cityscapes.yml'
train_dataset:
transforms:
- type: ResizeStepScaling
min_scale_factor: 0.5
max_scale_factor: 2.0
scale_step_size: 0.25
- type: RandomPaddingCrop
crop_size: [1024, 1024]
- type: RandomHorizontalFlip
- type: RandomDistort
brightness_range: 0.4
contrast_range: 0.4
saturation_range: 0.4
- type: Normalize
val_dataset:
transforms:
- type: Normalize
第一行,还有一个配置文件“cityscapes.yml”,找到这个文件。
cityscapes.yml
dataset_root: 指明了数据集的路径,根据自己存放的数据集地址,将这个地方改成正确的地址。
(注意,dataset_root有两处,一个是在train_dataset下,一个是在val_dataset下)
batch_size: 2
iters: 80000
train_dataset:
type: Cityscapes
dataset_root: data/cityscapes
transforms:
- type: ResizeStepScaling
min_scale_factor: 0.5
max_scale_factor: 2.0
scale_step_size: 0.25
- type: RandomPaddingCrop
crop_size: [1024, 512]
- type: RandomHorizontalFlip
- type: RandomDistort
brightness_range: 0.4
contrast_range: 0.4
saturation_range: 0.4
- type: Normalize
mode: train
val_dataset:
type: Cityscapes
dataset_root: data/cityscapes
transforms:
- type: Normalize
mode: val
optimizer:
type: sgd
momentum: 0.9
weight_decay: 4.0e-5
lr_scheduler:
type: PolynomialDecay
learning_rate: 0.01
end_lr: 0
power: 0.9
loss:
types:
- type: CrossEntropyLoss
coef: [1]
可视化
当打开use_vdl开关后,PaddleSeg会将训练过程中的数据写入VisualDL文件,可实时查看训练过程中的日志。记录的数据包括:
- loss变化趋势
- 学习率变化趋势
- 训练时间
- 数据读取时间
- mean IoU变化趋势(当打开了do_eval开关后生效)
- mean pixel Accuracy变化趋势(当打开了do_eval开关后生效)
使用如下命令启动VisualDL查看日志
**下述命令会在127.0.0.1上启动一个服务,支持通过前端web页面查看,可以通过--host这个参数指定实际ip地址**
visualdl --logdir output/
多卡训练
export CUDA_VISIBLE_DEVICES=0,1,2,3 # 设置4张可用的卡
python -m paddle.distributed.launch train.py \
--config configs/segformer/segformer_b5_cityscapes_1024x1024_160k.yml \
--do_eval \
--use_vdl \
--save_interval 500 \
--save_dir output
或者用os命令在python文件中设置
import os
os.environ['CUDA_VISIBLE_DEVICES']='0,1,2'
遇到的问题
设置了“export CUDA_VISIBLE_DEVICES=0,1,2,3”多卡跑,就会不断地报错
server not ready, wait 3 sec to retry…
not ready endpoints:[‘0.1.68.146:38149’, ‘0.1.68.146:35087’, ‘0.1.68.146:56455’]
server not ready, wait 3 sec to retry…
not ready endpoints:[‘0.1.68.146:38149’, ‘0.1.68.146:35087’, ‘0.1.68.146:56455’]
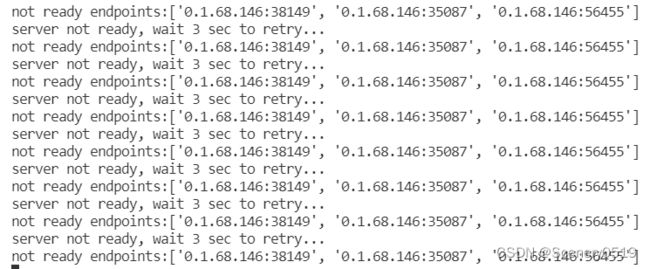
如果不设置“export CUDA_VISIBLE_DEVICES”,还是会报错,我怀疑是因为其他卡有别的进程在占用