【论文解读】YOLOR: 2021年YOLO系列目标检测的最强王者
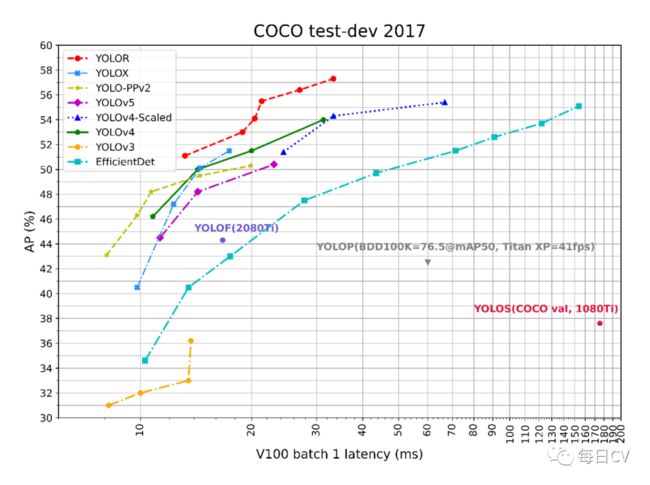
图表数据来源:
EfficientDet: https://arxiv.org/pdf/2011.08036.pdf
YOLOv3: https://arxiv.org/pdf/2011.08036.pdf
YOLOv4: https://github.com/AlexeyAB/darknet
YOLOv4-Scaled: https://github.com/WongKinYiu/ScaledYOLOv4
YOLO-PPv2: https://arxiv.org/pdf/2104.10419.pdf
YOLOv5: https://arxiv.org/pdf/2104.10419.pdf
YOLOX: https://github.com/Megvii-BaseDetection/YOLOX
YOLOR: https://github.com/WongKinYiu/yolor
YOLOF: https://arxiv.org/pdf/2103.09460.pdf
YOLOS: https://arxiv.org/pdf/2106.00666.pdf
YOLOP: https://arxiv.org/pdf/2108.11250.pdf
图表统计时间:2021年11月-12月
本篇文章是对目标检测YOLO系列的性能总结,主要介绍了2021年YOLO系列的最高精度YOLOR是怎样炼成的。
YOLOR出自论文You Only Learn One Representation: Unified Network for Multiple Tasks,受人类学习方式(使用五官,通过常规和潜意识学习,总结丰富的经验并编码存储,进而处理已知或未知的信息)的启发,本篇论文提出了一个统一的网络来同时编码显式知识和隐式知识,在网络中执行了kernel space alignment(核空间对齐)、prediction refinement(预测细化)和 multi-task learning(多任务学习),同时对多个任务形成统一的表示。结果表明神经网络中引入隐式知识有助于所有任务的性能提升,进一步的分析发现隐式表示之所以能带来性能提升,是因为其具备了捕获不同任务的物理意义的能力。
paper: https://arxiv.org/abs/2105.04206
code: https://github.com/WongKinYiu/yolor
论文作者 | Kin-Yiu Wong等
一、YOLOR思想动机
 图1:人可以根据同一幅输入图像回答不同问题,本文也旨在训练一个单一的神经网络来服务于多个任务。
图1:人可以根据同一幅输入图像回答不同问题,本文也旨在训练一个单一的神经网络来服务于多个任务。
如图1所示,人可以从多个角度来分析同一个目标,然而通常训练CNN时只给予了一个角度,也就是说针对某一个任务得到的CNN特征很难适用于其他问题。作者认为造成上述问题的原因主要是模型只提取了神经元特征而丢弃了隐式知识的学习运用,然而就像人脑一样隐式知识对分析各种各样的任务是非常有用的。
人类对隐式知识的学习通常通过潜意识,然而并没有系统的定义怎样学习和获得隐式知识。对于神经网络而言,一般将浅层特征定义为显式知识,深层特征定义为隐式知识。本文将直接可观察的知识定义为显式知识,隐藏在神经网络中且无法观察的知识定义为隐式知识。
 图2:多目的神经网络架构。(a)不同任务对应不同模型;(b)不同任务共享骨干网络,使用不同的输出头;(c)本文提出的统一网络:融合显式知识和隐式知识的一个表征服务多个任务。
图2:多目的神经网络架构。(a)不同任务对应不同模型;(b)不同任务共享骨干网络,使用不同的输出头;(c)本文提出的统一网络:融合显式知识和隐式知识的一个表征服务多个任务。
如图2所示,本文提出了一个统一的网络来集成显式知识和隐式知识,通过学习统一的表达,使得各个子表示能够适用于不同任务。基于前人工作的理论基础,本文结合压缩感知和深度学习来构建统一网络。
本文主要贡献如下:
1. 提出了一个可同时完成多种任务的统一网络,它通过融合显式知识和隐式知识学习一个可以完成多个任务的统一表征,提出的网络可以有效的提升模型的表现,仅增加千分之一不到的计算成本;
2. 通过 kernel space alignment(核空间对齐)、prediction refinement(预测细化)和 multi-task learning(多任务学习)来完成隐式知识的学习,并验证了其有效性;
3. 分别讨论了隐式知识的建模方式,包括向量、神经网络、矩阵分解,并验证了这些方式的有效性;
4. 证实了所提出的内隐表征学习方法能够准确地对应于特定的物理特征,并以视觉的方式进行了呈现;还证实了如果算子符合目标的物理意义,它可以用来整合隐式知识和显式知识,并会产生乘数效应;
5. 与SOTA比较,YOLOR能够实现和目标检测Scaled-YOLOv4-P7一样的精度,但是推理速度快了88%。
二、隐式知识学习
2.1 隐式知识如何工作
隐式表征![]() 是与观察不相关的,它可以是一个常量tensor
是与观察不相关的,它可以是一个常量tensor ![]() 。下面将介绍隐式知识是如何作为一个常量tensor在多个任务中作用的。
。下面将介绍隐式知识是如何作为一个常量tensor在多个任务中作用的。
流形空间约简
 图3:流形空间约简
图3:流形空间约简
一个好的表征应该能够在它所属的流形空间中找到一个合适的投影,并有助于后续目标任务的顺利完成。如图3所示,如果在投影空间中利用超平面能成功地对目标类别进行分类,那将是最好的结果。在图3所示例子中,可以利用投影向量的内积和隐式表示来达到降低流形空间维度的目的,并有效地完成各种任务。
核空间对齐
 图4:核空间对齐
图4:核空间对齐
在多任务和多头神经网络中,核空间不对齐是经常发生的问题,图4(a)展示了一个多任务多头神经网络核空间不对齐的例子。为了解决这个问题,如图4(b)所示,可以对输出特征和隐式表征进行加法和乘法运算,这样就可以对核空间进行变换、旋转和缩放,以对齐神经网络的每个输出核空间。该方法广泛用于多个领域,比如说FPN中大目标与小目标的特征对齐、知识蒸馏中大模型与小模型的整合、处理zero-shot域迁移等问题。
更多功能和处理方式
 图5:更多功能和处理方式
图5:更多功能和处理方式
除了可以应用于不同任务的功能外,隐式知识还可以扩展为更多的功能。如图5所示,通过引入加法,可以使神经网络预测中心坐标的偏移;还可以引入乘法来自动搜索锚框的超参数集,这是基于锚框的目标检测器经常需要的;此外,可以分别使用点乘和concat来执行多任务特征选择并为后续计算设置前提条件。
2.2 隐式知识统一网络建模
本节通过比较卷积网络和所提的统一网络,解释为什么在训练多任务网络中引入隐式知识是重要的,并详述实现细节。
隐式知识的表示
Conventional Networks:
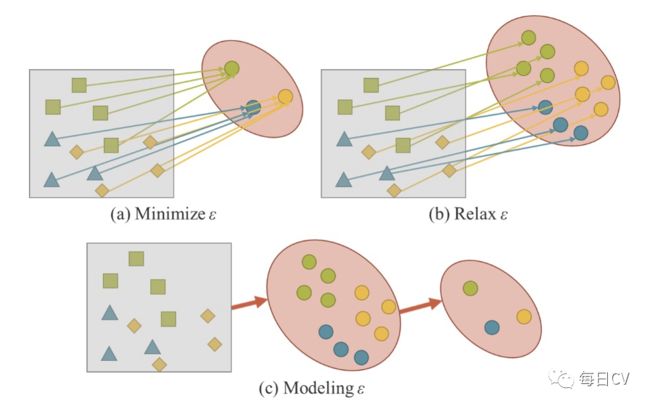 图6:建模误差项
图6:建模误差项
传统神经网络可以由以下公式(1)表示,其中  为目标,
为目标, 为观测量,
为观测量, 表示神经网络操作,
表示神经网络操作, 是神经网络学习的参数,
是神经网络学习的参数, 是误差项:
是误差项:

训练过程中最小化 ,这表示我们期望同一目标的不同观测值是 所得到的子空间中的一个点,如图6(a)所示。换言之,我们期望得到的解空间只对当前任务  有区别,对各种潜在任务中除 以外的任务是不变的,其中
有区别,对各种潜在任务中除 以外的任务是不变的,其中 ![]() 。(解释:以图6(a)为例,不同颜色的圆形解空间只对不同颜色的形状任务
。(解释:以图6(a)为例,不同颜色的圆形解空间只对不同颜色的形状任务 ![]() 有变化,比如绿色方形对应绿色圆形,而蓝色三角形对应结果就变化成了蓝色圆形,但是对绿色方形类内的不同观测值(潜在任务),如位置的变化,其对应的解空间是不变的。)
有变化,比如绿色方形对应绿色圆形,而蓝色三角形对应结果就变化成了蓝色圆形,但是对绿色方形类内的不同观测值(潜在任务),如位置的变化,其对应的解空间是不变的。)
对于更通用的神经网络,我们希望获得的表征可以服务于其他所有属于  的任务(既各种潜在任务),因此需要松弛 ,以便能够在流形空间上同时找到每个任务的解,如图6(b)所示。然而,上述要求使得我们不可能用简单的数学方法,如一个热独向量的最大值或欧氏距离的阈值来求解 。为了解决这个问题,我们必须对错误项进行建模,以便为不同的任务找到解决方案,如图6(c)所示。
的任务(既各种潜在任务),因此需要松弛 ,以便能够在流形空间上同时找到每个任务的解,如图6(b)所示。然而,上述要求使得我们不可能用简单的数学方法,如一个热独向量的最大值或欧氏距离的阈值来求解 。为了解决这个问题,我们必须对错误项进行建模,以便为不同的任务找到解决方案,如图6(c)所示。
Unified Networks:
为了训练所提出的统一网络,作者将显式知识和隐式知识结合起来对误差项进行建模,然后用它来指导多用途网络的训练过程,训练公式如下:
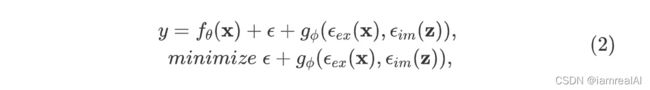
其中 ![]() 和
和 ![]() 分别建模来自观察量 的显式误差和来自隐编码
分别建模来自观察量 的显式误差和来自隐编码  的隐式误差,
的隐式误差,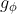 这是一个特定于任务的操作,用于从显式知识和隐式知识中组合或选择信息。
这是一个特定于任务的操作,用于从显式知识和隐式知识中组合或选择信息。
有一些现有的方法来整合显性知识到 ,所以将公式(2)重写为公式(3):
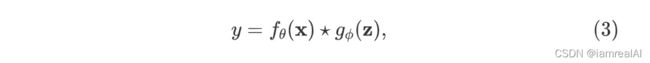
其中 ![]() 表示一些可以融合 和 的操作,本文所使用的操作包括相加、相乘、concat。
表示一些可以融合 和 的操作,本文所使用的操作包括相加、相乘、concat。
如果把误差项的推导过程推广到处理多个任务,可以得到如下等式:

其中 ![]() 是一个用于不同任务 的隐式潜编码集合,
是一个用于不同任务 的隐式潜编码集合,  是用于从
是用于从  生成隐式表征的参数,
生成隐式表征的参数, 是用来从显示表征和隐式表征的不同组合计算最终的输出参数。
是用来从显示表征和隐式表征的不同组合计算最终的输出参数。
对于不同的任务,可以使用以下公式获得所有 ![]() 的预测:
的预测:

对于所有任务,以一个共同统一的表征 ![]() 开始,然后进入基于任务而不同的隐式表征
开始,然后进入基于任务而不同的隐式表征 ![]() ,最后用任务特定的判别器
,最后用任务特定的判别器 ![]() 完成不同的任务。
完成不同的任务。
隐式知识的建模
本文提出的隐式知识可用图7所示几种方式建模:
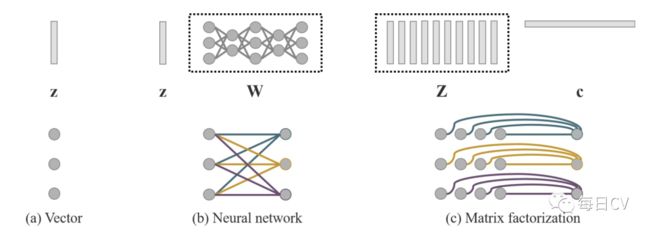 图7:本文提出的3种建模隐式知识的方式,第一行显示了这三种不同建模方法的形成过程,第二行显示了它们对应的数学属性。(a)向量:单基,每个维度彼此独立;(b)神经网络:单基或多基,维度之间相互关联;(c)矩阵分解:多基,每个维数彼此独立。
图7:本文提出的3种建模隐式知识的方式,第一行显示了这三种不同建模方法的形成过程,第二行显示了它们对应的数学属性。(a)向量:单基,每个维度彼此独立;(b)神经网络:单基或多基,维度之间相互关联;(c)矩阵分解:多基,每个维数彼此独立。
向量/矩阵/张量

如图7(a)利用向量/矩阵/张量 直接作为隐式知识的先验,直接作为隐式表示。此时,必须假设每个维度彼此独立。
神经网络

如图7(b)利用向量/矩阵/张量 作为隐式知识的先验,然后利用权重矩阵  进行线性或非线性组合形成隐式表示。此时,必须假设每个维度相互依赖。也可以使用更复杂的神经网络来生成隐式表示。或者用马尔可夫链来模拟不同任务之间隐式表示的相关性。
进行线性或非线性组合形成隐式表示。此时,必须假设每个维度相互依赖。也可以使用更复杂的神经网络来生成隐式表示。或者用马尔可夫链来模拟不同任务之间隐式表示的相关性。
矩阵分解

如图7(c)利用多个向量/矩阵/张量作为隐式知识的先验,这些隐式先验基 和系数  构成隐式表示。还可以进一步对 进行稀疏约束,将其转化为稀疏表示形式。此外,还可以对 和 施加非负约束,将它们转化为非负矩阵分解(
构成隐式表示。还可以进一步对 进行稀疏约束,将其转化为稀疏表示形式。此外,还可以对 和 施加非负约束,将它们转化为非负矩阵分解( ![]() )形式。
)形式。
训练
假设模型没有任何的先验隐式知识,既隐式知识对显式表示 ![]() 没有任何影响。当融合操作为相加和concat时,初始化隐式先验
没有任何影响。当融合操作为相加和concat时,初始化隐式先验 ![]() ,如果融合方式为相乘,则初始化为
,如果融合方式为相乘,则初始化为 ![]() ,其中
,其中  是一个接近0的很小的值, 和 都通过反向传播算法进行训练更新。
是一个接近0的很小的值, 和 都通过反向传播算法进行训练更新。
推理
由于隐式知识与观察量 无关,无论内隐模型 ![]() 有多复杂,在执行推理阶段之前,它都可以被简化为一组常数张量,也就是说隐式信息不会影响算法的计算复杂度。当隐式操作是通过相乘进行,如果后续层是卷积层,本文使用公式(9)进行整合操作;当操作是相加,如果前面的层是卷积层且没有激活函数,则使用公式(10)进行整合。
有多复杂,在执行推理阶段之前,它都可以被简化为一组常数张量,也就是说隐式信息不会影响算法的计算复杂度。当隐式操作是通过相乘进行,如果后续层是卷积层,本文使用公式(9)进行整合操作;当操作是相加,如果前面的层是卷积层且没有激活函数,则使用公式(10)进行整合。

三、实验
3.1 实验设置
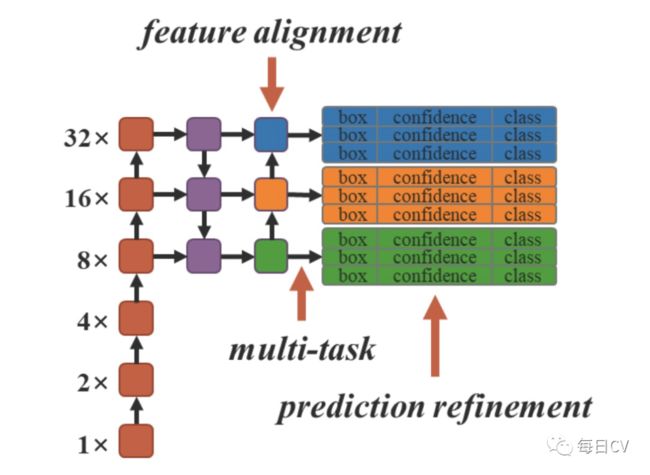 图8:统一网络模型结构
图8:统一网络模型结构
本文通过FPN中的feature alignment(特征对齐)、目标检测中的prediction refinement(预测细化)、单模型中的multi-task learning(多任务学习)来应用implicit knowledge(隐式知识)(注:本文的多任务学习指特征嵌入、多标签图像分类和目标检测)。使用YOLOV4-CSP作为baseline model,隐式知识添加位置如图8所示,所有训练超参数与Scaled-YOLOv4一致。
3.2 FPN特征对齐
使用简单的向量隐式表征和加法算子,在FPN的每一个特征映射层添加隐式知识进行特征对齐,各个指标获得到了有意义的提升,如表1所示。
 表1:特征对齐消融研究
表1:特征对齐消融研究
3.3 目标检测预测细化
使用简单的向量隐式表征和加法算子,在YOLO的每一个输出层添加隐式知识进行预测细化,大部分指标都获得到了一定的增益,如表2所示。
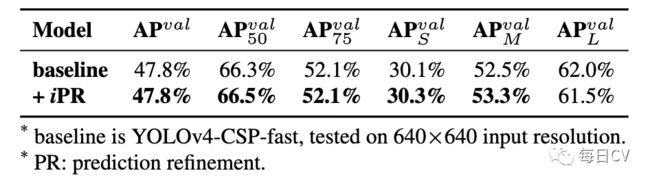 表2:预测细化消融研究
表2:预测细化消融研究
图9展示了隐式表征的引入如何影响检测结果(注:论文中对如何影响的检测结果并么有做进一步解释)。
 图9:预测细化学习到的隐式表征的值
图9:预测细化学习到的隐式表征的值
3.4 多任务规范表征
当需要同时训练一个被多个任务共享的模型时,由于损失函数的联合优化过程是必须执行的,因此在执行过程中往往会出现多方相互拉动的情况,这种情况将导致最终的整体性能比单独训练多个模型然后集成它们要差。为了解决这个问题,作者提出为训练多任务训练一个规范的表征,通过给每个任务分支引入隐式表征增强表征能力,表3展示了使用简单的向量隐式表征和加法算子进行不同联合训练方式的结果, (检测和特征嵌入联合训练,引入加法隐式表征)取得了最好的对比结果。
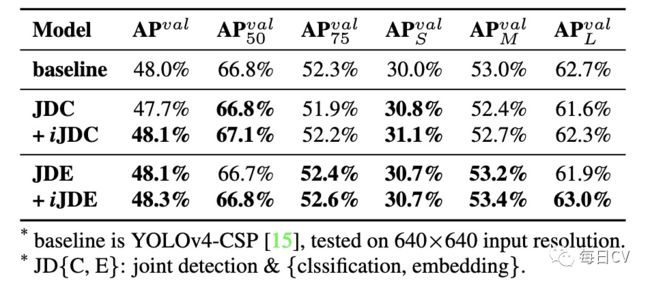 表3:多任务联合学习消融研究
表3:多任务联合学习消融研究
3.5 隐式知识建模不同算子比较
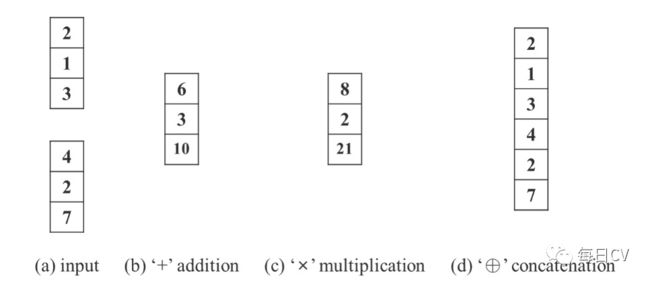 图10:隐式建模算子:(b)相加(c)相乘(d)串联
图10:隐式建模算子:(b)相加(c)相乘(d)串联
表4显示了图10中不同算子融合显式表征与隐式表征的结果。
在特征对齐实验中,相加与串联(concat)操作能够提升性能表现,相乘有所下降。特征对齐的实验结果完全符合其物理特性,因为它必须处理全局偏移和所有单个簇的缩放。
在预测细化实验中,由于concat会增加输出维度,所以只比较相加与相乘的效果,在这里相乘的效果更好。这是由于中心偏移在执行预测时使用加法解码,而锚框尺度使用乘法解码,而中心坐标是以网格为界的,影响较小,但人工设置的锚框具有较大的优化空间,因此改进更为显著。
 表4:不同算子消融研究
表4:不同算子消融研究
基于上面的分析,作者设计了另外两个实验。在第一个实验中,作者通过锚框聚类来划分特征空间,并执行相乘细化,第二个实验中,作者只在width和height上执行相乘细化。结果如表5所示,发现经过相应的修改,各项指标都得到了提高。实验表明,在设计显式知识与隐式知识的结合时,首先要考虑结合层的物理意义,以达到更好的效果。
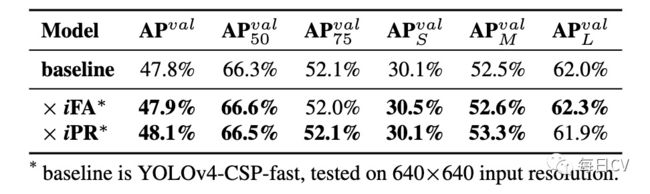 表5:不同算子消融研究
表5:不同算子消融研究
3.6 隐式知识建模不同方式比较
本文尝试了向量、神经网络和矩阵分解三种建模隐式知识的方式,发现三种建模方式都带来了不同程度的性能提升,其中矩阵分解效果最好,不同建模隐式知识的潜力也值得进一步挖掘。
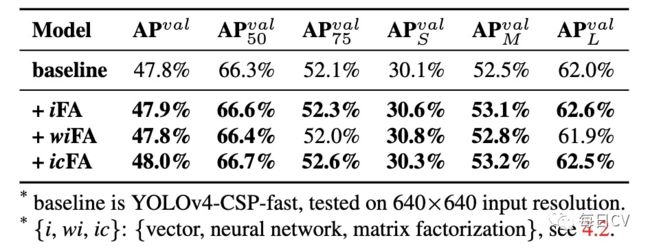 表6:不同建模方式消融研究
表6:不同建模方式消融研究
3.7 隐式知识模型分析
如表7和图11所示,引入隐式知识,仅增加不到万分一的参数量和计算量,模型性能得到有意义的提升,同时收敛更快。
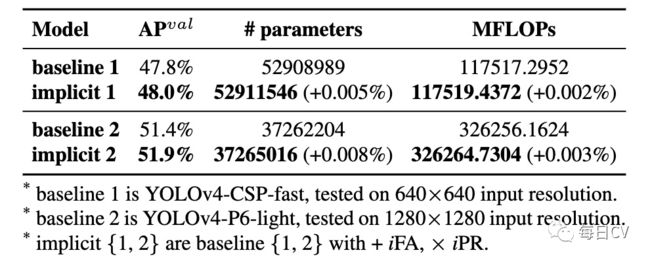 表7:模型信息比较
表7:模型信息比较
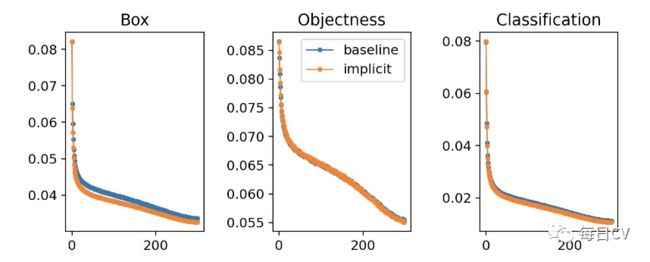 图11:学习曲线比较
图11:学习曲线比较
3.8 隐式知识提升目标检测
按照Scaled-YOLOv4训练过程,先从头训练 300 epochs,然后微调150 epochs,表8展示了目标检测中引入隐式知识的优势。表9与SOTA方法进行了比较,值得注意的是YOLOR并没有增加额外的数据和标注做训练,只通过引入隐式知识的统一网络,YOLOR不仅达到了足可以和SOTA方法比拟的结果,而且速度非常快。
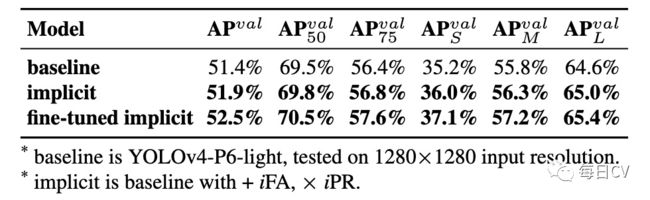 表8:隐式知识增益
表8:隐式知识增益
 表9:SOTA比较
表9:SOTA比较
四、总结
本文介绍了如何构造一个隐式知识与显示知识相结合的统一网络,并通过目标检测YOLOR证明了它在单模型结构下对多任务学习的有效性。在未来,作者计划将把训练扩展到多模型和多任务,如图12所示。
 图12:多任务多模型统一网络
图12:多任务多模型统一网络
五、点评
1. 本文借鉴人学习知识的方式,提出了神经网络的显式知识学习和隐式知识学习,视角还是比较新颖的。
2. 隐式知识学习的实现方式巧妙的使用了神经网络的一些常规操作,但其实现方式是否真正达到了隐式知识学习的构想,虽有一定的实验论证,但值得更进一步的挖掘探讨。
3. 引入隐式知识的YOLOR取得了精度的提升,但论文中提升的精度还是比较有限的,但从其速度翻倍的角度应该也某种程度上体现了所提方法的有效性吧,另外下面这幅对比图中的精度top3来自github中的实现,还并未体现在论文中,期待作者后续的更多工作。
如果说2021年YOLO系列的最强王者是YOLOR,那么2022又会出现哪些挑战者,带来哪些精彩的工作,是否会有你的身影(致敬YOLO留给变体的命名机会已经不多了),让我们翘首以盼拭目以待!