【天池】零基础入门数据挖掘-心跳信号分类预测(GPU版本)
【天池】零基础入门数据挖掘-心跳信号分类预测(GPU版本)
- 为什么要写这篇文章?
-
- 赛题背景
- 赛题分析
- 赛题环境
- 代码剖析
- 比赛成绩
- 结束语
为什么要写这篇文章?
本文献给Python初学者,里面的编程方式还比较稚嫩,欢迎提出宝贵意见。如果在GPU运行过程中遇到问题,欢迎留言交流。文中的程序部分借鉴了天池中两位大神的代码,向两位致敬。欢迎链接过去Star他们。
【心跳信号分类预测】冠军攻略–小小靓仔
零基础入门数据挖掘-心跳信号分类预测_top5思路–余睿
这是一个天池长期赛,目前这个代码最好成绩是217名,还未上榜。会在这和大家持续更新排名进展。个人主要是无线通信+AI方向,后面多分享这个方向的。
赛题背景
赛题以心电图心跳信号数据为背景,要求选手根据心电图感应数据预测心跳信号所属类别,其中心跳信号对应正常病例以及受不同心律不齐和心肌梗塞影响的病例,这是一个多分类的问题。通过这道赛题来引导大家了解医疗大数据的应用,帮助竞赛新人进行自我练习、自我提高。
赛题链接

赛题分析
这是机器学习中的监督学习问题,所有标签已经打好,信号已经标准化在0-1之间,是一个典型的多分类问题(四分类)。人体信号中比较麻烦的是信号预处理和标准化等,这个属于入门赛,已经先帮助选手消化好了。但实际做项目可就没有这么幸运了,可能这就是入门赛和实际工作中项目之间的差异之一吧。
医疗数据中还有一个特点是正常样本多,病患样本少。这个问题在本赛题中也体现出来了。正常样本(分类1)超过了10000例,而某种心脏疾病的病例数才几百例。这也是分类问题中经常遇到的,最好对小样本进行数据增强,稍后验证有效的方法出来后再补充。
赛题环境
pytorch 1.8.1
python 3.8
cuda 11.2
cudnn 8.1.0
硬件 RTX 3060
神州战神Z8游戏本
代码剖析
虽然目前该代码仅排名217/3749,这个代码主要是为初学者展示代码结构,降低入门门槛。因为是长期赛,排名会和大家实时更新。
导入资源包,初始化参数
import numpy as np
import torch
import csv
...
batch_size = 256
train_split = 0.9
valid_split = 0.1
patient = 20
epo = 130训练集验证集划分常规操作(这部分代码要感谢余睿)
# 定义数据适配器,用于加载数据至pytorch框架
class DataAdapter(Data.Dataset):
def __init__(self,X,Y):
super(DataAdapter,self).__init__()
self.X = torch.FloatTensor(X)
self.Y = torch.LongTensor(Y)
def __getitem__(self,index):
return self.X[index,:],self.Y[index]
def __len__(self):
return len(self.X)
def read_data(batch_size,train_split,valid_split):
signal = []
label = []
train_data = r'./train.csv' # 训练文件路径
weight = [0,0,0,0]
with open(train_data,'r') as f:
reader = csv.DictReader(f)
for line in reader:
signal.append([float(num) for num in line['heartbeat_signals'].split(',')]) # 滤波后的数据
label.append(int(float(line['label']))) # 标签
weight[int(float(line['label']))] += 1 # 各标签的权重
dataset = DataAdapter(signal,label) # 构造数据集
train_size = int(len(signal) * train_split)
valid_size = len(signal) - train_size
train_dataset,valid_dataset = Data.random_split(dataset,[train_size,valid_size]) # 随机划分训练集和验证集
train_loader = Data.DataLoader(train_dataset,batch_size = batch_size,shuffle = True,num_workers = 0) # 加载DataLoader
valid_loader = Data.DataLoader(valid_dataset,batch_size = batch_size,shuffle = True,num_workers = 0)
return train_loader,valid_loader,[len(label)/ii for ii in weight]
# 定义该函数用于重新打乱训练集和验证集
def shuffle_data(train_loader,valid_loader,valid_split,batch_size):
train_dataset = train_loader.dataset.dataset # 获取训练集的数据集
valid_dataset = valid_loader.dataset.dataset
X = torch.cat((train_dataset.X,valid_dataset.X),0) # 拼接数据集
Y = torch.cat((train_dataset.Y,valid_dataset.Y),0)
dataset = DataAdapter(X,Y) # 重新生成数据集
train_dataset,valid_dataset = Data.random_split(dataset,[len(dataset) - int(len(dataset)*valid_split),int(len(dataset)*valid_split)]) # 重新划分训练集和验证集
train_loader = Data.DataLoader(train_dataset,batch_size = batch_size,shuffle = True,num_workers = 0)
valid_loader = Data.DataLoader(valid_dataset,batch_size = batch_size,shuffle = True,num_workers = 0)
return train_loader,valid_loader
# 定义训练函数
def train_model(train_loader, model, criterion, optimizer, device):
model.train()
train_loss = []
train_acc = []
for i, data in enumerate(train_loader, 0):
# inputs,labels = data[0].cuda(),data[1].cuda()
inputs, labels = data[0].cuda(), data[1].cuda() # 获取数据
outputs = model(inputs) # 预测结果
_, pred = outputs.max(1) # 求概率最大值对应的标签
num_correct = (pred == labels).sum().item()
acc = num_correct / len(labels) # 计算准确率
loss = criterion(outputs, labels) # 计算loss
optimizer.zero_grad() # 梯度清0
loss.backward() # 反向传播
optimizer.step() # 更新系数
train_loss.append(loss.item())
train_acc.append(acc)
return np.mean(train_loss), np.mean(train_acc)
# 定义测试函数,具体结构与训练函数相似
def test_model(test_loader, criterion, model, device):
model.eval()
test_loss = []
test_acc = []
for i, data in enumerate(test_loader, 0):
# inputs,labels = data[0].cuda(),data[1].cuda()
inputs, labels = data[0].cuda(), data[1].cuda()
outputs = model(inputs)
loss = criterion(outputs, labels)
_, pred = outputs.max(1)
num_correct = (pred == labels).sum().item()
acc = num_correct / len(labels)
test_loss.append(loss.item())
test_acc.append(acc)
return np.mean(test_loss), np.mean(test_acc)这里CNN模型框架要感谢状元小小靓仔,个人修改了一下,结果变得像幼儿园小朋友写的了。希望大佬也可以多多指点,不吝赐教。对和我一样的初学者有一个好处就是比较易懂。
# 定义模型结构
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.conv1 = nn.Conv1d(in_channels = 1,out_channels = 16,kernel_size = 3,stride = 1,padding = 1)
self.conv2 = nn.Conv1d(16,32,3,1,1)
self.conv3 = nn.Conv1d(32,64,3,1,1)
self.conv4 = nn.Conv1d(64,64,5,1,2)
self.conv5 = nn.Conv1d(64,128,5,1,2)
self.conv6 = nn.Conv1d(128,128,5,1,2)
self.maxpool = nn.MaxPool1d(3,stride=2)
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
self.softmax = nn.Softmax(dim=1)
self.dropout = nn.Dropout(0.5)
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(6400,256)
self.fc21 = nn.Linear(6400,16)
self.fc22 = nn.Linear(16,256)
self.fc3 = nn.Linear(256,4)
def forward(self,x):
x = x.view(x.size(0),1,x.size(1))
x = self.conv1(x) #nn.Conv1d(in_channels = 1,out_channels = 32,kernel_size = 11,stride = 1,padding = 5)
x = self.relu(x)
x = self.conv2(x)
x = self.relu(x)
x = self.conv3(x)
x = self.relu(x)
x = self.conv4(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.conv5(x)
x = self.relu(x)
x = self.conv6(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.dropout(x)
x = self.flatten(x)
x1 = self.fc1(x)
x1 = self.relu(x1)
x21 = self.fc21(x)
x22 = self.relu(x21)
x22 = self.fc22(x22)
x2 = self.sigmoid(x22)
x = self.fc3(x1+x2)
return x后面就是预测结果的代码。
def predict_ali_testset(batch_size, model, device):
'''
该函数用于生成预测文件
'''
ipath = r'./' # 输入数据文件路径
opath = r'./' # 输出提交文件路径
signal = []
...以及主体代码__main__,这个框架可以用pycharm模板生成的。一般把def函数全都写到main前面去。GPU需要注意的就是把模型和数据都.cuda()。然后最终要从GPU取回到CPU。这块我也在借鉴代码阶段,不知道是否发挥了GPU3060全部潜能,还请多指教。
if __name__ == '__main__':
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
print(device)
model = CNN().cuda() # 初始化模型,
criterion = nn.CrossEntropyLoss()
print('******start loading data******')
start = time.time()
train_loader, valid_loader, weight = read_data(batch_size, train_split, valid_split)
early_stopping = EarlyStopping(patient, verbose=False)
end = time.time()
run = end - start
print('[1]load: %.5f sec' % run)
print('******start shuffling data******')
train_loader, valid_loader = shuffle_data(train_loader,
valid_loader, valid_split, batch_size) # 打乱训练集及验证集
optimizer = optim.Adam(model.parameters(), lr=0.0001) # 使用Adam优化算法
clr = CosineAnnealingLR(optimizer, T_max=150) # 使用余弦退火算法改变学习率
best_loss = 10
print('******start training model******')
start = time.time()
for epoch in range(epo):
time_all = 0
start_time = time.time()
train_loss, train_acc = train_model(train_loader, model, criterion, optimizer, device) # 训练模型
clr.step() # 学习率迭代
time_all = time.time() - start_time
valid_loss, valid_acc = test_model(valid_loader, criterion, model, device) # 测试模型
print('- Epoch: %d - Train_loss: %.5f - Train_acc: %.5f - Val_loss: %.5f - Val_acc: %5f - T_Time: %.3f 当前学习率:%f'
% (epoch, train_loss, train_acc, valid_loss, valid_acc, time_all, optimizer.state_dict()['param_groups'][0]['lr']))
if valid_loss < best_loss:
best_loss = valid_loss
#print('Find better model in Epoch {0}, saving model.'.format(epoch))
torch.save(model.state_dict(),'./best_model.pt') # 保存最优模型
torch.cuda.empty_cache()
end = time.time()
run = end - start
print('[2]train: %.5f sec' % run)
print('******start predicting data******')
model = CNN()
model.load_state_dict(torch.load('./best_model.pt')) # 加载模型参数
model.eval()
model.cuda()
predict_ali_testset(batch_size, model, device) # 生成预测文件
print('[3] prediction done')
print('the end')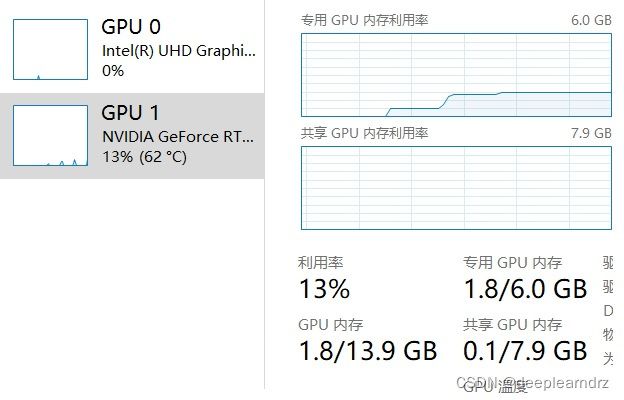
比赛成绩
长期赛目前成绩217/3749,后面改进的方向将会是对CNN模型的修改,如何使CNN模型更加能够掌握心电信号特征。如何将信号物理模型融入AI模型,physics-based DNN是很有意思的学问,也是体现专业领域人士不被AI所替代裁员展现出来的最后的倔强。
会实时和大家汇报比赛排名和更新算法,欢迎指点。

结束语
您的支持将支付我GPU运行的电费账单,可以一直将喜欢的AI比赛进行下去。
排名更新至194/3753
排名更新至140/3755
排名更新至97/3767
排名更新至91/3804
[1]https://doi.org/10.3390/diagnostics12030654
[2]https://doi.org/10.1038/s41598-020-77599-6
[3]ARRHYTHMIA CLASSIFICATION WITH HEARTBEAT-AWARE TRANSFORMER lepu医疗
[4]http://dx.doi.org/10.1109/TBME.2015.2468589