【菜菜的sklearn课堂笔记】逻辑回归与评分卡-用逻辑回归制作评分卡-重复值和缺失值处理
视频作者:菜菜TsaiTsai
链接:【技术干货】菜菜的机器学习sklearn【全85集】Python进阶_哔哩哔哩_bilibili
在银行借贷场景中,评分卡是一种以分数形式来衡量一个客户的信用风险大小的手段,它衡量向别人借钱的人(受信人,需要融资的公司)不能如期履行合同中的还本付息责任,并让借钱给别人的人(授信人,银行等金融机构)造成经济损失的可能性。一般来说,评分卡打出的分数越高,客户的信用越好,风险越小。
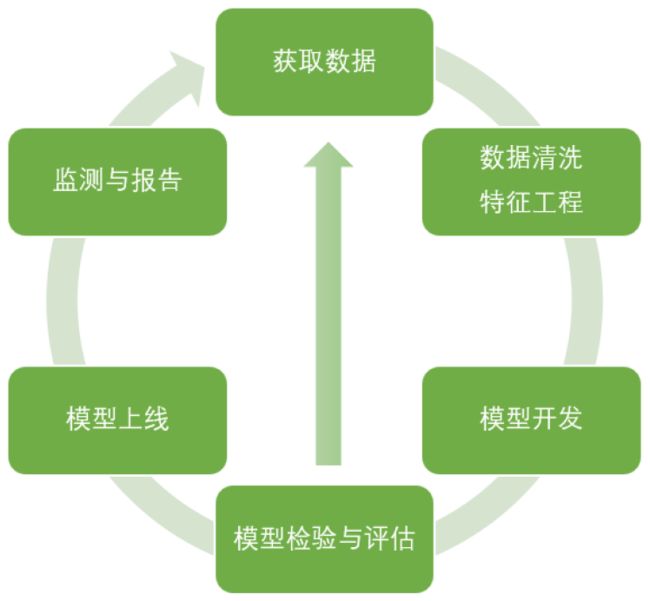
“评分卡”其实是指A卡,又称为申请者评级模型,主要应用于相关融资类业务中新用户的主体评级,即判断金融机构是否应该借钱给一个新用户,如果这个人的风险太高,我们可以拒绝贷款。
今天我们以个人消费类贷款数据,来为大家简单介绍A卡的建模和制作流程,由于时间有限,我们的核心会在”数据清洗“和“模型开发”上。模型检验与评估也非常重要,但是在今天的课中,内容已经太多,我们就不再去赘述了。
导库,获取数据
# 其实日常在导库的时候,并不是一次性能够知道我们要用的所有库的。通常都是在建模过程中逐渐导入需要的库。
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression as LR
在银行系统中,这个数据通常使来自于其他部门的同事的收集,因此千万别忘记抓住给你数据的人,问问她/他各个项都是什么含义。通常来说,当特征非常多的时候(比如几百个),都会有一个附带的excel或pdf文档给到你,备注了各个特征都是什么含义。这种情况下其实要一个个去看还是非常困难,所以如果特征很多,建议先用算法降维,具体参考“2.2.2 逻辑回归中的特征工程”,剩余的特征再看是什么含义,再人工筛选
探索数据与数据预处理
在这一步我们要样本总体的大概情况,比如查看缺失值,量纲是否统一,是否需要做哑变量等等。其实数据的探索和数据的预处理并不是完全分开的,并不一定非要先做哪一个,因此这个顺序只是供大家参考。
data = pd.read_csv(r'D:\ObsidianWorkSpace\SklearnData\rankingcard.csv',index_col=0)
data.shape
---
(150000, 11)
data.info()
---
<class 'pandas.core.frame.DataFrame'>
Int64Index: 150000 entries, 1 to 150000
Data columns (total 11 columns):
SeriousDlqin2yrs 150000 non-null int64
RevolvingUtilizationOfUnsecuredLines 150000 non-null float64
age 150000 non-null int64
NumberOfTime30-59DaysPastDueNotWorse 150000 non-null int64
DebtRatio 150000 non-null float64
MonthlyIncome 120269 non-null float64
NumberOfOpenCreditLinesAndLoans 150000 non-null int64
NumberOfTimes90DaysLate 150000 non-null int64
NumberRealEstateLoansOrLines 150000 non-null int64
NumberOfTime60-89DaysPastDueNotWorse 150000 non-null int64
NumberOfDependents 146076 non-null float64
dtypes: float64(4), int64(7)
memory usage: 13.7 MB
| 特征 | 含义 |
|---|---|
| SeriousDlqin2yrs | 出现 90 天或更长时间的逾期行为(即定义好坏客户) |
| RevolvingUtilizationOfUnsecuredLines | 贷款以及信用卡可用额度与总额度比例 |
| age | 借款人借款年龄 |
| NumberOfTime30-59DaysPastDueNotWorse | 过去两年内出现35-59天逾期但是没有发展得更坏的次数 |
| DebtRatio | 每月偿还债务,赡养费,生活费用除以月总收入 |
| MonthlyIncome | 月收入 |
| NumberOfOpenCreditLinesAndLoans | 开放式贷款和信贷数量 |
| NumberOfTimes90DaysLate | 过去两年内出现90天逾期或更坏的次数 |
| NumberRealEstateLoansOrLines | 抵押贷款和房地产贷款数量,包括房屋净值信贷额度 |
| NumberOfTime60-89DaysPastDueNotWorse | 过去两年内出现60-89天逾期但是没有发展得更坏的次数 |
| NumberOfDependents | 家庭中不包括自身的家属人数(配偶,子女等) |
去除重复值
现实数据,尤其是银行业数据,可能会存在的一个问题就是样本重复,即有超过一行的样本所显示的所有特征都一样。有时候可能时人为输入重复,有时候可能是系统录入重复,总而言之我们必须对数据进行去重处理。尤其是银行业数据经常是几百个特征,所有特征都一样的可能性是微乎其微的。即便真的出现了如此极端的情况,我们也可以当作是少量信息损失,将这条记录当作重复值除去。
data.drop_duplicates(inplace=True)
# 删除数据后不要忘记恢复索引
data.index = range(data.shape[0])
data.info()
---
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 149391 entries, 0 to 149390
Data columns (total 11 columns):
SeriousDlqin2yrs 149391 non-null int64
RevolvingUtilizationOfUnsecuredLines 149391 non-null float64
age 149391 non-null int64
NumberOfTime30-59DaysPastDueNotWorse 149391 non-null int64
DebtRatio 149391 non-null float64
MonthlyIncome 120170 non-null float64
NumberOfOpenCreditLinesAndLoans 149391 non-null int64
NumberOfTimes90DaysLate 149391 non-null int64
NumberRealEstateLoansOrLines 149391 non-null int64
NumberOfTime60-89DaysPastDueNotWorse 149391 non-null int64
NumberOfDependents 145563 non-null float64
dtypes: float64(4), int64(7)
memory usage: 12.5 MB
关于drop_duplicates()
drop_duplicates( ["subset: 'Hashable | Sequence[Hashable] | None' = None", 'keep: "Literal[\'first\'] | Literal[\'last\'] | Literal[False]" = \'first\'', "inplace: 'bool' = False", "ignore_index: 'bool' = False"], ) -> 'DataFrame | None' # 默认情况下,删除所有完全相同的行,保留最上面的一行 # subset:列表,列表中的元素对应DataFrame的列名,只要指定的列元素相同,就认为这两行相同 # keep:默认'first',对于有重复的行,保留最上面的一行,删除其余行;'last',保留最下面的一行 # inplace:是否返回新的DataFrame,默认True,填False,则修改原数据import pandas as pd a = pd.DataFrame([[1,2,3,4],[2,3,4,5],[1,3,3,7],[2,3,4,5]],columns=['a','b','c','d']) a --- a b c d 0 1 2 3 4 1 2 3 4 5 2 1 3 3 7 3 2 3 4 5 a.drop_duplicates() # 默认 --- a b c d 0 1 2 3 4 1 2 3 4 5 2 1 3 3 7 a.drop_duplicates(['a','c'],keep='last') # 指定列 --- a b c d 2 1 3 3 7 3 2 3 4 5
填补缺失值
data.isnull().sum()/data.shape[0]
# 或者是data.isnull().mean()
---
SeriousDlqin2yrs 0.000000
RevolvingUtilizationOfUnsecuredLines 0.000000
age 0.000000
NumberOfTime30-59DaysPastDueNotWorse 0.000000
DebtRatio 0.000000
MonthlyIncome 0.195601
NumberOfOpenCreditLinesAndLoans 0.000000
NumberOfTimes90DaysLate 0.000000
NumberRealEstateLoansOrLines 0.000000
NumberOfTime60-89DaysPastDueNotWorse 0.000000
NumberOfDependents 0.025624
dtype: float64
第二个要面临的问题,就是缺失值。在这里我们需要填补的特征是“收入”和“家属人数”。“家属人数”缺失很少,仅缺失了大约2.5%,可以考虑直接删除,或者使用均值来填补。“收入”缺失了几乎20%,并且我们知道,“收入”必然是一个对信用评分来说很重要的因素,因此这个特征必须要进行填补。在这里,我们使用均值填补“家属人数”。
data['NumberOfDependents'].fillna(data['NumberOfDependents'].mean(),inplace=True)
关于fillna()。fillna可以用于DataFrame,但一般我们用于Series
fillna( ["value: 'object | ArrayLike | None' = None", "method: 'FillnaOptions | None' = None", 'axis=None', 'inplace=False', 'limit=None', 'downcast=None'], ) -> 'Series | None' # value:缺失值处填补什么,可以是数字,字典等 # 字典对象常用于DataFrame,键是columns,值是填补成什么 # method:默认None,指定一个值去替换缺失值,此时value必须有指定值;pad/ffill:用前一个非缺失值去填充该缺失值;backfill/bfill:用下一个非缺失值填充该缺失值 # 注意method和value必须填其中一个,而且两者不同冲突 # axis:主要用于DataFrame,axis=0为填充行,axis=1为填充列 # limit:限制填充个数,默认不限制。对于Series是填充空值的个数,对于DataFrame是每一行/列填充的个数(感觉对DF没啥用) # inplace:都一样对于Series
import pandas as pd import numpy as np a = pd.Series([0,1,np.nan,2,np.nan]) a --- 0 0.0 1 1.0 2 NaN 3 2.0 4 NaN dtype: float64 a.fillna(0,limit=1) --- 0 0.0 1 1.0 2 0.0 3 2.0 4 NaN dtype: float64 a.fillna(method='bfill') # 可能初始或末尾有空值,具体情况具体分析 --- 0 0.0 1 1.0 2 2.0 3 2.0 4 NaN dtype: float64对于DataFrame
b = pd.DataFrame(np.random.randint(0,10,(4,4))) b.iloc[2:,2] = np.nan # 指定列,行用切片 b.iloc[[1,3],3] = np.nan # 如果行列有一个为列表,那么就是两个列表的排列组合 # 对于[1,3],3,可以认为是[1,3]+[3,3];同理[0,1],[0,1],就是[0,0],[0,1],[1,0],[1,1] b.iloc[0,0] = np.nan b --- 0 1 2 3 0 NaN 8 1.0 7.0 1 0.0 8 0.0 NaN 2 3.0 5 NaN 8.0 3 8.0 7 NaN NaN b.fillna({0:10,2:100,3:1000}) # 字典填充 --- 0 1 2 3 0 10.0 8 1.0 7.0 1 0.0 8 0.0 1000.0 2 3.0 5 100.0 8.0 3 8.0 7 100.0 1000.0 b.fillna(0,limit=1) --- 0 1 2 3 0 0.0 8 1.0 7.0 1 0.0 8 0.0 0.0 2 3.0 5 0.0 8.0 3 8.0 7 NaN NaN
那字段"收入"怎么办呢?对于银行数据来说,我们甚至可以有这样的推断:一个来借钱的人应该是会知道,“高收入”或者“稳定收入”于他/她自己而言会是申请贷款过程中的一个助力,因此如果收入稳定良好的人,肯定会倾向于写上自己的收入情况,那么这些“收入”栏缺失的人,更可能是收入状况不稳定或收入比较低的人。基于这种判断,我们可以用比如说,四分位数来填补缺失值,把所有收入为空的客户都当成是低收入人群。当然了,也有可能这些缺失是银行数据收集过程中的失误,我们并无法判断为什么收入栏会有缺失,所以我们的推断也有可能是不正确的。具体采用什么样的手段填补缺失值,要和业务人员去沟通,观察缺失值是如何产生的。
在这里,我们使用随机森林填补“收入”。这种做法,对于某一个特征大量缺失,其他特征却很完整的情况,非常适用。
之前我们所做的随机森林填补缺失值的案例中,我们面临整个数据集中多个特征都有缺失的情况,因此要先对特征排序,遍历所有特征来进行填补。这次我们只需要填补“收入”一个特征,就无需循环那么麻烦了,可以直接对这一列进行填补。我们来写一个能够填补任何列的函数:
def fill_missing_rf(X,y,to_fill):
"""
使用随机森林填补一个特征的缺失值的函数
参数:
X:要填补的特征矩阵
y:完整的没有缺失值的标签
to_fill:字符串,要填补的那一列的名称
"""
# 构建新特征矩阵和新标签
df = X.copy()
fill = df.loc[:,to_fill]
df = pd.concat([df.loc[:,df.columns != to_fill],pd.DataFrame(y)],axis=1)
# 找出我们的训练集和测试集
Ytrain = fill[fill.notnull()]
Ytest = fill[fill.isnull()]
Xtrain = df.iloc[Ytrain.index,:]
Xtest = df.iloc[Ytest.index,:]
# 用随机森林回归来填补缺失值
from sklearn.ensemble import RandomForestRegressor as rfr
rfr = rfr(n_estimators=100).fit(Xtrain,Ytrain)
Ypredict = rfr.predict(Xtest)
return Ypredict
接下来,我们来创造函数需要的参数,将参数导入函数,产出结果:
X = data.iloc[:,1:]
y = data.iloc[:,0]
y_pred = fill_missing_rf(X,y,"MonthlyIncome")
data.loc[data.loc[:,"MonthlyIncome"].isnull(),"MonthlyIncome"] = y_pred
y_pred.shape
---
(29221,)
data.loc[data.loc[:,"MonthlyIncome"].isnull(),"MonthlyIncome"].shape
---
(29221,)
data.info()
---
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 149391 entries, 0 to 149390
Data columns (total 11 columns):
SeriousDlqin2yrs 149391 non-null int64
RevolvingUtilizationOfUnsecuredLines 149391 non-null float64
age 149391 non-null int64
NumberOfTime30-59DaysPastDueNotWorse 149391 non-null int64
DebtRatio 149391 non-null float64
MonthlyIncome 149391 non-null float64
NumberOfOpenCreditLinesAndLoans 149391 non-null int64
NumberOfTimes90DaysLate 149391 non-null int64
NumberRealEstateLoansOrLines 149391 non-null int64
NumberOfTime60-89DaysPastDueNotWorse 149391 non-null int64
NumberOfDependents 149391 non-null float64
dtypes: float64(4), int64(7)
memory usage: 12.5 MB