YOLO V1~V7论文及Pytorch实现详解
YOLO~V1论文及Pytorch实现详解
论文地址:https://paperswithcode.com/paper/you-only-look-once-unified-real-time-object
pytorch参考实现:https://github.com/ivanwhaf/yolov1-pytorch.git
1. 目标检测概述
在图像分类任务中,我们假设图像中只有⼀个主要物体对象,我们只关注如何识别其类别。然⽽,很多时候图像⾥有多个我们感兴趣的⽬标,我们不仅想知道它们的类别,还想得到它们在图像中的具体位置。在计算机视觉⾥,我们将这类任务称为⽬标检测(object detection)。
对于目标检测,目前主要有了两类方法,分别是两阶段方法和单阶段方法。对于两阶段方法,以Faster RCNN系列为代表,其先通过一个RPN(Region Proposal Net)生成建议区域(含物体的区域),再对这些区域输入后续网络进行类别判断和位置调整,此类方法的优点是精度较高,缺点是检测速度较低,训练较为困难。对于单阶段方法,以本系列文章要讲的YOLO系列为代表,其起初的基本思想为把目标检测直接看成一个回归问题,直接预测物体位置和类别信息。
2. YOLO-V1特点
- 速度快,能达到每秒45帧以上的速度;
- 全图推理,没有窗口和推荐区域概念,一次观察整张图像
3. 论文核心
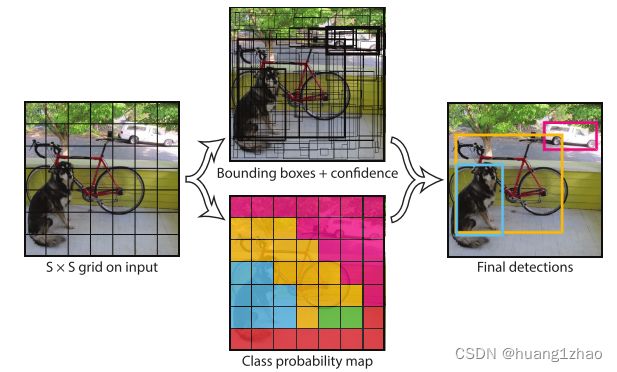
4. 网络结构
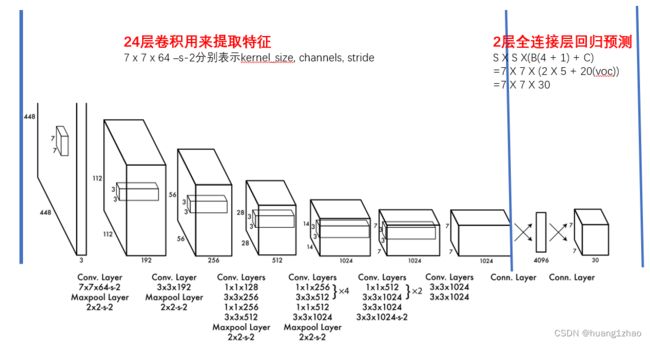 YOLO V1网络结构非常简单,易于搭建,基本为一个直通式的结构,前24层卷积网络用来提取特征,通过卷积和最大池化的步长来进行下采样,通过1x1卷积模块来改变通道数。最后两层为全连接层,用来预测位置和类别信息。YOLO V1结构没有滑动窗口和推荐区域机制,其预测是通过一次观察整张图像进行预测。
YOLO V1网络结构非常简单,易于搭建,基本为一个直通式的结构,前24层卷积网络用来提取特征,通过卷积和最大池化的步长来进行下采样,通过1x1卷积模块来改变通道数。最后两层为全连接层,用来预测位置和类别信息。YOLO V1结构没有滑动窗口和推荐区域机制,其预测是通过一次观察整张图像进行预测。
以VOC数据集训练为例,因为是20类问题,且原文把输入看成7x7的网格(grid_cell),每个网格预测2个BoundingBox(bbox),每个bbox含5个参数(x, y, w, h, c),x, y为bbox的中心,为相对与所在网格grid_cell的偏移,取值在0-1之间,w, h为bbox相对整张图像宽高的大小,取值也在0-1之间,c为该bbox含物体(非背景)的置信度。同时,对每个grid_cell还预测20个类别的置信度,故每个grid_cell预测20 + 2 x (4 + 1) = 30个参数。
5. 训练和预测
5.1 ImageNet1k数据集预训练
使用网络的前20层卷积网络(输入224224下采样至77)+平均池化+一层全连接层,使用ImageNet1k数据集训练一个分类网络。
5.2 VOC数据集训练
训练流程及损失函数
由于目标检测往往需要更多的细节,一般采用较高分辨率图像,训练目标检测模型时论文中输入图像分辨率为448*448。去除预训练模型的平均池化和全连接层,再加上4层卷积层和2层全连接层,随机初始化新增的几层网络的参数,再在VOC数据集上进行训练。接下来重点讲一下YOLO~V1的激活函数。
YOLO~V1的损失函数采用均方差函数,利于迭代优化。如上图所示,其损失可以看成3个部分。

- 与bbox有关的(x, y, w, h)有关的位置损失;
(1) λ c o o r d \lambda_coord λcoord为位置损失和分类损失的平衡系数,文中设置为5;
(2)w,h计算损失时开根号为了缩小大目标和小目标物体损失的差距,如假设大目标物体 W p r e − W b b o x W_pre -W_bbox Wpre−Wbbox为0.16,小目标 W p r e − W b b o x W_pre -W_bbox Wpre−Wbbox为0.01,如果不开根号,大目标的损失为小目标损失的196倍,开根号后为16倍,这就缓解了这种尺度差距大带来的偏向检测大目标的问题。 - 与每个bbox是否包含物体(判断是前景还是背景)的置信度C有关的损失;
- 每个网格(grid_cell)含各类物体的概率损失
训练参数
- 学习率:总共训练135epochs, 0.01训练75epochs,0.001训练30epochs,0.0001训练30epochs。
- 最后的全连接层使用dropout = 0.5防过拟合
- 数据增强:随机缩放、随机调整曝光度和饱和度(HSV)
5.3 推理
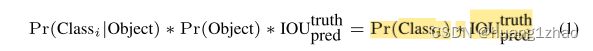
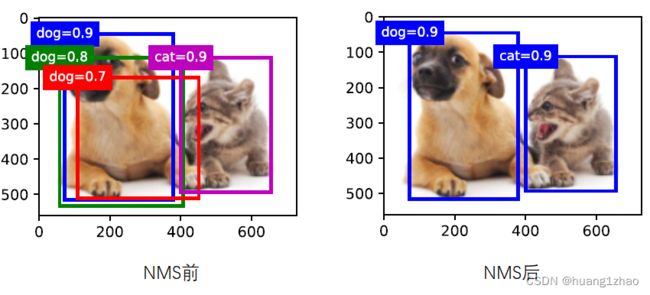
在推理时使用类别条件概率乘以bbox含物体的置信度来作为反应bbox内含某一类物体的置信度以及位置准确度。因为会预测7 * 7 * 2 =98个bbox,还需使用NMS(非极大化抑制)来获得最后的检测结果,只保留最好的检测框。NMS介绍可参考:https://blog.csdn.net/m0_37605642/article/details/98358864
6. 优缺点
优点
- 模型简单,易于搭建和训练
- 检测速度快
缺点
- 对小目标检测效果不好,只用了最高层特征,大框小误差与小框相同的误差损失一样;
7. pytorch代码实现
7.1 项目文件目录
YOLOV1-pytorch
- cfg
- - dateset.yaml 存放数据集文件路径和类比信息的配置文件
- - yolov1.yaml 存放模型相关参数的配置文件
- data 存放例子
- models 模型搭建脚本
- utils
- - datasets.py 制作自制数据集的脚本
- - draw_gt.py 绘制矩形框的脚本
- - loss 计算损失函数的脚本
- - modify_label.py 将源数据集标准信息转为含(x, y, w, h, c)的txt文件
- - util.py 包含NMS、 IOU计算、 坐标转换等函数
- train.py 训练模型的脚本
- detect.py 推理的脚本
7.2 数据准备
7.2.1 标准信息转换
转换前VOC数据集标准格式举例2007_000027.xml:
-<annotation>
<folder>VOC2012folder>
<filename>2007_000027.jpgfilename>
-<source>
<database>The VOC2007 Databasedatabase>
<annotation>PASCAL VOC2007annotation>
<image>flickrimage>
source>
-<size>
<width>486width>
<height>500height>
<depth>3depth>
size>
<segmented>0segmented>
-<object>
<name>personname>
<pose>Unspecifiedpose>
<truncated>0truncated>
<difficult>0difficult>
-<bndbox>
<xmin>174xmin>
<ymin>101ymin>
<xmax>349xmax>
<ymax>351ymax>
bndbox>
-<part>
<name>headname>
-<bndbox>
<xmin>169xmin>
<ymin>104ymin>
<xmax>209xmax>
<ymax>146ymax>
bndbox>
part>
-<part>
<name>handname>
-<bndbox>
<xmin>278xmin>
<ymin>210ymin>
<xmax>297xmax>
<ymax>233ymax>
bndbox>
part>
-<part>
<name>footname>
-<bndbox>
<xmin>273xmin>
<ymin>333ymin>
<xmax>297xmax>
<ymax>354ymax>
bndbox>
part>
-<part>
<name>footname>
-<bndbox>
<xmin>319xmin>
<ymin>307ymin>
<xmax>340xmax>
<ymax>326ymax>
bndbox>
part>
object>
annotation>
modify_label.py
import os
import xml.etree.ElementTree as ET
def modify_voc2007_label():
# VOC2007 dataset xml -> label.txt
CLASSES = ['person', 'bird', 'cat', 'cow', 'dog', 'horse', 'sheep', 'aeroplane', 'bicycle', 'boat', 'bus', 'car',
'motorbike', 'train', 'bottle', 'chair', 'dining table', 'potted plant', 'sofa', 'tvmonitor']
xml_path = '../dataset/VOC2007/Annotations'
xml_names = os.listdir(xml_path)
for xml_name in xml_names:
# print(xml_name)
f = open(os.path.join(xml_path, xml_name), 'r')
tree = ET.parse(f)
root = tree.getroot()
# get pic info
size = root.find('size')
width, height = int(size.find('width').text), int(size.find('height').text)
f2 = open('../dataset/VOC2007/labels/' + xml_name.split('.')[0] + '.txt', 'a')
for obj in root.iter('object'):
c = obj.find('name').text
difficult = obj.find('difficult').text
if c not in CLASSES:
continue
box = obj.find('bndbox')
x1, y1 = int(box.find('xmin').text), int(box.find('ymin').text)
x2, y2 = int(box.find('xmax').text), int(box.find('ymax').text)
x, y, w, h = (x1 + x2) / 2, (y1 + y2) / 2, x2 - x1, y2 - y1
x, y, w, h = x / width, y / height, w / width, h / height
# print(x, y, w, h, c)
f2.write('{} {} {} {} {}\n'.format(str(round(x, 8)), str(round(y, 8)), str(round(w, 8)), str(round(h, 8)),
str(CLASSES.index(c))))
f2.close()
f.close()
if __name__ == '__main__':
modify_voc2007_label()
转换后为.txt格式2007_000027.xml
0.53806584 0.45200000 0.36008230 0.50000000 0
7.2.2 自制数据集
datasets.py脚本
pytorch自制数据集得继承Dataset类,需至少实现__len__方法(返回有多少个样本)和__getitem__方法(返回单个样本及其标注信息)
import os
import cv2
import torch
from PIL import Image
from torch.utils.data import DataLoader, Dataset, random_split
from torchvision import transforms
from .util import xywhc2label
class YOLODataset(Dataset):
def __init__(self, img_path, label_path, S, B, num_classes, transforms=None):
self.img_path = img_path # images folder path
self.label_path = label_path # labels folder path
self.transforms = transforms
self.filenames = os.listdir(img_path)
self.filenames.sort() # 文件名排序,屏蔽不同操作系统可能初始文件顺序不一致
self.S = S
self.B = B
self.num_classes = num_classes
def __len__(self):
return len(self.filenames)
def __getitem__(self, idx):
# read image
img = cv2.imread(os.path.join(self.img_path, self.filenames[idx])) # BGR
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# ori_width, ori_height = img.shape[1], img.shape[0] # image's original width and height
img = Image.fromarray(img).convert('RGB')
img = self.transforms(img) # resize and to tensor
# read each image's corresponding label(.txt)
xywhc = []
with open(os.path.join(self.label_path, self.filenames[idx].split('.')[0] + '.txt'), 'r') as f:
lines = f.readlines()
for line in lines:
if line == '\n':
continue
line = line.strip().split(' ')
# convert xywh str to float, class str to int
x, y, w, h, c = float(line[0]), float(line[1]), float(line[2]), float(line[3]), int(line[4])
xywhc.append((x, y, w, h, c))
label = xywhc2label(xywhc, self.S, self.B, self.num_classes) # convert xywhc list to label
label = torch.Tensor(label)
return img, label
xywhc2label()方法:把标准信息(保存每个物体xywhc的txt文件)转为计算损失时要用的(S, S, 5 * B + num_classes)形的目标
def xywhc2label(bboxs, S, B, num_classes):
# bboxs is a xywhc list: [(x,y,w,h,c),(x,y,w,h,c),....]
label = np.zeros((S, S, 5 * B + num_classes))
for x, y, w, h, c in bboxs:
x_grid = int(x // (1.0 / S)) # x y w h都为0-1,此处得到的为bbox在哪个grid cell
y_grid = int(y // (1.0 / S))
xx, yy = x, y
label[y_grid, x_grid, 0:5] = np.array([xx, yy, w, h, 1]) # bbox1
label[y_grid, x_grid, 5:10] = np.array([xx, yy, w, h, 1]) # bbox2
label[y_grid, x_grid, 10 + c] = 1 # 类别
return label
划分数据集生成数据加载迭代器
def create_dataloader(img_path, label_path, train_proportion, val_proportion, test_proportion, batch_size, input_size,
S, B, num_classes):
transform = transforms.Compose([
transforms.Resize((input_size, input_size)),
transforms.ToTensor()
])
# create yolo dataset
dataset = YOLODataset(img_path, label_path, S, B, num_classes, transforms=transform)
dataset_size = len(dataset)
train_size = int(dataset_size * train_proportion)
val_size = int(dataset_size * val_proportion)
test_size = dataset_size - train_size - val_size # 可以为0
# split dataset to train set, val set and test set three parts
train_dataset, val_dataset, test_dataset = random_split(dataset, [train_size, val_size, test_size])
# create data loader
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=False)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
return train_loader, val_loader, test_loader
7.3 模型搭建
yolov1.py 按照模型结构图逐层搭建即可,此处实现与源作者代码不同,作者实现的只有6层卷积,使用时覆盖源代码YOLOv1类即可
import torch
import torch.nn as nn
# 下采样了 64 倍 输入448 * 448 输出 7 * 7 * 30 = 3000
architecture_config = [
# tuple = (kernel size, number of filters of output, stride, padding)
(7, 64, 2, 3),
"M", # max-pooling 2x2 stride = 2 448 - > 112
(3, 192, 1, 1),
"M", # max-pooling 2x2 stride = 2 112 -> 56
(1, 128, 1, 0),
(3, 256, 1, 1),
(1, 256, 1, 0),
(3, 512, 1, 1),
"M", # max-pooling 2x2 stride = 2 56 - > 28
# [tuple, tuple, repeat times]
[(1, 256, 1, 0), (3, 512, 1, 1), 4],
(1, 512, 1, 0),
(3, 1024, 1, 1),
"M", # max-pooling 2x2 stride = 2 28 - > 14
# [tuple, tuple, repeat times]
[(1, 512, 1, 0), (3, 1024, 1, 1), 2],
(3, 1024, 1, 1),
(3, 1024, 2, 1), # 14 -> 7
(3, 1024, 1, 1),
(3, 1024, 1, 1),
] # 7 * 7 * 1024
# 一个卷积模块包括卷积层、BN 和激活函数
class CNNBlock(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(CNNBlock, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.batchnorm = nn.BatchNorm2d(out_channels)
self.leakyrelu = nn.LeakyReLU(0.1)
def forward(self, x):
x = self.conv(x)
x = self.batchnorm(x)
x = self.leakyrelu(x)
return x
class YOLOv1(nn.Module):
def __init__(self, in_channels=3, **kwargs):
super(YOLOv1, self).__init__()
self.architecture = architecture_config
self.in_channels = in_channels
self.darknet = self._create_conv_layers(self.architecture)
self.fcs = self._create_fcs(**kwargs)
def forward(self, x):
x = self.darknet(x)
x = torch.flatten(x, start_dim=1) # 7 * 7 * 1024 = 50176
x = self.fcs(x)
return x
def _create_conv_layers(self, architecture):
layers = []
in_channels = self.in_channels
for x in architecture:
if type(x) == tuple: # 卷积层不含重复模块
layers += [
CNNBlock(
in_channels, x[1], kernel_size=x[0], stride=x[2], padding=x[3],
) # 关键字参数传入时保存为字典
]
in_channels = x[1]
elif type(x) == str: # max-pooling层
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif type(x) == list:
conv1 = x[0] # tuple
conv2 = x[1] # tuple
num_repeats = x[2] # integer
for _ in range(num_repeats):
layers += [
CNNBlock(
in_channels,
conv1[1],
kernel_size=conv1[0],
stride=conv1[2],
padding=conv1[3],
)
]
layers += [
CNNBlock(
conv1[1],
conv2[1],
kernel_size=conv2[0],
stride=conv2[2],
padding=conv2[3],
)
]
in_channels = conv2[1]
return nn.Sequential(*layers) # 将列表解开成几个独立的参数,传入函数
def _create_fcs(self, split_size, num_boxes, num_classes):
S, B, C = split_size, num_boxes, num_classes
return nn.Sequential(
nn.Flatten(),
nn.Linear(1024*S*S, 4096),
nn.Dropout(0.5),
nn.LeakyReLU(0.1),
nn.Linear(4096, S*S*(C+B*5)), # (S,S,30)
)
def test(S=7, B=2, C=20):
model = Yolov1(split_size=S, num_boxes=B, num_classes=C)
x = torch.randn((2, 3, 448, 448))
print(model(x).shape) # 2 * 1470(7 * 7 * 30)
if __name__ == "__main__":
test()
7.4 训练
自定义损失函数计算: 对照公式比较容易实现
import torch
from torch import nn
from .util import calculate_iou
class YOLOv1Loss(nn.Module):
def __init__(self, S, B):
super().__init__()
self.S = S
self.B = B
def forward(self, preds, labels):
batch_size = labels.size(0)
loss_coord_xy = 0. # coord xy loss
loss_coord_wh = 0. # coord wh loss
loss_obj = 0. # obj loss
loss_no_obj = 0. # no obj loss
loss_class = 0. # class loss
for i in range(batch_size):
for y in range(self.S):
for x in range(self.S):
# this region has object
if labels[i, y, x, 4] == 1:
pred_bbox1 = torch.Tensor(
[preds[i, y, x, 0], preds[i, y, x, 1], preds[i, y, x, 2], preds[i, y, x, 3]])
pred_bbox2 = torch.Tensor(
[preds[i, y, x, 5], preds[i, y, x, 6], preds[i, y, x, 7], preds[i, y, x, 8]])
label_bbox = torch.Tensor(
[labels[i, y, x, 0], labels[i, y, x, 1], labels[i, y, x, 2], labels[i, y, x, 3]])
# calculate iou of two bbox
iou1 = calculate_iou(pred_bbox1, label_bbox)
iou2 = calculate_iou(pred_bbox2, label_bbox)
# judge responsible box
if iou1 > iou2:
# calculate coord xy loss
loss_coord_xy += 5 * torch.sum((labels[i, y, x, 0:2] - preds[i, y, x, 0:2]) ** 2)
# coord wh loss
loss_coord_wh += torch.sum((labels[i, y, x, 2:4].sqrt() - preds[i, y, x, 2:4].sqrt()) ** 2)
# obj confidence loss
loss_obj += (iou1 - preds[i, y, x, 4]) ** 2
# loss_obj += (preds[i, y, x, 4] - 1) ** 2
# no obj confidence loss
loss_no_obj += 0.5 * ((0 - preds[i, y, x, 9]) ** 2)
# loss_no_obj += 0.5 * ((preds[i, y, x, 9] - 0) ** 2)
else:
# coord xy loss
loss_coord_xy += 5 * torch.sum((labels[i, y, x, 5:7] - preds[i, y, x, 5:7]) ** 2)
# coord wh loss
loss_coord_wh += torch.sum((labels[i, y, x, 7:9].sqrt() - preds[i, y, x, 7:9].sqrt()) ** 2)
# obj confidence loss
loss_obj += (iou2 - preds[i, y, x, 9]) ** 2
# loss_obj += (preds[i, y, x, 9] - 1) ** 2
# no obj confidence loss
loss_no_obj += 0.5 * ((0 - preds[i, y, x, 4]) ** 2)
# loss_no_obj += 0.5 * ((preds[i, y, x, 4] - 0) ** 2)
# class loss
loss_class += torch.sum((labels[i, y, x, 10:] - preds[i, y, x, 10:]) ** 2)
# this region has no object,背景
else:
loss_no_obj += 0.5 * torch.sum((0 - preds[i, y, x, [4, 9]]) ** 2)
loss = loss_coord_xy + loss_coord_wh + loss_obj + loss_no_obj + loss_class # five loss terms
return loss / batch_size
train.py
import argparse
import os
import time
import matplotlib.pyplot as plt
import torch
from torch.optim import SGD
from torchvision import utils
from utils import create_dataloader, YOLOv1Loss, parse_cfg, build_model
# from torchviz import make_dot
parser = argparse.ArgumentParser(description='YOLOv1-pytorch')
parser.add_argument("--cfg", "-c", default="cfg/yolov1.yaml", help="Yolov1 config file path", type=str)
parser.add_argument("--dataset_cfg", "-d", default="cfg/dataset.yaml", help="Dataset config file path", type=str)
parser.add_argument("--weights", "-w", default="", help="Pretrained model weights path", type=str)
parser.add_argument("--output", "-o", default="output", help="Output path", type=str)
parser.add_argument("--epochs", "-e", default=100, help="Training epochs", type=int)
parser.add_argument("--lr", "-lr", default=0.002, help="Training learning rate", type=float)
parser.add_argument("--batch_size", "-bs", default=32, help="Training batch size", type=int)
parser.add_argument("--save_freq", "-sf", default=10, help="Frequency of saving model checkpoint when training",
type=int)
args = parser.parse_args()
def train(model, train_loader, optimizer, epoch, device, S, B, train_loss_lst):
model.train() # Set the module in training mode
train_loss = 0
for batch_idx, (inputs, labels) in enumerate(train_loader):
t_start = time.time()
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
# back prop
criterion = YOLOv1Loss(S, B) # 实例化一个网络模块
loss = criterion(outputs, labels) # 正向传播
optimizer.zero_grad() # 每一轮梯度清0
loss.backward() # 反向传播
optimizer.step() # 梯度更新
train_loss += loss.item() # 训练一个epoch总损失
t_batch = time.time() - t_start
# print loss and accuracy
if batch_idx % 10 == 0:
print('Train Epoch: {} [{}/{} ({:.1f}%)] Time: {:.4f}s Loss: {:.6f}'
.format(epoch, batch_idx * len(inputs), len(train_loader.dataset),
100. * batch_idx / len(train_loader), t_batch, loss.item()))
# record training loss
train_loss /= len(train_loader) # 平均损失
train_loss_lst.append(train_loss) # 每个epoch的损失列表
return train_loss_lst
def validate(model, val_loader, device, S, B, val_loss_lst):
# 可以考虑保存coco指标或者mAP50
model.eval() # Sets the module in evaluation mode
val_loss = 0
# no need to calculate gradients
with torch.no_grad():
for data, target in val_loader:
data, target = data.to(device), target.to(device)
output = model(data)
# add one batch loss
criterion = YOLOv1Loss(S, B)
val_loss += criterion(output, target).item()
val_loss /= len(val_loader)
print('Val set: Average loss: {:.4f}\n'.format(val_loss))
# record validating loss
val_loss_lst.append(val_loss)
return val_loss_lst
def test(model, test_loader, device, S, B):
model.eval() # Sets the module in evaluation mode
test_loss = 0
# no need to calculate gradients
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
# add one batch loss
criterion = YOLOv1Loss(S, B)
test_loss += criterion(output, target).item()
# record testing loss
test_loss /= len(test_loader)
print('Test set: Average loss: {:.4f}'.format(test_loss))
if __name__ == "__main__":
cfg = parse_cfg(args.cfg)
dataset_cfg = parse_cfg(args.dataset_cfg)
img_path, label_path = dataset_cfg['images'], dataset_cfg['labels']
S, B, num_classes, input_size = cfg['S'], cfg['B'], cfg['num_classes'], cfg['input_size']
# create output file folder
start = time.strftime('%Y-%m-%d-%H-%M-%S', time.localtime(time.time()))
output_path = os.path.join(args.output, start)
os.makedirs(output_path)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# build model
model = build_model(args.weights, S, B, num_classes).to(device)
train_loader, val_loader, test_loader = create_dataloader(img_path, label_path, 0.8, 0.1, 0.1, args.batch_size,
input_size, S, B, num_classes)
optimizer = SGD(model.parameters(), lr=args.lr, momentum=0.9, weight_decay=0.0005) # 可以加一个lr动态改变策略
# optimizer = Adam(model.parameters(), lr=lr)
train_loss_lst, val_loss_lst = [], []
# train epoch
for epoch in range(args.epochs):
train_loss_lst = train(model, train_loader, optimizer, epoch, device, S, B, train_loss_lst)
val_loss_lst = validate(model, val_loader, device, S, B, val_loss_lst)
# save model weight every save_freq epoch
if epoch % args.save_freq == 0 and epoch >= args.epochs / 2:
torch.save(model.state_dict(), os.path.join(output_path, 'epoch' + str(epoch) + '.pth'))
test(model, test_loader, device, S, B)
# save model
torch.save(model.state_dict(), os.path.join(output_path, 'last.pth'))
# plot loss, save params change
fig = plt.figure()
plt.plot(range(args.epochs), train_loss_lst, 'g', label='train loss')
plt.plot(range(args.epochs), val_loss_lst, 'k', label='val loss')
plt.grid(True)
plt.xlabel('epoch')
plt.ylabel('acc-loss')
plt.legend(loc="upper right")
plt.savefig(os.path.join(output_path, 'loss_curve.jpg'))
plt.show()
plt.close(fig)
7.5 检测
一般过程为把待检测图像输入训练好的模型,预测得到pres(S, S, B*5+classes),通过NMS得到最终的bbox并绘制矩形框再保存。
import argparse
import os
import random
import shutil
import cv2
import numpy as np
from PIL import Image
from torchvision import transforms
from utils import parse_cfg, pred2xywhcc, build_model
parser = argparse.ArgumentParser(description='YOLOv1 Pytorch Implementation')
parser.add_argument("--weights", "-w", default="weights/last.pth", help="Path of model weight", type=str)
parser.add_argument("--source", "-s", default="dataset/VOC2007/JPEGImages",
help="Path of your input file source,0 for webcam", type=str)
parser.add_argument('--output', "-o", default='output', help='Output folder', type=str)
parser.add_argument("--cfg", "-c", default="cfg/yolov1.yaml", help="Your model config path", type=str)
parser.add_argument("--dataset_cfg", "-d", default="cfg/dataset.yaml", help="Your dataset config path", type=str)
parser.add_argument('--cam_width', "-cw", default=848, help='camera width', type=int)
parser.add_argument('--cam_height', "-ch", default=480, help='camera height', type=int)
parser.add_argument('--conf_thresh', "-ct", default=0.1, help='prediction confidence thresh', type=float)
parser.add_argument('--iou_thresh', "-it", default=0.3, help='prediction iou thresh', type=float)
args = parser.parse_args()
# random colors
COLORS = [[random.randint(0, 255) for _ in range(3)] for _ in range(100)]
def draw_bbox(img, bboxs, class_names):
h, w = img.shape[0:2]
n = bboxs.size()[0]
bboxs = bboxs.detach().numpy()
print(bboxs)
for i in range(n):
p1 = (int((bboxs[i, 0] - bboxs[i, 2] / 2) * w), int((bboxs[i, 1] - bboxs[i, 3] / 2) * h))
p2 = (int((bboxs[i, 0] + bboxs[i, 2] / 2) * w), int((bboxs[i, 1] + bboxs[i, 3] / 2) * h))
class_name = class_names[int(bboxs[i, 5])]
# confidence = bboxs[i, 4]
cv2.rectangle(img, p1, p2, color=COLORS[int(bboxs[i, 5])], thickness=2)
cv2.putText(img, class_name, p1, cv2.FONT_HERSHEY_SIMPLEX, 0.8, COLORS[int(bboxs[i, 5])])
return img
def predict_img(img, model, input_size, S, B, num_classes, conf_thresh, iou_thresh):
"""get model prediction of one image
Args:
img: image ndarray
model: pytorch trained model
input_size: input size
Returns:
xywhcc: predict image bbox
"""
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
pred_img = Image.fromarray(img).convert('RGB')
transform = transforms.Compose([
transforms.Resize((input_size, input_size)),
transforms.ToTensor()
])
pred_img = transform(pred_img)
pred_img.unsqueeze_(0)
pred = model(pred_img)[0].detach().cpu()
xywhcc = pred2xywhcc(pred, S, B, num_classes, conf_thresh, iou_thresh)
return xywhcc
if __name__ == "__main__":
# load configs from config file
cfg = parse_cfg(args.cfg)
input_size = cfg['input_size']
dataset_cfg = parse_cfg(args.dataset_cfg)
class_names = dataset_cfg['class_names']
print('Class names:', class_names)
S, B, num_classes = cfg['S'], cfg['B'], cfg['num_classes']
conf_thresh, iou_thresh, source = args.conf_thresh, args.iou_thresh, args.source
# load model
model = build_model(args.weights, S, B, num_classes)
print('Model loaded successfully!')
# create output folder
if not os.path.exists(args.output):
os.makedirs(args.output)
# Image
if source.split('.')[-1] in ['jpg', 'png', 'jpeg', 'bmp', 'tif', 'tiff', 'gif', 'webp']:
img = cv2.imread(source)
img_name = os.path.basename(source)
xywhcc = predict_img(img, model, input_size, S, B, num_classes, conf_thresh, iou_thresh)
if xywhcc.size()[0] != 0:
img = draw_bbox(img, xywhcc, class_names)
# save output img
cv2.imwrite(os.path.join(args.output, img_name), img)
# Folder
elif source == source.split('.')[-1]:
# create output folder
output = os.path.join(args.output, source.split('/')[-1])
if os.path.exists(output):
shutil.rmtree(output)
# os.removedirs(output)
os.makedirs(output)
imgs = os.listdir(source)
for img_name in imgs:
# img = cv2.imread(os.path.join(source, img_name))
img = cv2.imdecode(np.fromfile(os.path.join(
source, img_name), dtype=np.uint8), cv2.IMREAD_COLOR)
# predict
xywhcc = predict_img(img, model, input_size, S, B, num_classes, conf_thresh, iou_thresh)
if xywhcc.size()[0] != 0:
img = draw_bbox(img.copy(), xywhcc, class_names)
# save output img
cv2.imwrite(os.path.join(output, img_name), img)
print(img_name)
8. 参考资料
- https://github.com/ivanwhaf/yolov1-pytorch.git
- You Only Look Once:Unified, Real-Time Object Detection