【论文笔记】TrivialAugment: Tuning-free Yet State-of-the-Art Data Augmentation
论文

论文题目:TrivialAugment: Tuning-free Yet State-of-the-Art Data Augmentation
接收: ICCV 2021 Oral
论文地址:https://arxiv.org/abs/2103.10158
代码地址:https://github.com/automl/trivialaugment
Abstract
自动增强方法是增强模型性能的重要支柱。现有自动增强方法需在简单性、成本和性能之间进行权衡。本文提供了一个简单的基线,TrivialAugment,几乎无成本且效果超越以前的方法。TA是无参的,只对每个图像应用单一的增强。论文经过深入实验发现效果显著,将其与以往的方法进行比较,进行消融实验,并提供了一个简单接口。

TA可视化。对于每幅图像,TA均匀采样一个增强强度和增强。再将这种增强应用于具有采样强度的图像上。
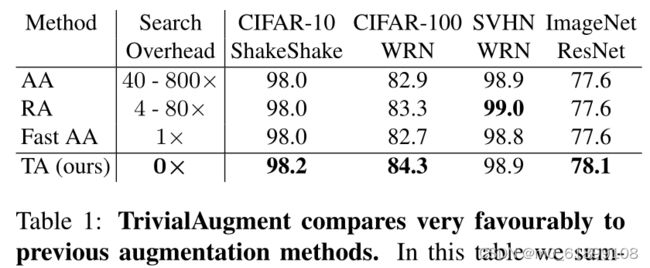
TA与以前的方法相比,具有优势。
Introduction
本文主要研究数据增强在图像分类场景的应用。图像分类中的数据增强是基于原始图像生成新的图像,增强完以后仍然属于相同的分类,相当于数据的扩充。早期的数据增强策略是纯人工设计的,直至AA等自动搜索出的数据增强策略的提出,才降低了数据增强的设计难度。自动增强方法是一组自动设计增强策略的方法,可以显著提高模型的性能。
自动搜索的数据增强策略在使用时虽然是几乎for free的,但是搜索确实是一个耗时耗卡的大工程。Trivial Augment(TA)的提出,不需要特定的任务选择的数据增强策略,也不用将多种数据增强策略组合在一起,是一种简单有效的策略。
Contribution
- 分析性能良好的自动增强方法的最低要求,并提出TrivialAugment(TA),一个微不足道的增强基线,在大多数设置中表现出最先进的性能。同时,TA是迄今为止最实用的自动增强方法。
- 使用统一的开源代码库,在许多设置中综合分析了TA和其他多种自动增强方法的性能。
- 对自动增强方法的实际使用提出建议,并收集自动增强研究的最佳实践。此外,提供了代码。
Problem Solved
使用NAS方法自动搜索的数据增强的方法虽然是有效的,但局限在于需要权衡搜索效率和数据增强的性能。为了解决这个问题,论文提出了Trivial Augment数据增强策略(后文简称TA),相比于之前的数据增强策略,TA是无参数的,每张图片只使用一次数据增强方式,因此相比于AA、PBA乃至RA,它的搜索成本几乎是free的,而且取得了SOTA的效果。
Method of Use
作者开源了代码,使用方法很简单,通过以下几行代码的调用就能搞定:
augment = aug_lib.TrivialAugment()
trans = transforms.Compose(
[
transforms.RandomResizedCrop(train_crop_size, interpolation=interpolation),
transforms.RandomHorizontalFlip(),
augment,
transforms.ToTensor(),
normalize,
]
)Related Work
自动增强方法共同的属性:作用于由 ①一组预先指定的增强A 和 ②一组可能的强度设置 而成的增强空间。A中的增强可以被调用。

例如,A的一个成员可能是旋转操作,其中强度对应于角度大小。
自动增强方法学习如何在训练数据上同时使用这些增强,以生成性能良好的最终分类器。
由于自动增强方法的计算需求可以支配训练成本,本文按照每种方法的总成本来排序。
Relevant Previous Methods
第一种方式 AutoAugment(AA) 成本最昂贵,在CIFAR-10生成一个分类器花费半个GPU-year。
使用RNN网络,用强化学习方法来预测增强策略的参数化。对在特定数据集上用预测策略训练的特定模型的验证准确性给予奖励。AA利用多个子策略,每个策略由多个增强点组成,这些增强点依次应用于输入图像。此外,增强将以指定的概率被删除。这允许一个子策略表示多种增强的组合。因为AA成本较高,它使用的不是手动增强搜索,而是缩减的数据集和更小的模型变体。
第二种方式 Augmentationwise Sharing for AutoAugment(AWS) 成本昂贵。
建立在与AA相同的优化过程上,但使用了更为简单的搜索空间。搜索空间由共同应用的增强对的分布组成。与AA不同的是,AWS只学习训练的最后几个周期的增强策略。它在完整的数据集上使用一个小模型来实现。
第三种方式 Population-based Augmentation(PBA)
在训练过程中在线学习增强策略。PBA使用多个worker来实现,每个worker使用不同的策略,并以进化的方式更新。它使用了另一种策略参数化:一个增强向量,其中每个增强都有一个附加强度和一楼概率。从这个向量中,均匀地随机抽出增强,并以给定地强度进行应用或者忽略,这取决于忽略概率。
第四种方式 Online Hyper-Parameter Learning for Auto-Augmentation(OHL)
策略定义类似AWS,它的参数使用强化学习进行训练。与AWS的区别在于,它的奖励是经过PBA等部分训练后,对保留数据的准确性,而不是最终的准确性。作为并行运行中调整神经网络权重的另一种方式,具有最大精度的worker的权重被用来初始化下一部分训练中的所有worker。
第四种方式 Adversarial AutoAugment(Adv. AA) 成本稍微较低。
使用多个worker在线学习增强策略。但,它只训练一种模型。这里,一个批处理被复制给八个不同的worker,每个worker对它使用自己的策略。worker策略在每个epoch开始时从策略分布中采样。策略分布的形式与AA类似。在每个epoch后,Adv. AA进行基于强化学习的更新,并奖励产生最低精度训练精度的策略,导致策略分布在训练中逐步向更强的增强转移。
第五种方式 RandAugment(RA) 更简单,但成本仅稍微较低
RA仅对每个任务调优两个标量参数:①单个增强强度m,适用于所有的增强;②每个图像的的增强数量n的组合。
RA将超参数的数量从RNN(对于AA)或超过1000个增强组合(对于AWS和OHL)的分布的所有权值减少到只有2个。简化很彻底,但并没有损害准确性得分。作者指出,强大的性能可能是由于n和m是针对当前的确切任务而调优的,而不是像在AA中那样针对修剪后的数据集进行调优。RA最大缺点是,它最终会对n和m的一组选项执行详尽的搜索,在单个训练中导致高达80倍的开销。
第六种方式 Fast AutoAugment(Fast AA) 成本最低
基于AA,但不直接搜索具有较强验证性能的策略。相反,它通过为在原始、非增强的图像分割上训练的网络寻找表现良好的推理增强策略来搜索增强策略。然后将在不同分块上发现的所有推理增强连接起来,建立一个训练时间增强策略。
总结为:如果一个在真实数据上训练的神经网络被泛化为用某些策略增强的例子,那么这个策略产生的图像位于类的域内,就像神经网络所近似的那样。因此增强是类保留的和有用的。这一目标与Adv. AA所采用的方法形成鲜明对比。Fast AA试图找到应用于验证数据时产生高准确性的增强,而Adv. AA试图找到应用于训练数据时产生低准确性的增强。
第七种方式 UniformAugment(UA)
工作原理与RA类似。不同的是,它将增强的数量固定为N=2,并以0.5的固定概率删除每个增强。此外,强度m对每个应用的操作进行均匀随机采样。
Methodology of this paper
TrivialAugment(TA)
与UA一样无参数,但更简单。同时,TA的性能优于目前任何一种成本相对较低的增强策略,因而很实用。
TrivialAugment
TA采用了和RandomAugment相同的数据增强风格,具体来说,数据增强被定义为由一个数据增强函数a和对应的强度值m(部分数据增强函数不使用强度值)组成。强度参数并不是所有增强都使用,但大多数用它来定义对图像的扭曲程度。
Working Principle

TA工作流程:
- 首先,以输入图像 x 和一组数据增强函数地集合 A 作为输入;
- 再简单地从A中随机均匀采样一个增强函数a;
- 再从 {0,1,2,..,30} 中随机均匀采样一个值作为强度m,然后利用增强函数a和强度值m对输入图像x进行数据增强处理;
- 最后,返回增强后的图像。
A Visualization of TA
上面一张图是TA的过程可视化,对于每个图像,TA均匀采样一个数据增强函数和一个强度值,然后返回增强后的图片。此外,之前的方法往往叠加多个数据增强方式,而TA只对每个图使用单一的数据增强方式。使用这样的方式,可以将TA增强后的数据集看做是:将一张图片使用所有的数据增强方式分别增强,然后从中均匀采样。

具体来说,如上图所示,X和O代表两个类别,中间用虚线作为分界线,其中黑色的代表原始类别,彩色的代表扩充后的类别。可以看到,TA相当于把原始图片按照不同的数据增强方式分别做了增强,然后我们再从中随机抽样获得增强后的数据。
Experiments
5个数据集:
- CIFAR-10 和 CIFAR-100 图像分类数据集,每个数据集包含50k张训练图像。
- SVHN 由房号图像组成;SVHN Core 附带73k的核心训练图像;并提供额外531k更简单图像作为SVHN数据集的扩展。
- ImageNet,大型图像分类语料库,1000个类,120多万张图。
Comparison to Published Results


论文将TA和PBA、Fast AA等数据增强策略对比,发现其在针对不同的数据集,使用不同的网络进行对比(训练5~10次取平均值),在大部分数据集和模型上训练都取得了SOTA的结果。这也表明了TA策略针对多种数据集和模型均有效果且鲁棒性较强。
Comparison of Reproduced Results in a Fixed Training Setup
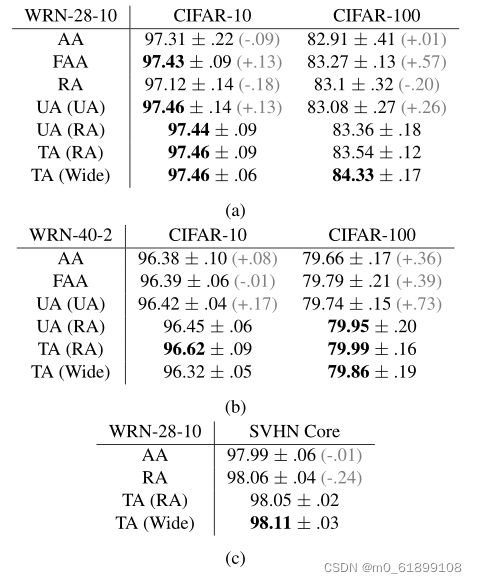

TA(wide)在每个Wide-Resnet-28-10基准中表现最好,TA(RA)在Wide-Resnet-40-2基准测试中表现最好。
Comparison by Total Compute Costs
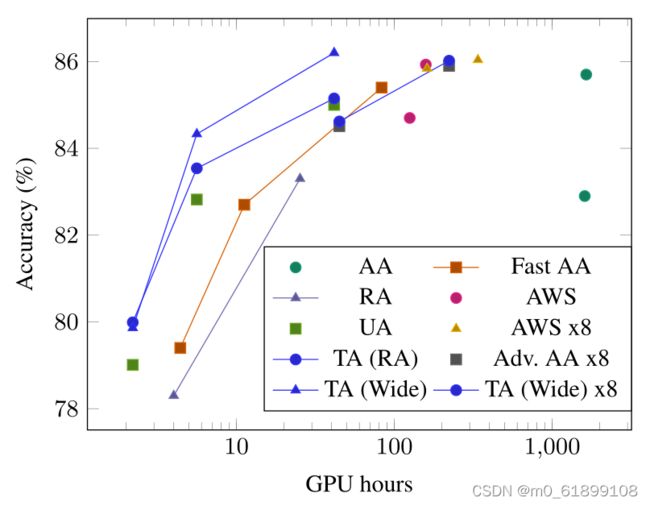

论文对比了不同的数据增强策略的效率,它们都使用Wide-ResNet模型训练,对比达到指定的精度所耗费的GPU卡时。从平行于x轴的方向来看,达到同样的精度TA耗时最少,从平行于y轴的方向来看,使用相同的训练时长,TA的精度最高。总的来讲,在精度、计算资源两个维度下,TA的是最高效的。
Understanding the Minimal Requirements of TA
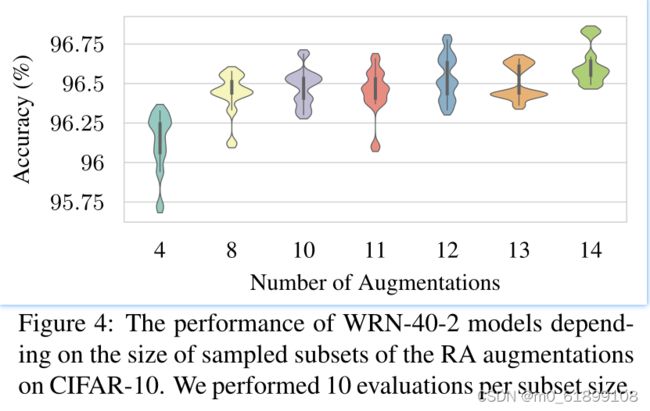
论文也对TA做了消融实验来确保实现TA的最低要求,带有不同手工挑选的增强空间的TA,采用随机修建增强空间的TA行为、强度集合对TA性能的影响。


An overview of the augmentation spaces

上述就是TA的搜索空间,由不同的PIL库函数以及其对应的数据增强的强度(部分操作没有强度项)组成。总的来说,TA的数据增强空间建立在RA搜索空间的基础上,添加了UA、 OHL的数据增强空间。
Comparison of Different Methods on the Same Augmentation Space


Conclusion
大多数数据增强方法较为复杂。本文提出一种简单的增强算法 TA,从中我们可以学到3件事。
- 自动增强方法的一个关键的基线缺失。
- 永远不要忽视最简单的解决方案。
- 选择优势的随机性似乎对优秀的性能很重要。
参考博客
(附链接)ICCV21 oral | TrivialAugment:不用调优的SOTA数据增强策略