论文阅读(Multimodal Dialog Systems via Capturing Context-aware Dependencies of Semantic Elements)
多模态对话系统
- 简述
- 相关工作
-
- 单模态对话系统
- 多模态对话系统
- 方法
-
- 多模态元素级编码器
- 两阶段知识译码器
- 模型训练
- 实验
-
- 数据集
- 实验步骤
- 对比方法
- 评估指标
- 实验结果
- 消融实验
参考论文:Multimodal Dialog Systems via Capturing Context-aware
Dependencies of Semantic Elements
简述
现存的研究大部分集中于句子语义上的表示,而忽略了文本之间的依赖性(例如单词和图片)。而继承视觉内容时,常常又忽略了曾经出现的图片。文中提出一种MATE(Multimodal diAlogue systems with semanTic Elements)。
具体来说,分解多模态的输入并设计一个多模态的元素级别的编码器去获取元素级的语义表征。同时,我们考虑所有的图片会和现有轮次的图片有关,并且通过位置编码注入图片的序列特征。
前人的模型基于MHRED(Multimodal Hierarchical encoder-decoder)结构,在这个结构中是将每个句子压缩成一个向量。因此在这个结构中获取语义上下文的联系是困难的。
而如何捕获元素级的依赖也是困难的,我们提出MATE。首先我们利用一个自注意力模块去编码文本语义,然后我们用一个图片选择器从历史和当前图片中去决定参考图片并用CNN去挖掘其中的特征。为了充分利用这些图片信息,我们用位置编码来表现视觉序列特征,因此,一个注意力机制被用在产生多模态语义元素的联合表征。最终这样的表征放在2阶段的解码器中生成最终的结果。第一阶段的解码器集中于编码器之后的多模态内容,第二阶段的解码器通过组合相关领域知识重新定义了第一个解码器的结果
相关工作
单模态对话系统
- 传统对话系统
open-domain dialogue systems:
基于检索:从池中选择合适的回答
基于生成:用编码器-译码器架构
task-oriented dialogue systems:
传统任务驱动对话系统:先对用户意图进行分类,再用一个决策网络决定下一步行动,最后通过预定义好的模板或者某些生成模型来进行回应
- 深度学习对话系统
端到端可训练对话系统:从数据库连接输入表征到槽值对
扩展式HRED
深度强化学习
多模态对话系统
MHRED
- 理解多模态语义
用一个Exclusive&Independent树来进行视觉表征
一个经典的位置和属性注意力机制来学习增强的图片表征
用户注意力引导多模态对话系统(侧重用户需求和属性层级),并根据用户注意力动态地编码对话历史
- 合并相关领域知识
用注意力机制决定哪一块的领域知识被用到
MAGIC:用一个可选择解码器来生成知识意识的回答
方法
多模态元素级编码器
从历史对话中组织出图片和问答库,分配相关的图片给每一轮对话,并且通过注意力机制获取图片增强后的文本表征。同时,所有图片被用户查询集成,形成一个查询增强后的图片表征。最终,所有表征连接在一起作为一个多模态语义元素表征。
- 分别获取文本和图片表征
对于文本,我们利用TB去获取表征(自注意力的transformer)
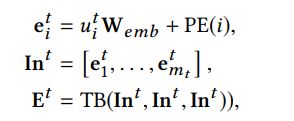
对于图像,我们使用CNN去获取表征,不同的是我们考虑所有的历史图片,并加上一个图片序列信息的位值编码
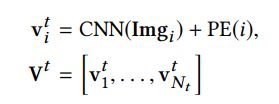
- 多模态融合
对于第t轮的文本,我们利用图像表征去增强文本表征;同时我们设计添加轮次的表征TE在文本表征上表示最终图像增强后的文本表征

对于用户询问句子来说处理方法是类似的,不同的地方在于我们也用问询句子来增强图像表征。因为问询句子通常会提供图片信息的重要线索。
最终,我们连接图像增强后的文本表征和查询增强后的图像表征去获取内容表征(也就是多模态元素表征)
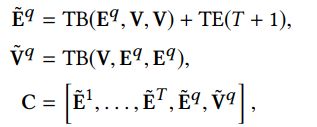
观察上面几个公式,我们可以看出最终的表征是由三个部分构成: E ~ t \tilde{E}^t E~t、 E ~ q \tilde{E}^q E~q和 V ~ q \tilde{V}^q V~q构成,分别含义为图像增强后的文本表征、图像增强后的查询表征和查询增强后的图像表征。在实际应用中V不可能是所有历史图片,因为物理存储有限。
两阶段知识译码器
第一阶段译码器以多模态语义元素为输入,集中于怎样根据上下文去生成响应;第二阶段译码器将第一阶段的译码结果和相关领域知识作为输入,集中于增加知识使用并且引导接下来的对话。当生成第i个单词 u ~ i r \tilde{u}_i^r u~ir时,我们已经生成了之前的单词 u ~ < i r \tilde{u}_{
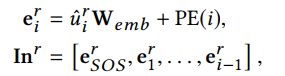
其中 e S O S r e_{SOS}^r eSOSr是句子开头的单词表征。
对于第一阶段译码器,是与原先的transformer译码器相同的:

对于第二阶段译码器,有两种相关领域知识:风格建议和名人偏好。例如(T-shirts, sandals)作为一个风格建议的例子,我们将T-shirts和sandals分别编码为两个向量然后连接他们获取知识条目。因此我们可以得到一个风格建议的矩阵 S T ∈ R N s × d k n g ST \in R{N_s×d_{kng}} ST∈RNs×dkng,其中 N s N_s Ns是风格建议数目, d k n g d_{kng} dkng是知识编码长度。对于名人偏好我们也做差不多的事情。 C P ∈ R N c × d k n g CP \in R^{N_c×d_{kng}} CP∈RNc×dkng表示名人偏好条目。最终连接ST和CP后得到 D K ∈ R ( N s + N c ) × d k n g DK \in R^{(N_s+N_c)×d_{kng}} DK∈R(Ns+Nc)×dkng。第二阶段的生成结果为

模型训练
分别计算两个译码器的损失函数,综合后为整体的损失函数
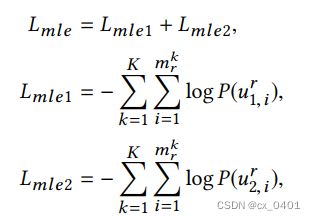
实验
数据集
MMD:多模态对话数据集(零售领域),对话中顾客提出需求,代理人介绍不同的产品直交易达成。
基于这个数据集,Saha提出过两种主要的任务:分别是根据特定K轮的对话给出下一次回答,给定内容给数据库中m个图片排序。
实验步骤
词汇表大小:26422
单词表征维度:512
编码器和译码器的层数:3
注意力头数:8
内层大小:2048
剪枝率:0.1
Adam优化,初始学习率:0.00001
对比方法
Seq2seq:用全局注意力机制的经典编码器-译码器结构
HRED:由一个单词级别的LSTM和一个句子级别的LSTM连接成的语义表征
MHERD:将视觉特征融入HRED模型中
UMD:基于MHERD,用户注意力引导多模态对话系统考虑了层级产品分类和用户在产品上的注意力
OAM:一种新颖的基于序列和属性感知注意力机制的自然语言生成机制(利用图像和文本)
MAGIC:可适应译码器的多模态对话系统明确地利用用户注意力去生成普遍的应答、知识感知的回答和动态多模态应答。(最强baseline)
评估指标
- 自动评测:BLEU-N和NIST做诶评测指标
- 人为评估:三个专家从流利度、内容一致性、知识相关性三个方面评估
- 最终平均地从两个方面考虑
实验结果

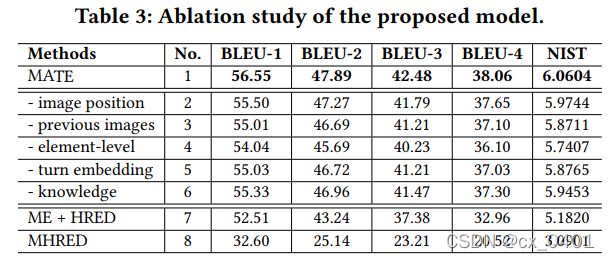
消融实验
- 对话图片库的作用:
模型1:正常MATE
模型2:去除image position
模型3:去除图像库
模型4:用GRU去编码每个图片增强的文本表征,丢弃查询增强的图像表征,将GRU的最终隐藏层连接在一起放到译码器,通过这种方式使得译码器只接收语义层次的信息(就像MHRED)
模型5:去除轮次表征
模型6:移除第二阶段译码器
模型7:将MHRED中的低层次的编码器替换成我们的多模态编码器