深度学习实战13(进阶版)-文本纠错功能,经常写错别字的小伙伴的福星
大家好,我是微学AI,我们在日常生活中,经常会写一些文稿,比如:会议纪要,周报,日报,汇报材料,这些文稿里我们会发现有时候出现拼写、语法、标点等错误;其中拼写错误的错别字占大部分。
经过初步统计:在微博等新媒体领域中,文本敏感和出错概率在2%左右;怎样才能快速解决这个错误问题呢,让机器帮我们找错别字,因为有时候自己写的文章,比较不容易找出错误,如果找出来需要反复通读全文,这也是很费时的一件事情。
下面我们要用NLP中的文本纠错功能来初步解决这个问题,文本纠错作为自然语言处理最基础的模块,是实现中文语句自动检查、自动纠错的一项重要的自然语言处理技术。
1. 文本纠错模型介绍
文本纠错任务是一项NLP基础任务,我们输入是一个可能含有错别字的中文句子,输出是一个纠正错别字后的中文句子。文本纠错任务也可以纠正语法错误类型的句子,包括有多字、少字等,目前最常见的错误类型是`错别字`。目前主要对错别字这一类型进行研究。
下面我用多个模型实现文本纠错:
模型1:pycorrector 基础
安装方式:pip install pycorrector
import sys
sys.path.append("..")
import pycorrector
if __name__ == '__main__':
error_sentences = [
'他是有明的侦探',
'这场比赛我甘败下风',
'这家伙还蛮格尽职守的',
'报应接中迩来',
'今天我很高形',
'少先队员因该为老人让坐',
'老是在较书。'
]
for line in error_sentences:
correct_sent, err = pycorrector.correct(line)
print("{} => {} {}".format(line, correct_sent, err))运行结果:
他是有明的侦探 => 他是有名的侦探 [('有明', '有名', 2, 4)]
这场比赛我甘败下风 => 这场比赛我甘拜下风 [('甘败下风', '甘拜下风', 5, 9)]
这家伙还蛮格尽职守的 => 这家伙还蛮恪尽职守的 [('蛮格', '蛮恪', 4, 6), ('格尽职守', '恪尽职守', 5, 9)]
报应接中迩来 => 报应接踵而来 [('接中迩来', '接踵而来', 2, 6)]
今天我很高形 => 今天我很高兴 [('高形', '高兴', 4, 6)]
少先队员因该为老人让坐 => 少先队员应该为老人让座 [('因该', '应该', 4, 6), ('坐', '座', 10, 11)]
老是在较书。 => 老师在较书。 [('老是', '老师', 0, 2)]我们看到这些错别字大部分被准确地找出,有些还是没有找出,对于其他样本测试,效果还不一定。
模型2:macbert4csc
import gradio as gr
import operator
import torch
from transformers import BertTokenizer, BertForMaskedLM
tokenizer = BertTokenizer.from_pretrained("shibing624/macbert4csc-base-chinese")
model = BertForMaskedLM.from_pretrained("shibing624/macbert4csc-base-chinese")
def ai_text(text):
with torch.no_grad():
outputs = model(**tokenizer([text], padding=True, return_tensors='pt'))
def to_highlight(corrected_sent, errs):
output = [{"entity": "纠错", "word": err[1], "start": err[2], "end": err[3]} for i, err in
enumerate(errs)]
return {"text": corrected_sent, "entities": output}
def get_errors(corrected_text, origin_text):
sub_details = []
for i, ori_char in enumerate(origin_text):
if ori_char in [' ', '“', '”', '‘', '’', '琊', '\n', '…', '—', '擤']:
# add unk word
corrected_text = corrected_text[:i] + ori_char + corrected_text[i:]
continue
if i >= len(corrected_text):
continue
if ori_char != corrected_text[i]:
if ori_char.lower() == corrected_text[i]:
# pass english upper char
corrected_text = corrected_text[:i] + ori_char + corrected_text[i + 1:]
continue
sub_details.append((ori_char, corrected_text[i], i, i + 1))
sub_details = sorted(sub_details, key=operator.itemgetter(2))
return corrected_text, sub_details
_text = tokenizer.decode(torch.argmax(outputs.logits[0], dim=-1), skip_special_tokens=True).replace(' ', '')
corrected_text = _text[:len(text)]
corrected_text, details = get_errors(corrected_text, text)
print(text, ' => ', corrected_text, details)
return to_highlight(corrected_text, details), details
if __name__ == '__main__':
print(ai_text('少先队员因该为老人让坐'))
examples = [
['真麻烦你了。希望你们好好的跳无'],
['少先队员因该为老人让坐'],
['他是有明的侦探'],
['今天心情很不搓'],
['他法语说的很好,的语也不错'],
['这场比赛我甘败下风'],
]
gr.Interface(
ai_text,
inputs="textbox",
outputs=[
gr.outputs.HighlightedText(
label="Output",
show_legend=True,
),
gr.outputs.JSON(
label="JSON Output"
)
],
title="中文纠错模型",
description="输入一段话,判断这段话中是否有错别字或语法错误",
article="Link to Github REPO",
examples=examples
).launch()运行后,可以启动可视化网页 http://127.0.0.1:7860
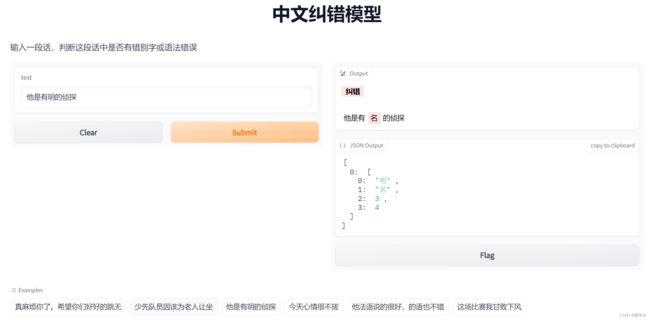
模型3:MacBertCorrector
# -*- coding: utf-8 -*-
import sys
sys.path.append("..")
from pycorrector.macbert.macbert_corrector import MacBertCorrector
def use_origin_transformers():
# 原生transformers库调用
import operator
import torch
from transformers import BertTokenizer, BertForMaskedLM
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
tokenizer = BertTokenizer.from_pretrained("shibing624/macbert4csc-base-chinese")
model = BertForMaskedLM.from_pretrained("shibing624/macbert4csc-base-chinese")
model.to(device)
texts = ["今天新情很好", "你找到你最喜欢的工作,我也很高心。", "我不唉“看 琅擤琊榜”"]
text_tokens = tokenizer(texts, padding=True, return_tensors='pt').to(device)
with torch.no_grad():
outputs = model(**text_tokens)
def get_errors(corrected_text, origin_text):
sub_details = []
for i, ori_char in enumerate(origin_text):
if ori_char in [' ', '“', '”', '‘', '’', '\n', '…', '—', '擤']:
# add unk word
corrected_text = corrected_text[:i] + ori_char + corrected_text[i:]
continue
if i >= len(corrected_text):
break
if ori_char != corrected_text[i]:
if ori_char.lower() == corrected_text[i]:
# pass english upper char
corrected_text = corrected_text[:i] + ori_char + corrected_text[i + 1:]
continue
sub_details.append((ori_char, corrected_text[i], i, i + 1))
sub_details = sorted(sub_details, key=operator.itemgetter(2))
return corrected_text, sub_details
result = []
for ids, (i, text) in zip(outputs.logits, enumerate(texts)):
_text = tokenizer.decode((torch.argmax(ids, dim=-1) * text_tokens.attention_mask[i]),
skip_special_tokens=True).replace(' ', '')
corrected_text, details = get_errors(_text, text)
print(text, ' => ', corrected_text, details)
result.append((corrected_text, details))
print(result)
return result
if __name__ == '__main__':
# 原生transformers库调用
use_origin_transformers()
# pycorrector封装调用
error_sentences = [
'他是有明的侦探',
'这场比赛我甘败下风',
'这家伙还蛮格尽职守的',
'报应接中迩来',
'今天我很高形',
'少先队员因该为老人让坐',
'老是在较书。'
]
m = MacBertCorrector()
for line in error_sentences:
correct_sent, err = m.macbert_correct(line)
print("query:{} => {} err:{}".format(line, correct_sent, err))运行结果:
query:他是有明的侦探 => 他是有名的侦探 err:[('明', '名', 3, 4)]
query:这场比赛我甘败下风 => 这场比赛我甘败下风 err:[]
query:这家伙还蛮格尽职守的 => 这家伙还蛮格尽职守的 err:[]
query:报应接中迩来 => 报应接中迩来 err:[]
query:今天我很高形 => 今天我很高兴 err:[('形', '兴', 5, 6)]
query:少先队员因该为老人让坐 => 少先队员应该为老人让坐 err:[('因', '应', 4, 5)]
query:老是在较书。 => 老师在教书。 err:[('是', '师', 1, 2), ('较', '教', 3, 4)]
模型4:T5Corrector
import sys
sys.path.append("..")
from pycorrector.t5.t5_corrector import T5Corrector
if __name__ == '__main__':
# pycorrector封装调用
error_sentences = [
'他是有明的侦探',
'这场比赛我甘败下风',
'这家伙还蛮格尽职守的',
'报应接中迩来',
'今天我很高形',
'少先队员因该为老人让坐',
'老是在较书。'
]
m = T5Corrector()
res = m.batch_t5_correct(error_sentences)
for line, r in zip(error_sentences, res):
correct_sent, err = r[0], r[1]
print("query:{} => {} err:{}".format(line, correct_sent, err))运行结果:
query:他是有明的侦探 => 他是有名的侦探 err:[('明', '名', 3, 4)]
query:这场比赛我甘败下风 => 这场比赛我甘败下风 err:[]
query:这家伙还蛮格尽职守的 => 这家伙还蛮格尽职守的 err:[]
query:报应接中迩来 => 报应接中找来 err:[('迩', '找', 4, 5)]
query:今天我很高形 => 今天我很高 err:[]
query:少先队员因该为老人让坐 => 少先队员应该为老人让坐 err:[('因', '应', 4, 5)]
query:老是在较书。 => 老师在教书。 err:[('是', '师', 1, 2), ('较', '教', 3, 4)]各个模型表现不一,大家可以根据需求选定想要的模型。有问题私信,答疑。